Конфигурация двигателя¶
Engine является отправной точкой для любого приложения SQLAlchemy. Это «домашняя база» для реальной базы данных и ее DBAPI, доставляемой приложению SQLAlchemy через пул соединений и Dialect, который описывает, как общаться с определенным видом базы данных/комбинацией DBAPI.
Общая структура может быть проиллюстрирована следующим образом:
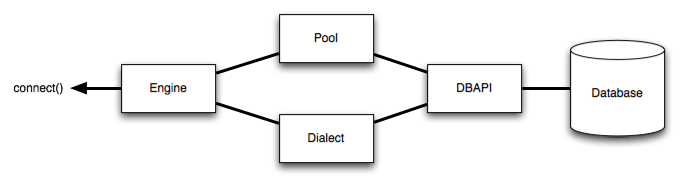
Там, где указано выше, Engine ссылается на Dialect и Pool, которые вместе интерпретируют функции модуля DBAPI, а также поведение базы данных.
Создание двигателя сводится к выполнению одного вызова create_engine():
from sqlalchemy import create_engine
engine = create_engine("postgresql://scott:tiger@localhost:5432/mydatabase")Приведенный выше механизм создает объект Dialect, предназначенный для PostgreSQL, а также объект Pool, который будет устанавливать DBAPI-соединение в localhost:5432 при первом получении запроса на соединение. Обратите внимание, что Engine и лежащий в его основе Pool не устанавливают первое фактическое DBAPI-соединение, пока не будет вызван метод Engine.connect() или не будет вызвана операция, зависящая от этого метода, такая как Engine.execute(). Таким образом, можно сказать, что Engine и Pool имеют поведение ленивой инициализации.
Созданный Engine может либо использоваться непосредственно для взаимодействия с базой данных, либо передаваться объекту Session для работы с ORM. В этом разделе рассматриваются детали конфигурирования Engine. В следующем разделе, Работа с двигателями и соединениями, будет подробно описано использование API Engine и подобных ему, обычно для приложений, не относящихся к ОРМ.
Поддерживаемые базы данных¶
SQLAlchemy включает множество Dialect реализаций для различных бэкендов. Диалекты для наиболее распространенных баз данных включены в SQLAlchemy; для некоторых других требуется дополнительная установка отдельного диалекта.
Информацию о различных доступных бэкендах см. в разделе Диалекты.
URL-адреса баз данных¶
Функция create_engine() создает объект Engine на основе URL. Формат URL обычно соответствует формату RFC-1738, с некоторыми исключениями, включая то, что в части «схема» принимаются подчеркивания, а не тире или периоды. URL обычно включает поля имени пользователя, пароля, имени хоста, имени базы данных, а также необязательные аргументы в виде ключевых слов для дополнительной настройки. В некоторых случаях принимается путь к файлу, а в других «имя источника данных» заменяет части «хост» и «база данных». Типичная форма URL базы данных выглядит следующим образом:
dialect+driver://username:password@host:port/databaseИмена диалектов включают идентифицирующее имя диалекта SQLAlchemy, такое имя, как sqlite, mysql, postgresql, oracle или mssql. Имя драйвера - это имя DBAPI, которое будет использоваться для подключения к базе данных, с использованием всех строчных букв. Если оно не указано, будет импортирован DBAPI «по умолчанию», если он доступен - по умолчанию обычно используется наиболее известный драйвер, доступный для данного бэкенда.
Исключение специальных символов, таких как знаки @ в паролях¶
Поскольку URL-адрес похож на любой другой URL-адрес, специальные символы, такие как те, которые могут использоваться в пользователе и пароле, должны быть закодированы в URL-адресе для корректного разбора.. Это включает знак @.
Ниже приведен пример URL, который включает пароль "kx@jj5/g", где знак «at» и символы косой черты представлены как %40 и %2F соответственно:
postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdbКодировка для приведенного выше пароля может быть сгенерирована с помощью urllib.parse:
>>> import urllib.parse
>>> urllib.parse.quote_plus("kx@jj5/g")
'kx%40jj5%2Fg'Изменено в версии 1.4: Исправлена поддержка знаков @ в именах хостов и базах данных. Как побочный эффект этого исправления, знаки @ в паролях должны быть экранированы.
URL-адреса, специфичные для бэкенда¶
Примеры распространенных стилей соединения приведены ниже. Полный указатель с подробной информацией обо всех включенных диалектах, а также ссылки на сторонние диалекты см. в разделе Диалекты.
PostgreSQL¶
Диалект PostgreSQL использует psycopg2 в качестве DBAPI по умолчанию. Другие интерфейсы DBAPI PostgreSQL включают pg8000 и asyncpg:
# default
engine = create_engine("postgresql://scott:tiger@localhost/mydatabase")
# psycopg2
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/mydatabase")
# pg8000
engine = create_engine("postgresql+pg8000://scott:tiger@localhost/mydatabase")Более подробная информация о подключении к PostgreSQL на сайте PostgreSQL.
MySQL¶
Диалект MySQL использует mysqlclient в качестве DBAPI по умолчанию. Существуют и другие DBAPI для MySQL, включая PyMySQL:
# default
engine = create_engine("mysql://scott:tiger@localhost/foo")
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine("mysql+mysqldb://scott:tiger@localhost/foo")
# PyMySQL
engine = create_engine("mysql+pymysql://scott:tiger@localhost/foo")Более подробная информация о подключении к MySQL на сайте MySQL и MariaDB.
Oracle¶
Диалект Oracle использует cx_oracle в качестве DBAPI по умолчанию:
engine = create_engine("oracle://scott:tiger@127.0.0.1:1521/sidname")
engine = create_engine("oracle+cx_oracle://scott:tiger@tnsname")Дополнительные сведения о подключении к Oracle можно найти на сайте Oracle.
Microsoft SQL Server¶
Диалект SQL Server использует pyodbc в качестве DBAPI по умолчанию. Также доступен pymssql:
# pyodbc
engine = create_engine("mssql+pyodbc://scott:tiger@mydsn")
# pymssql
engine = create_engine("mssql+pymssql://scott:tiger@hostname:port/dbname")Дополнительные сведения о подключении к SQL Server можно найти на сайте Microsoft SQL Server.
SQLite¶
SQLite подключается к базам данных на основе файлов, используя по умолчанию встроенный модуль Python sqlite3.
Поскольку SQLite подключается к локальным файлам, формат URL немного отличается. Часть URL «file» - это имя файла базы данных. Для относительного пути к файлу требуется три косых черты:
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine("sqlite:///foo.db")А для абсолютного пути к файлу за тремя косыми чертами следует абсолютный путь:
# Unix/Mac - 4 initial slashes in total
engine = create_engine("sqlite:////absolute/path/to/foo.db")
# Windows
engine = create_engine("sqlite:///C:\\path\\to\\foo.db")
# Windows alternative using raw string
engine = create_engine(r"sqlite:///C:\path\to\foo.db")Чтобы использовать базу данных SQLite :memory:, укажите пустой URL:
engine = create_engine("sqlite://")Дополнительные заметки о подключении к SQLite на SQLite.
Другие¶
Смотрите Диалекты, страницу верхнего уровня для всей дополнительной документации по диалектам.
API создания двигателя¶
Объединение¶
Engine будет запрашивать у пула соединений соединение, когда будут вызваны методы connect() или execute(). Пул соединений по умолчанию, QueuePool, будет открывать соединения с базой данных по мере необходимости. По мере выполнения параллельных операторов, QueuePool будет увеличивать свой пул соединений до размера по умолчанию в пять, и допускать «переполнение» по умолчанию в десять. Поскольку Engine является по сути «домашней базой» для пула соединений, из этого следует, что вы должны держать один Engine на базу данных, установленную в приложении, а не создавать новый для каждого соединения.
Примечание
QueuePool не используется по умолчанию для движков SQLite. Подробнее об использовании пула соединений SQLite смотрите SQLite.
Для получения дополнительной информации о пуле соединений смотрите Объединение соединений.
Пользовательские аргументы DBAPI connect() / процедуры включения соединения¶
Для случаев, когда требуются специальные методы соединения, в подавляющем большинстве случаев наиболее целесообразно использовать один из нескольких крючков на уровне create_engine(), чтобы настроить этот процесс. Они описаны в следующих подразделах.
Специальные ключевые аргументы, передаваемые в dbapi.connect()¶
Все Python DBAPI принимают дополнительные аргументы, выходящие за рамки основных параметров подключения. К обычным параметрам относятся параметры для задания кодировок наборов символов и значений тайм-аута; более сложные данные включают специальные константы и объекты DBAPI и подпараметры SSL. Существует два элементарных способа передачи этих аргументов без усложнения.
Добавление параметров в строку запроса URL¶
Простые строковые значения, а также некоторые числовые значения и булевы флаги часто могут быть указаны в строке запроса URL напрямую. Частым примером этого являются DBAPI, которые принимают аргумент encoding для кодировок символов, например, большинство MySQL DBAPI:
engine = create_engine("mysql+pymysql://user:pass@host/test?charset=utf8mb4")Преимущество использования строки запроса заключается в том, что дополнительные параметры DBAPI могут быть указаны в конфигурационных файлах способом, переносимым на DBAPI, указанный в URL. Конкретные параметры, передаваемые на этом уровне, зависят от диалекта SQLAlchemy. Некоторые диалекты передают все аргументы в виде строк, другие анализируют определенные типы данных и перемещают параметры в различные места, например, в DSN на уровне драйвера и строки подключения. Поскольку в настоящее время поведение в этой области зависит от диалекта, следует обратиться к документации по конкретному используемому диалекту, чтобы узнать, поддерживаются ли определенные параметры на этом уровне.
Совет
Общая техника отображения точных аргументов, переданных DBAPI для данного URL, может быть выполнена с помощью метода Dialect.create_connect_args() непосредственно следующим образом:
>>> from sqlalchemy import create_engine
>>> engine = create_engine(
... "mysql+pymysql://some_user:some_pass@some_host/test?charset=utf8mb4"
... )
>>> args, kwargs = engine.dialect.create_connect_args(engine.url)
>>> args, kwargs
([], {'host': 'some_host', 'database': 'test', 'user': 'some_user', 'password': 'some_pass', 'charset': 'utf8mb4', 'client_flag': 2})Приведенная выше пара args, kwargs обычно передается в DBAPI как dbapi.connect(*args, **kwargs).
Используйте параметр словаря connect_args¶
Более общей системой передачи любого параметра в функцию dbapi.connect(), которая гарантированно передает все параметры в любое время, является параметр словаря create_engine.connect_args. Он может использоваться для параметров, которые иначе не обрабатываются диалектом при добавлении в строку запроса, а также в случаях, когда в DBAPI необходимо передать специальные подструктуры или объекты. Иногда бывает, что определенный флаг должен быть отправлен в виде символа True, а диалект SQLAlchemy не знает об этом ключевом аргументе, чтобы вырвать его из строковой формы, представленной в URL. Ниже показано использование «фабрики соединений» psycopg2, которая заменяет базовую реализацию connection:
engine = create_engine(
"postgresql://user:pass@hostname/dbname",
connect_args={"connection_factory": MyConnectionFactory},
)Другим примером является параметр pyodbc «timeout»:
engine = create_engine(
"mssql+pyodbc://user:pass@sqlsrvr?driver=ODBC+Driver+13+for+SQL+Server",
connect_args={"timeout": 30},
)Приведенный выше пример также иллюстрирует, что одновременно могут использоваться как параметры «строки запроса» URL, так и create_engine.connect_args; в случае с pyodbc ключевое слово «driver» имеет особое значение в URL.
Управление передачей параметров в функцию DBAPI connect()¶
Помимо манипулирования параметрами, передаваемыми в connect(), мы можем дополнительно настроить вызов самой функции DBAPI connect() с помощью крючка событий DialectEvents.do_connect(). Этому крючку передается полный *args, **kwargs, который диалект будет посылать в connect(). Затем эти коллекции могут быть изменены на месте, чтобы изменить способ их использования:
from sqlalchemy import event
engine = create_engine("postgresql://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
cparams["connection_factory"] = MyConnectionFactoryГенерация динамических маркеров аутентификации¶
DialectEvents.do_connect() также является идеальным способом динамической вставки маркера аутентификации, который может меняться в течение жизни Engine. Например, если маркер генерируется get_authentication_token() и передается в DBAPI в параметре token, это можно реализовать следующим образом:
from sqlalchemy import event
engine = create_engine("postgresql://user@hostname/dbname")
@event.listens_for(engine, "do_connect")
def provide_token(dialect, conn_rec, cargs, cparams):
cparams["token"] = get_authentication_token()См.также
mssql_pyodbc_access_tokens - более конкретный пример с участием SQL Server
Изменение соединения DBAPI после подключения или выполнение команд после подключения¶
Для DBAPI-соединения, которое SQLAlchemy создает без проблем, но когда мы хотим изменить созданное соединение до его использования, например, для установки специальных флагов или выполнения определенных команд, наиболее подходящим является хук событий PoolEvents.connect(). Этот хук вызывается для каждого нового созданного соединения, прежде чем оно будет использовано SQLAlchemy:
from sqlalchemy import event
engine = create_engine("postgresql://user:pass@hostname/dbname")
@event.listens_for(engine, "connect")
def connect(dbapi_connection, connection_record):
cursor_obj = dbapi_connection.cursor()
cursor_obj.execute("SET some session variables")
cursor_obj.close()Полная замена функции DBAPI connect()¶
Наконец, крючок события DialectEvents.do_connect() может также позволить нам полностью взять на себя процесс соединения, устанавливая соединение и возвращая его:
from sqlalchemy import event
engine = create_engine("postgresql://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
# return the new DBAPI connection with whatever we'd like to
# do
return psycopg2.connect(*cargs, **cparams)Хук DialectEvents.do_connect() заменяет предыдущий хук create_engine.creator, который остается доступным. Преимущество DialectEvents.do_connect() заключается в том, что все аргументы, разобранные из URL, также передаются в пользовательскую функцию, чего нельзя сказать о create_engine.creator.
Настройка ведения журнала¶
Стандартный модуль Python logging используется для реализации вывода информационных и отладочных журналов в SQLAlchemy. Это позволяет журналу SQLAlchemy интегрироваться стандартным образом с другими приложениями и библиотеками. Также в модуле create_engine.echo присутствуют два параметра create_engine.echo_pool и create_engine(), которые позволяют немедленно записывать логи в sys.stdout для целей локальной разработки; эти параметры в конечном итоге взаимодействуют с обычными логгерами Python, описанными ниже.
Этот раздел предполагает знакомство с вышеупомянутым модулем протоколирования. Все логи, выполняемые SQLAlchemy, существуют в пространстве имен sqlalchemy, используемом модулем logging.getLogger('sqlalchemy'). Когда логирование настроено (например, через logging.basicConfig()), общее пространство имен SA-логгеров, которые могут быть включены, выглядит следующим образом:
sqlalchemy.engine- управляет эхом SQL. Установите значениеlogging.INFOдля вывода SQL-запроса,logging.DEBUGдля вывода запроса + набора результатов. Эти настройки эквивалентныecho=Trueиecho="debug"наcreate_engine.echoсоответственно.sqlalchemy.pool- управляет протоколированием пула соединений. Установите значениеlogging.INFO, чтобы регистрировать события аннулирования и восстановления соединения; установите значениеlogging.DEBUG, чтобы дополнительно регистрировать все регистрации и выгрузки пула. Эти настройки эквивалентныpool_echo=Trueиpool_echo="debug"наcreate_engine.echo_poolсоответственно.sqlalchemy.dialects- управляет пользовательским протоколированием для диалектов SQL, в той степени, в которой протоколирование используется в конкретных диалектах, что обычно минимально.sqlalchemy.orm- управляет протоколированием различных функций ORM в той степени, в которой протоколирование используется внутри ORM, что обычно минимально. Установите значениеlogging.INFOдля записи в журнал некоторой информации верхнего уровня о конфигурациях маппера.
Например, для регистрации SQL-запросов с использованием Python logging вместо флага echo=True:
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)По умолчанию уровень журнала установлен на logging.WARN во всем пространстве имен sqlalchemy, так что никаких операций с журналом не происходит, даже в приложении, в котором журнал включен.
Примечание
SQLAlchemy Engine экономит накладные расходы на вызов функций Python, выдавая отчеты журнала только тогда, когда текущий уровень регистрации определяется как logging.INFO или logging.DEBUG. Он проверяет этот уровень только при получении нового соединения из пула соединений. Поэтому при изменении конфигурации протоколирования для уже работающего приложения, любой активный в данный момент Connection или, что более распространено, активный в транзакции объект Session не будет протоколировать SQL в соответствии с новой конфигурацией, пока не будет получено новое Connection (в случае Session это происходит после завершения текущей транзакции и начала новой).
Подробнее о Флаг Эхо¶
Как упоминалось ранее, параметры create_engine.echo и create_engine.echo_pool являются ярлыком для немедленной записи в журнал sys.stdout:
>>> from sqlalchemy import create_engine, text
>>> e = create_engine("sqlite://", echo=True, echo_pool="debug")
>>> with e.connect() as conn:
... print(conn.scalar(text("select 'hi'")))
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Created new connection <sqlite3.Connection object at 0x7f287819ac60>
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> checked out from pool
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine select 'hi'
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine ()
hi
2020-10-24 12:54:57,703 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> being returned to pool
2020-10-24 12:54:57,704 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> rollback-on-returnИспользование этих флагов примерно эквивалентно:
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)
logging.getLogger("sqlalchemy.pool").setLevel(logging.DEBUG)Важно отметить, что эти два флага работают независимо от любой существующей конфигурации логирования, и будут использовать logging.basicConfig() безоговорочно. Это имеет эффект настройки в дополнение к любым существующим конфигурациям логгеров. Поэтому при явной настройке логирования убедитесь, что все флаги echo всегда установлены в False, чтобы избежать дублирования строк журнала.
Настройка имени регистрации¶
Имя регистратора экземпляра, такого как Engine или Pool, по умолчанию использует усеченную строку шестнадцатеричного идентификатора. Чтобы задать конкретное имя, используйте create_engine.logging_name и create_engine.pool_logging_name с sqlalchemy.create_engine():
>>> from sqlalchemy import create_engine
>>> from sqlalchemy import text
>>> e = create_engine("sqlite://", echo=True, logging_name="myengine")
>>> with e.connect() as conn:
... conn.execute(text("select 'hi'"))
2020-10-24 12:47:04,291 INFO sqlalchemy.engine.Engine.myengine select 'hi'
2020-10-24 12:47:04,292 INFO sqlalchemy.engine.Engine.myengine ()Настройка токенов для каждого соединения / суб-инженера¶
Добавлено в версии 1.4.0b2.
Хотя имя регистрации целесообразно устанавливать на объект Engine, который долго живет, оно недостаточно гибко, чтобы приспособить произвольно большой список имен для случая отслеживания отдельных соединений и/или транзакций в сообщениях журнала.
Для этого случая само сообщение журнала, генерируемое объектами Connection и Result, может быть дополнено дополнительными маркерами, такими как идентификаторы транзакций или запросов. Параметр Connection.execution_options.logging_token принимает строковый аргумент, который может быть использован для установки маркеров отслеживания каждого соединения:
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> with e.connect().execution_options(logging_token="track1") as conn:
... conn.execute("select 1").all()
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:48:45,754 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:48:45,755 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)Параметр Connection.execution_options.logging_token также может быть установлен на движки или поддвижки через create_engine.execution_options или Engine.execution_options(). Это может быть полезно для применения различных маркеров протоколирования к различным компонентам приложения без создания новых двигателей:
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> e1 = e.execution_options(logging_token="track1")
>>> e2 = e.execution_options(logging_token="track2")
>>> with e1.connect() as conn:
... conn.execute("select 1").all()
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:51:08,960 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:51:08,961 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)
>>> with e2.connect() as conn:
... conn.execute("select 2").all()
2021-02-03 11:52:05,518 INFO sqlalchemy.engine.Engine [track2] Select 1
2021-02-03 11:52:05,519 INFO sqlalchemy.engine.Engine [track2] [raw sql] ()
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Col ('1',)
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Row (1,)Скрытие параметров¶
Журнал, создаваемый Engine, также показывает выдержку из параметров SQL, которые присутствуют для конкретного оператора. Чтобы предотвратить регистрацию этих параметров в целях конфиденциальности, включите флаг create_engine.hide_parameters:
>>> e = create_engine("sqlite://", echo=True, hide_parameters=True)
>>> with e.connect() as conn:
... conn.execute(text("select :some_private_name"), {"some_private_name": "pii"})
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine select ?
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine [SQL parameters hidden due to hide_parameters=True]