Рефакторинг приложений на Python для упрощения
Оглавление
Хотите получить более простой код на Python? Вы всегда начинаете проект с самыми лучшими намерениями, чистой кодовой базой и хорошей структурой. Но со временем в ваших приложениях происходят изменения, и все может стать немного запутанным.
Если вы умеете писать и поддерживать чистый, простой код на Python, то это сэкономит вам много времени в долгосрочной перспективе. Вы сможете тратить меньше времени на тестирование, поиск ошибок и внесение изменений, когда ваш код хорошо изложен и прост в исполнении.
В этом уроке вы узнаете:
- Как измерить сложность кода Python и ваших приложений
- Как изменять код, не ломая его
- Какие распространенные проблемы в коде Python вызывают дополнительную сложность и как их можно исправить
На протяжении всего этого урока я буду использовать тему подземных железнодорожных сетей для объяснения сложности, потому что навигация по системе метро в большом городе может быть сложной! Некоторые из них хорошо продуманы, а другие кажутся чрезмерно сложными.
Сложность кода в Python
Сложность приложения и его кодовой базы зависит от задачи, которую оно выполняет. Если вы пишете код для лаборатории реактивного движения NASA (буквально наука о ракетах), то он будет сложным.
Вопрос не столько в том, "сложен ли мой код?", сколько в том, "не сложнее ли мой код, чем нужно?"
Токийская железнодорожная сеть - одна из самых обширных и сложных в мире. Отчасти это объясняется тем, что Токио - мегаполис с населением более 30 миллионов человек, но также и тем, что здесь существует 3 сети, которые накладываются друг на друга.
Автор этой статьи заблудился в токийском метро
Через центральный Токио проходят сети скоростного транспорта Toei и Tokyo Metro, а также поезда Japan Rail East. Даже для самого опытного путешественника навигация по центральному Токио может оказаться умопомрачительно сложной.
Вот карта железнодорожной сети Токио, чтобы дать вам некоторое представление:
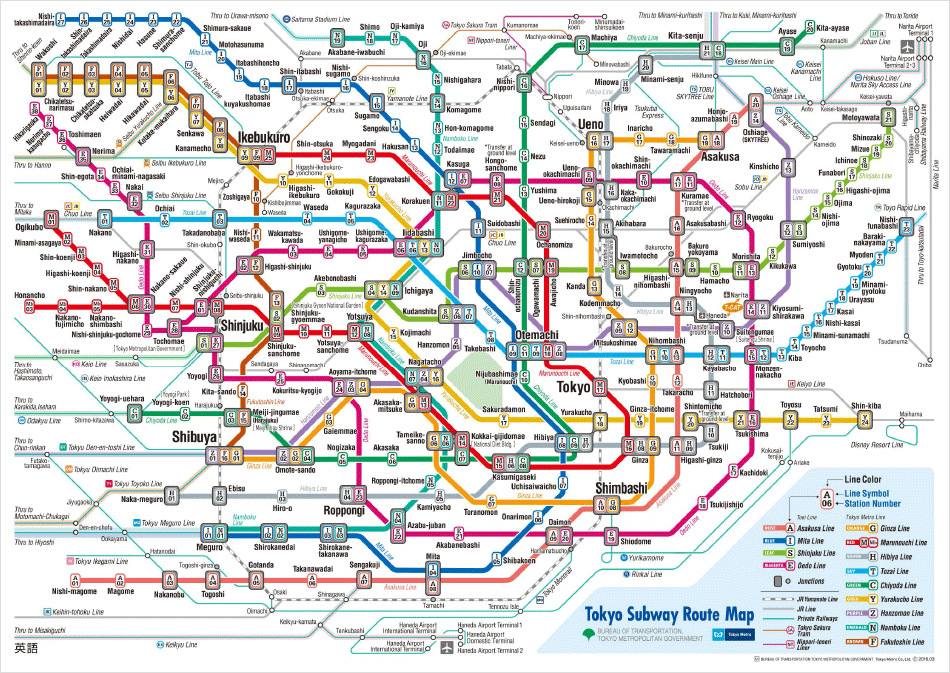 Изображение: Tokyo Metro Co.
Изображение: Tokyo Metro Co.
Если ваш код начинает выглядеть примерно так же, как эта карта, то это руководство для вас.
Сначала мы рассмотрим 4 метрики сложности, которые могут дать вам шкалу для измерения вашего относительного прогресса в миссии по упрощению вашего кода:
После изучения метрик вы узнаете об инструменте под названием wily для автоматизации расчета этих показателей.
Метрики для измерения сложности
Много времени и исследований было потрачено на анализ сложности компьютерного программного обеспечения. Чрезмерно сложные и не поддерживаемые приложения могут иметь вполне реальную цену.
Сложность программного обеспечения коррелирует с его качеством. Код, который легко читать и понимать, с большей вероятностью будет обновляться разработчиками в будущем.
Вот некоторые метрики для языков программирования. Они применимы ко многим языкам, не только к Python.
Строки кода
LOC, или Lines of Code, - самый грубый показатель сложности. Спорно, есть ли прямая корреляция между количеством строк кода и сложностью приложения, но косвенная корреляция очевидна. В конце концов, программа с 5 строками, скорее всего, проще, чем с 5 миллионами.
При просмотре метрик Python мы стараемся игнорировать пустые строки и строки, содержащие комментарии.
Строки кода можно вычислить с помощью команды wc в Linux и Mac OS, где file.py - имя файла, который вы хотите измерить:
$ wc -l file.py
Если вы хотите добавить объединенные строки в папку путем рекурсивного поиска по всем .py файлам, вы можете объединить wc с find командой:
$ find . -name \*.py | xargs wc -l
Для Windows PowerShell предлагает команду подсчета слов в Measure-Object и рекурсивный поиск файлов в Get-ChildItem:
PS C:\> Get-ChildItem -Path *.py -Recurse | Measure-Object –Line
В ответе вы увидите общее количество строк.
Почему строки кода используются для количественной оценки объема кода в вашем приложении? Предполагается, что строка кода примерно равна высказыванию. Строки - это лучший показатель, чем символы, которые включают пробельные символы.
В Python рекомендуется размещать в каждой строке по одному оператору. Этот пример состоит из 9 строк кода:
1x = 5
2value = input("Enter a number: ")
3y = int(value)
4if x < y:
5 print(f"{x} is less than {y}")
6elif x == y:
7 print(f"{x} is equal to {y}")
8else:
9 print(f"{x} is more than {y}")
Если в качестве меры сложности использовать только строки кода, это может способствовать неправильному поведению.
Код на языке Python должен быть легко читаем и понятен. Если взять последний пример, то количество строк кода можно сократить до 3:
1x = 5; y = int(input("Enter a number:"))
2equality = "is equal to" if x == y else "is less than" if x < y else "is more than"
3print(f"{x} {equality} {y}")
Но результат трудно читать, а в PEP 8 есть рекомендации по максимальной длине строк и их разрыву. Подробнее о PEP 8 вы можете прочитать в статье How to Write Beautiful Python Code With PEP 8.
В этом блоке кода используются 2 особенности языка Python, чтобы сделать код короче:
- Сложные утверждения: с использованием
; - Цепочки условных или троичных утверждений:
name = value if condition else value if condition2 else value2
Мы сократили количество строк кода, но нарушили один из фундаментальных законов Python:
"Читабельность имеет значение"
- Тим Питерс, Zen of Python
Этот укороченный код потенциально сложнее поддерживать, потому что сопровождающие кода - люди, и этот короткий код сложнее читать. Мы рассмотрим некоторые более продвинутые и полезные метрики сложности.
Цикломатическая сложность
Цикломатическая сложность - это мера того, сколько независимых путей прохождения кода существует в вашем приложении. Путь - это последовательность утверждений, следуя которой интерпретатор может добраться до конца приложения.
Один из способов думать о цикломатической сложности и путях кода - представить, что ваш код похож на железнодорожную сеть.
Во время путешествия вам может потребоваться пересадка на другой поезд, чтобы добраться до места назначения. Железнодорожная система Лиссабонского метрополитена в Португалии проста и удобна для навигации. Цикломатическая сложность любой поездки равна количеству линий, по которым нужно проехать:
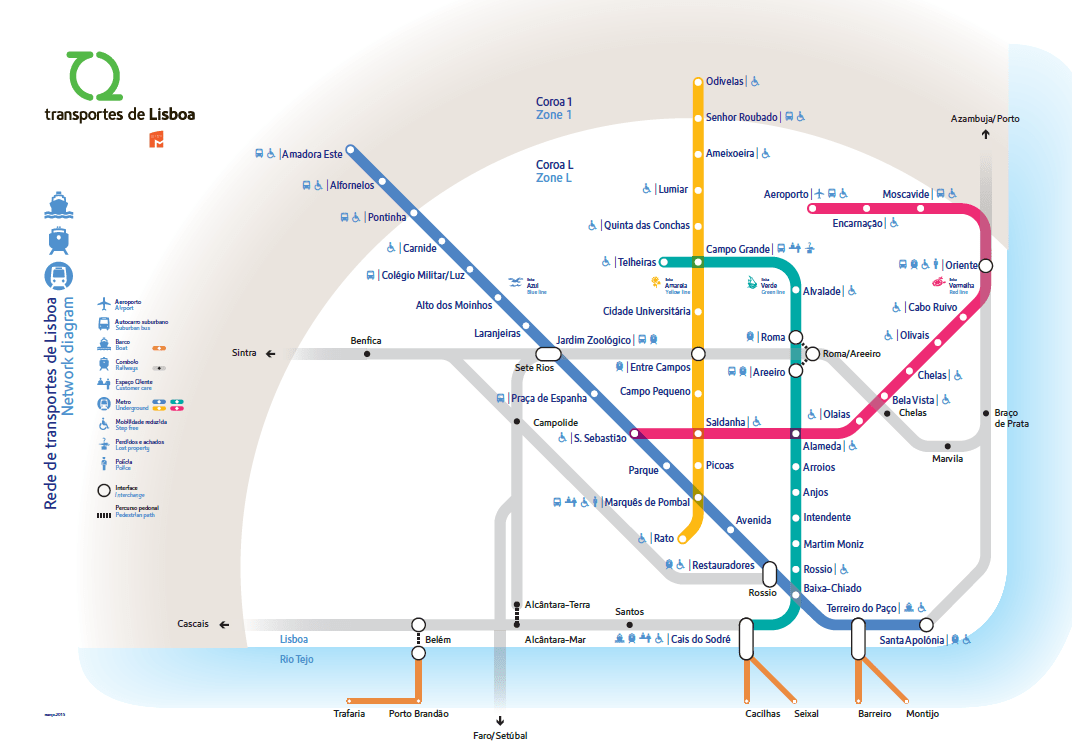 Изображение: Метро Лисбоа
Изображение: Метро Лисбоа
Если вам нужно добраться из Alvalade в Anjos, то вы проедете 5 остановок на linha verde (зеленая линия):
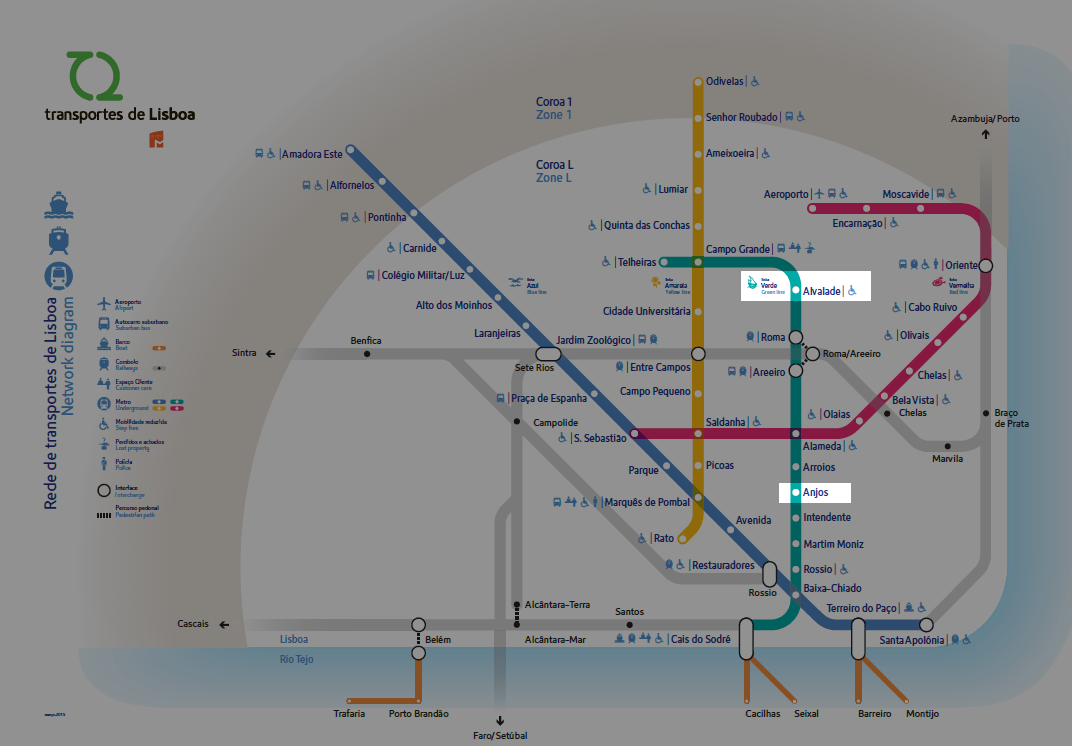 Изображение: Метро Лисбоа
Изображение: Метро Лисбоа
Эта поездка имеет цикломатическую сложность 1, потому что вы едете только на одном поезде. Это легкая поездка. Этот поезд в данной аналогии эквивалентен ветке кода.
Если вам нужно добраться из Aeroporto (аэропорта), чтобы попробовать еду в районе Belém, то это более сложное путешествие. Вам придется делать пересадку на поездах Alameda и Cais do Sodré:
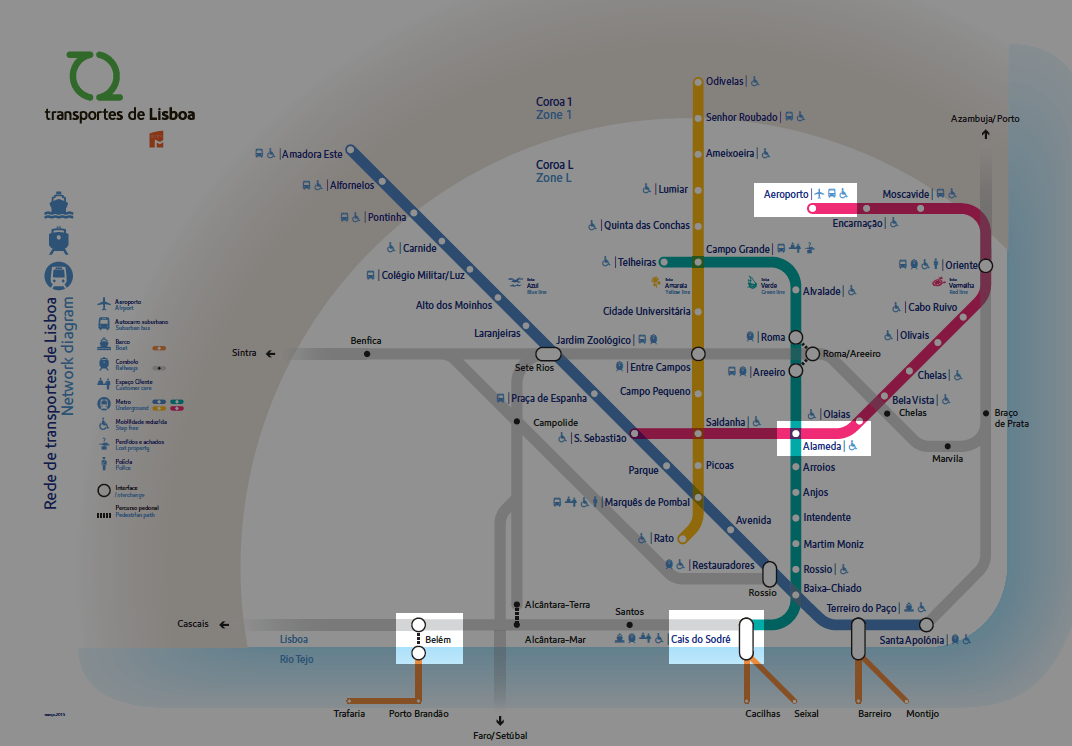 Изображение: Метро Лисбоа
Изображение: Метро Лисбоа
Эта поездка имеет цикломатическую сложность 3, потому что вы едете на 3 поездах. Возможно, вам лучше взять такси!
Поскольку вы не ориентируетесь в Лиссабоне, а пишете код, изменения линии поезда становятся ответвлением в исполнении, как оператор if.
Давайте рассмотрим этот пример:
x = 1
Существует только 1 способ выполнения этого кода, поэтому его цикломатическая сложность равна 1.
Если мы добавляем решение или ветвление в код в виде оператора if, это увеличивает сложность:
x = 1
if x < 2:
x += 1
Несмотря на то, что этот код может быть выполнен только одним способом, поскольку x является константой, его цикломатическая сложность равна 2. Все анализаторы цикломатической сложности будут рассматривать оператор if как ветвление.
Это также пример чрезмерно сложного кода. Оператор if бесполезен, так как x имеет фиксированное значение. Вы можете просто рефакторизовать этот пример следующим образом:
x = 2
Это был игрушечный пример, так что давайте рассмотрим нечто более реальное.
main() имеет цикломатическую сложность 5. Я прокомментирую каждую ветвь в коде, чтобы вы могли видеть, где они находятся:
# cyclomatic_example.py
import sys
def main():
if len(sys.argv) > 1: # 1
filepath = sys.argv[1]
else:
print("Provide a file path")
exit(1)
if filepath: # 2
with open(filepath) as fp: # 3
for line in fp.readlines(): # 4
if line != "\n": # 5
print(line, end="")
if __name__ == "__main__": # Ignored.
main()
Конечно, есть способы рефакторинга кода в гораздо более простую альтернативу. К этому мы вернемся позже.
Примечание: Мера цикломатической сложности была разработана Томасом Дж. Маккейбом-старшим в 1976 году. Вы можете встретить ее как метрику Маккейба или число Маккейба .
В следующих примерах мы будем использовать библиотеку radon из PyPI для вычисления метрик. Вы можете установить ее прямо сейчас:
$ pip install radon
Чтобы рассчитать цикломатическую сложность с помощью radon, вы можете сохранить пример в файл с именем cyclomatic_example.py и использовать radon из командной строки.
Команда radon принимает 2 основных аргумента:
- Тип анализа (
ccдля цикломатической сложности) - Путь к файлу или папке для анализа
Выполните команду radon с анализом cc в отношении файла cyclomatic_example.py. Добавив -s, вы получите на выходе цикломатическую сложность:
$ radon cc cyclomatic_example.py -s
cyclomatic_example.py
F 4:0 main - B (6)
Вывод немного загадочен. Вот что означает каждая часть:
Fозначает функцию,Mозначает метод, аCозначает класс.main- имя функции.4- строка, с которой начинается функция.B- рейтинг от A до F. A - лучший рейтинг, означающий наименьшую сложность.- Число в скобках,
6, - это цикломатическая сложность кода.
Метрики Халстеда
Метрики сложности Халстеда относятся к размеру кодовой базы программы. Они были разработаны Морисом Х. Халстедом в 1977 году. В уравнениях Халстеда есть 4 показателя:
- Операнды - это значения и имена переменных.
- Операторы - это все встроенные ключевые слова, такие как
if,else,forилиwhile. - Длина (N) - это количество операторов плюс количество операндов в вашей программе.
- Словарный запас (h) - это количество уникальных операторов плюс количество уникальных операндов в вашей программе.
Затем есть 3 дополнительные метрики с этими показателями:
- Объем (V) представляет собой произведение длины и словарного запаса.
- Трудность (D) представляет собой произведение половины уникальных операндов и повторного использования операндов.
- Трудоемкость (E) - это общая метрика, которая является произведением объема и сложности.
Все это очень абстрактно, так что давайте выразим это в относительных терминах:
- Трудоемкость вашего приложения будет выше, если вы используете много операторов и уникальные операнды.
- Трудоемкость вашего приложения ниже, если вы используете несколько операторов и меньшее количество переменных.
В примере cyclomatic_complexity.py операторы и операнды встречаются в первой строке:
import sys # import (operator), sys (operand)
import - это оператор, а sys - имя модуля, поэтому это операнд.
В более сложном примере есть несколько операторов и операндов:
if len(sys.argv) > 1:
...
В этом примере 5 операторов:
if()>:
Кроме того, имеется 2 операнда:
sys.argv1
Помните, что radon учитывает только подмножество операторов. Например, круглые скобки исключаются из любых вычислений.
Для расчета мер Халстеда в radon можно выполнить следующую команду:
$ radon hal cyclomatic_example.py
cyclomatic_example.py:
h1: 3
h2: 6
N1: 3
N2: 6
vocabulary: 9
length: 9
calculated_length: 20.264662506490406
volume: 28.529325012980813
difficulty: 1.5
effort: 42.793987519471216
time: 2.377443751081734
bugs: 0.009509775004326938
Почему radon дает метрику для времени и ошибок?
Халстед предположил, что время, затрачиваемое на кодирование в секундах, можно оценить, разделив усилия (E) на 18.
Халстед также заявил, что ожидаемое количество ошибок можно оценить, разделив объем (V) на 3000. Не забывайте, что это было написано в 1977 году, еще до того, как был изобретен Python! Так что пока не стоит паниковать и начинать искать ошибки.
Индекс ремонтопригодности
Индекс ремонтопригодности объединяет показатели цикломатической сложности МакКейба и объема Халстеда в шкалу, находящуюся примерно между нулем и сотней.
Если вам интересно, то исходное уравнение выглядит следующим образом:
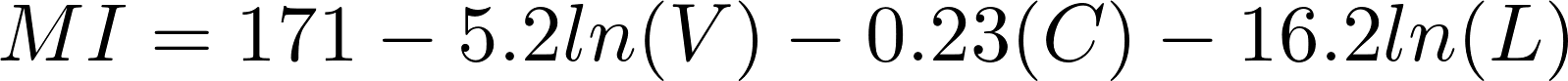
В уравнении V - метрика объема Холстеда, C - цикломатическая сложность, а L - количество строк кода.
Если вы так же озадачены, как и я, когда впервые увидели это уравнение, то вот что оно означает: оно рассчитывает шкалу, включающую количество переменных, операций, путей принятия решений и строк кода.
Он используется во многих инструментах и языках, поэтому это одна из наиболее стандартных метрик. Однако существует множество версий этого уравнения, поэтому точное число не следует воспринимать как факт. radon, wily и Visual Studio устанавливают число между 0 и 100.
По шкале индекса ремонтопригодности все, на что вам нужно обращать внимание, это когда ваш код становится значительно ниже (ближе к 0). Шкала рассматривает все, что ниже 25, как трудно поддерживать, а все, что выше 75, как легко поддерживать. Индекс ремонтопригодности также обозначается как MI.
Индекс ремонтопригодности можно использовать в качестве меры, позволяющей оценить текущую ремонтопригодность вашего приложения и понять, добиваетесь ли вы прогресса в процессе его рефакторинга.
Чтобы рассчитать индекс ремонтопригодности по данным radon, выполните следующую команду:
$ radon mi cyclomatic_example.py -s
cyclomatic_example.py - A (87.42)
В этом результате A - это оценка, которую radon применил к числу 87.42 на шкале. По этой шкале A является наиболее ремонтопригодным, а F - наименее.
Использование wily для определения и отслеживания сложности проектов
wily - это проект с открытым исходным кодом для сбора метрик сложности кода, включая те, которые мы уже рассмотрели, такие как Halstead, Cyclomatic и LOC. wily интегрируется с Git и может автоматизировать сбор метрик по веткам и ревизиям Git.
Цель wily - дать вам возможность увидеть тенденции и изменения в сложности вашего кода с течением времени. Если бы вы пытались доработать автомобиль или улучшить свою физическую форму, вы бы начали с измерения базового уровня и отслеживания улучшений с течением времени.
Установка wily
wily доступен на PyPI и может быть установлен с помощью pip:
$ pip install wily
После установки wily в вашей командной строке будет доступно несколько команд:
wily build: пройдитесь по истории Git и проанализируйте метрики для каждого файлаwily report: посмотреть исторический тренд в метриках для данного файла или папкиwily graph: построить график набора метрик в HTML-файле
Создание кэша
Прежде чем использовать wily, необходимо проанализировать ваш проект. Это делается с помощью команды wily build.
В этой части учебника мы рассмотрим очень популярный пакет requests, используемый для общения с HTTP API. Поскольку этот проект с открытым исходным кодом и доступен на GitHub, мы можем легко получить доступ и скачать копию исходного кода:
$ git clone https://github.com/requests/requests
$ cd requests
$ ls
AUTHORS.rst CONTRIBUTING.md LICENSE Makefile
Pipfile.lock _appveyor docs pytest.ini
setup.cfg tests CODE_OF_CONDUCT.md HISTORY.md
MANIFEST.in Pipfile README.md appveyor.yml
ext requests setup.py tox.ini
Note: Windows users should use the PowerShell command prompt for the following examples instead of traditional MS-DOS Command-Line. To start the PowerShell CLI press Win+R and type powershell then Enter.
Здесь вы увидите несколько папок, предназначенных для тестов, документации и конфигурации. Нас интересует только исходный код пакета requests Python, который находится в папке под названием requests.
Вызовите команду wily build из клонированного исходного кода и укажите имя папки с исходным кодом в качестве первого аргумента:
$ wily build requests
Анализ займет несколько минут, в зависимости от мощности процессора вашего компьютера:

Сбор данных о вашем проекте
После анализа исходного кода requests вы можете запросить любой файл или папку, чтобы посмотреть ключевые метрики. Ранее в учебнике мы обсуждали следующее:
- Строки кода
- Индекс ремонтопригодности
- Цикломатическая сложность
Это 3 метрики по умолчанию в wily. Чтобы увидеть эти метрики для конкретного файла (например, requests/api.py), выполните следующую команду:
$ wily report requests/api.py
wily выведет табличный отчет о стандартных метриках для каждого коммита Git в обратном порядке дат. Вы увидите самый последний коммит вверху, а самый старый - внизу:
| Revision | Author | Date | MI | Lines of Code | Cyclomatic Complexity |
|---|---|---|---|---|---|
| f37daf2 | Nate Prewitt | 2019-01-13 | 100 (0.0) | 158 (0) | 9 (0) |
| 6dd410f | Ofek Lev | 2019-01-13 | 100 (0.0) | 158 (0) | 9 (0) |
| 5c1f72e | Nate Prewitt | 2018-12-14 | 100 (0.0) | 158 (0) | 9 (0) |
| c4d7680 | Matthieu Moy | 2018-12-14 | 100 (0.0) | 158 (0) | 9 (0) |
| c452e3b | Nate Prewitt | 2018-12-11 | 100 (0.0) | 158 (0) | 9 (0) |
| 5a1e738 | Nate Prewitt | 2018-12-10 | 100 (0.0) | 158 (0) | 9 (0) |
Это говорит нам о том, что файл requests/api.py имеет:
- 158 строк кода
- Индекс идеальной сопровождаемости 100
- Цикломатическая сложность 9
Чтобы увидеть другие метрики, сначала нужно узнать их названия. Это можно узнать, выполнив следующую команду:
$ wily list-metrics
Вы увидите список операторов, модулей, которые анализируют код, и метрик, которые они предоставляют.
Чтобы запросить альтернативные метрики в команде отчета, добавьте их названия после имени файла. Вы можете добавить столько метрик, сколько пожелаете. Вот пример с показателями Maintainability Rank и Source Lines of Code:
$ wily report requests/api.py maintainability.rank raw.sloc
Вы увидите, что в таблице теперь есть 2 разных столбца с альтернативными метриками.
Графическая метрика
Теперь, когда вы знаете названия метрик и как запрашивать их в командной строке, вы также можете визуализировать их в виде графиков. wily поддерживает HTML и интерактивные графики с интерфейсом, аналогичным команде report:
$ wily graph requests/sessions.py maintainability.mi
В вашем браузере по умолчанию откроется интерактивная диаграмма, как показано здесь:
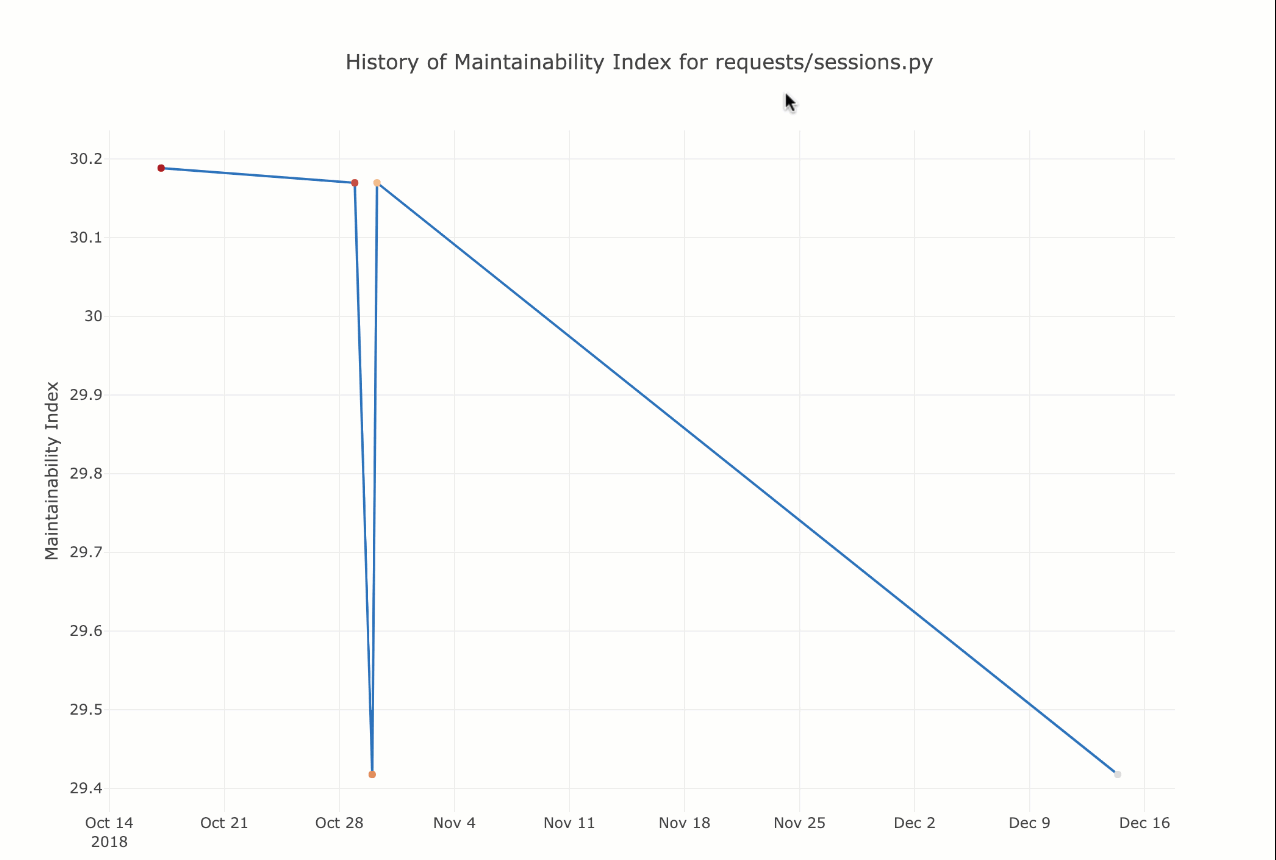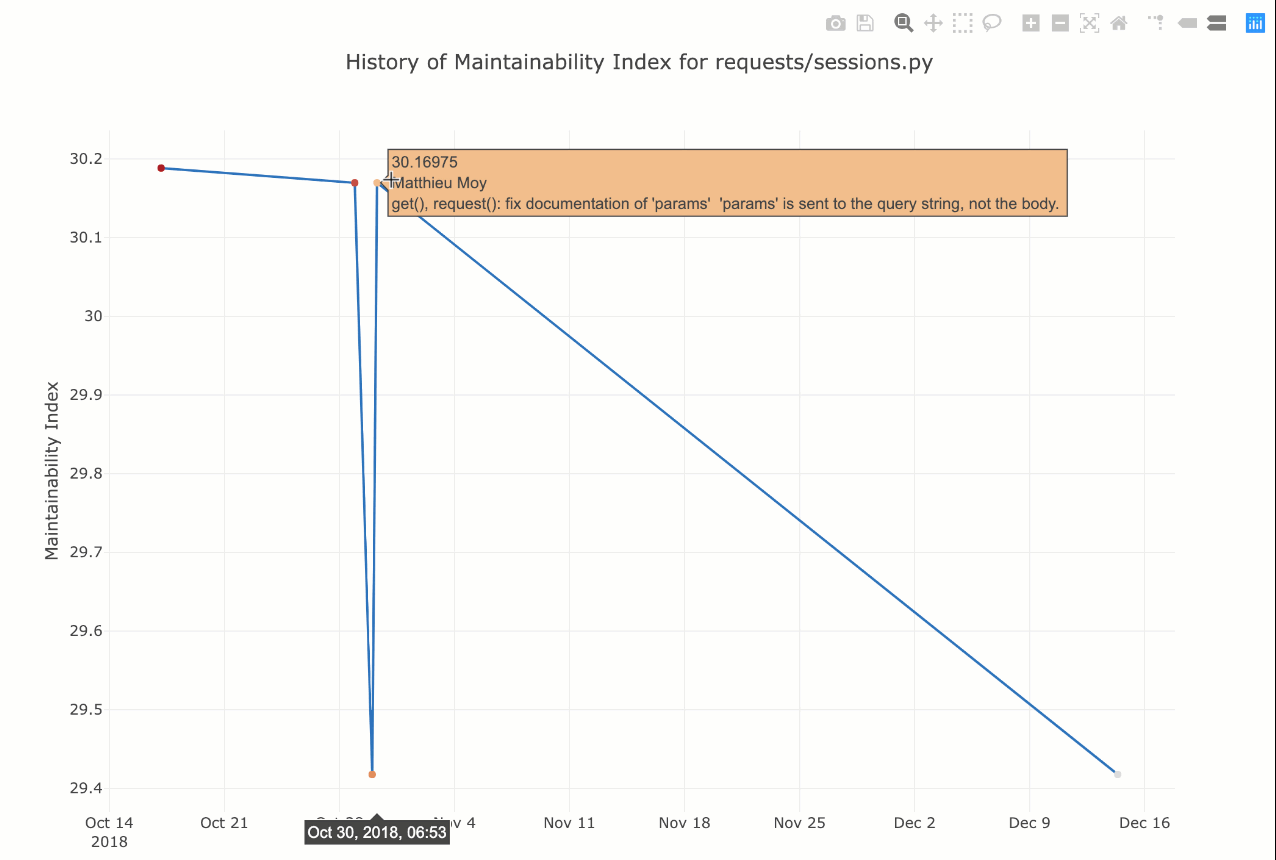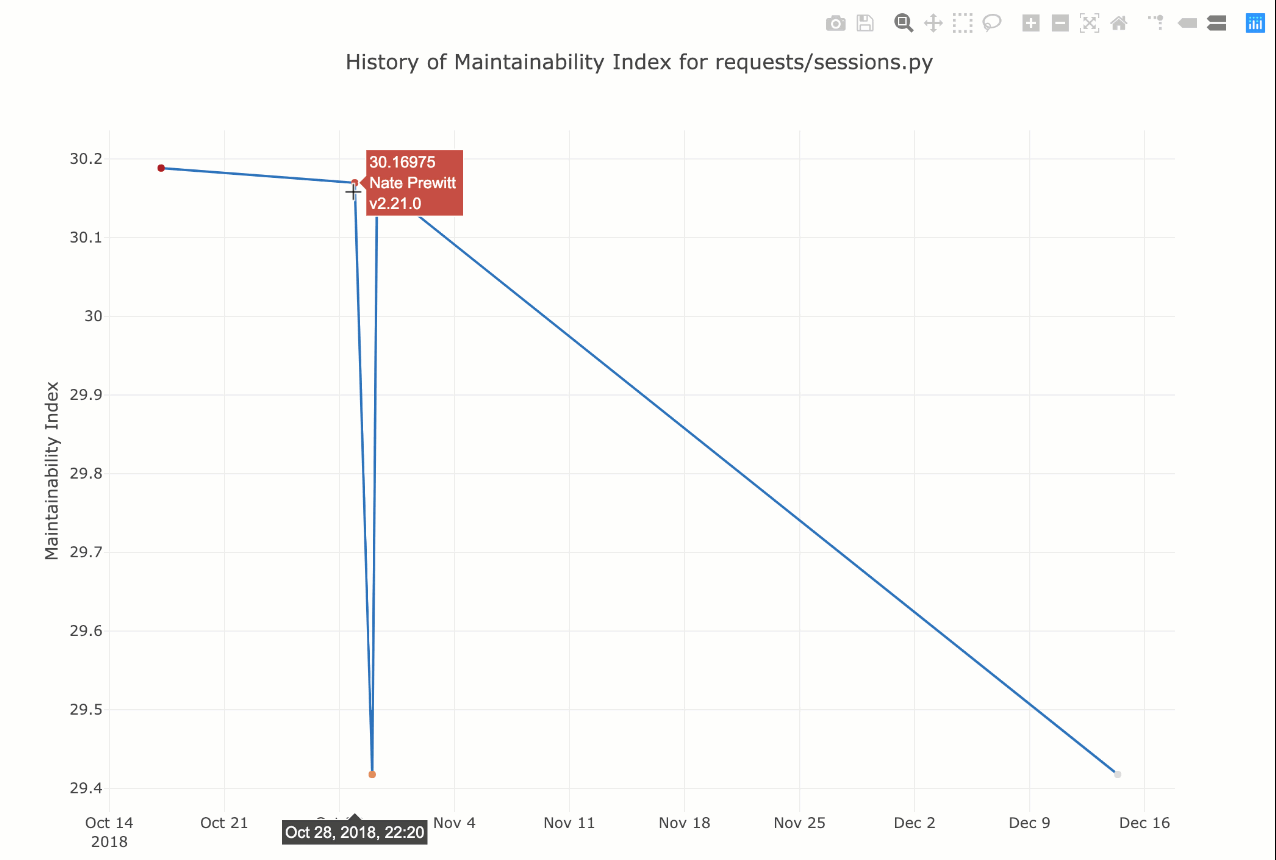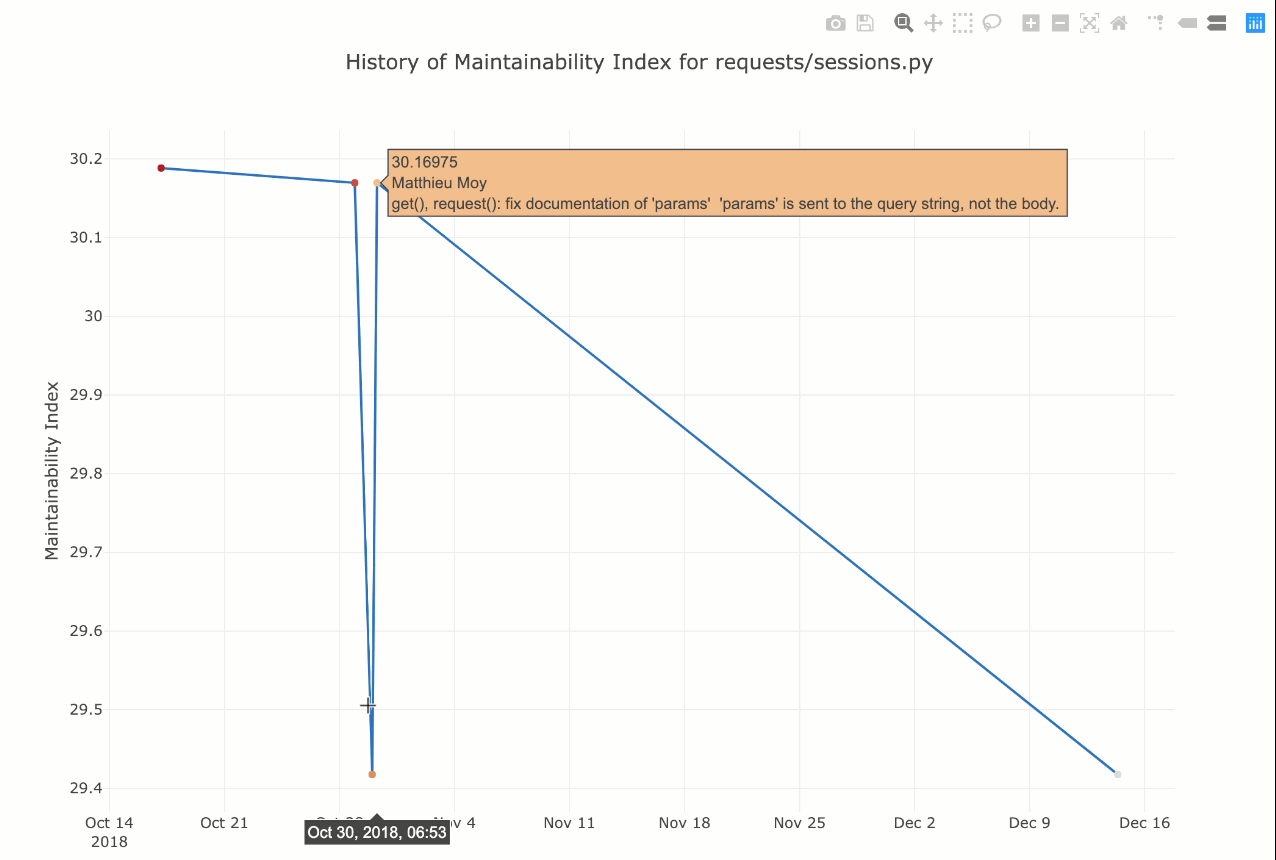
Вы можете навести курсор на определенные точки данных, и он покажет сообщение о фиксации Git, а также данные.
Если вы хотите сохранить HTML-файл в папке или хранилище, вы можете добавить флаг -o с указанием пути к файлу:
$ wily graph requests/sessions.py maintainability.mi -o my_report.html
Теперь у вас будет файл с именем my_report.html, которым вы можете поделиться с другими. Эта команда идеально подходит для командных приборных панелей.
wily в качестве pre-commit крюка
wily можно настроить так, чтобы перед фиксацией изменений в проекте он предупреждал вас об улучшении или ухудшении сложности.
wily имеет команду wily diff, которая сравнивает последние проиндексированные данные с текущей рабочей копией файла.
Чтобы запустить команду wily diff, укажите имена файлов, которые вы изменили. Например, если я внес некоторые изменения в requests/api.py, вы увидите влияние на метрики, выполнив команду wily diff с путем к файлу:
$ wily diff requests/api.py
В ответе вы увидите все измененные метрики, а также функции или классы, которые изменились для цикломатической сложности:

Команда diff может работать в паре с инструментом pre-commit. pre-commit вставляет в конфигурацию Git'а крючок, который вызывает скрипт каждый раз, когда вы выполняете команду git commit.
Чтобы установить pre-commit, вы можете установить из PyPI:
$ pip install pre-commit
Добавьте следующее в папку .pre-commit-config.yaml в корневом каталоге ваших проектов:
repos:
- repo: local
hooks:
- id: wily
name: wily
entry: wily diff
verbose: true
language: python
additional_dependencies: [wily]
После установки этого параметра вы выполняете команду pre-commit install, чтобы завершить работу:
$ pre-commit install
Всякий раз, когда вы запускаете команду git commit, она будет вызывать команду wily diff вместе со списком файлов, которые вы добавили к своим поэтапным изменениям.
wily - полезная утилита для определения базовой сложности вашего кода и измерения улучшений, которые вы делаете, когда начинаете рефакторинг.
Рефакторинг в Python
Рефакторинг - это техника изменения приложения (либо кода, либо архитектуры) таким образом, чтобы внешне оно вело себя так же, но внутренне было улучшено. Этими улучшениями могут быть стабильность, производительность или снижение сложности.
Одна из старейших в мире подземных железных дорог, лондонский метрополитен, начала свою работу в 1863 году с открытием линии Metropolitan. В нем были деревянные вагоны с газовым освещением, которые двигали паровозы. К моменту открытия железной дороги она была вполне пригодна для использования по назначению. В 1900 году были изобретены электрические железные дороги.
К 1908 году лондонское метро расширилось до 8 железнодорожных путей. Во время Второй мировой войны станции лондонского метро были закрыты для поездов и использовались как бомбоубежища. Современный лондонский метрополитен перевозит миллионы пассажиров в день, имея более 270 станций:
 Объединенная карта железных дорог лондонского метрополитена, ок. 1908 г. (Изображение: Википедия )
Объединенная карта железных дорог лондонского метрополитена, ок. 1908 г. (Изображение: Википедия )
Написать идеальный код с первого раза практически невозможно, а требования часто меняются. Если бы вы попросили первоначальных разработчиков железной дороги спроектировать сеть, рассчитанную на 10 миллионов пассажиров в день в 2020 году, они бы не спроектировали ту сеть, которая существует сегодня.
Вместо этого железная дорога претерпела ряд постоянных изменений, чтобы оптимизировать свою работу, дизайн и планировку в соответствии с изменениями в городе. Она была подвергнута рефакторингу.
В этом разделе вы узнаете, как безопасно проводить рефакторинг, используя тесты и инструменты. Вы также увидите, как использовать функциональность рефакторинга в Visual Studio Code и PyCharm:
Избегание рисков при рефакторинге: Использование инструментов и наличие тестов
Если смысл рефакторинга заключается в том, чтобы улучшить внутренние компоненты приложения, не затрагивая внешние, то как убедиться, что внешние компоненты не изменились?
Прежде чем приступать к масштабному проекту рефакторинга, необходимо убедиться, что у вас есть надежный набор тестов для вашего приложения. В идеале этот набор тестов должен быть в основном автоматизирован, чтобы по мере внесения изменений вы могли видеть их влияние на пользователя и быстро устранять их.
Если вы хотите узнать больше о тестировании на Python, Getting Started With Testing in Python - отличное место для начала.
Не существует идеального количества тестов для вашего приложения. Но чем надежнее и тщательнее набор тестов, тем агрессивнее вы можете рефакторить свой код.
Две наиболее распространенные задачи, которые вы будете выполнять при рефакторинге, это:
- Переименование модулей, функций, классов и методов
- Поиск использования функций, классов и методов, чтобы увидеть, где они вызываются
Вы можете сделать это вручную, используя поиск и замену, но это отнимает много времени и связано с риском. Вместо этого есть несколько отличных инструментов для выполнения этих задач.
Использование rope для рефакторинга
rope - это бесплатная утилита для рефакторинга кода на Python. Она поставляется с обширным набором API для рефакторинга и переименования компонентов в вашей кодовой базе Python.
rope можно использовать двумя способами:
- С помощью плагина редактора, например Visual Studio Code, Emacs или Vim
- Непосредственно путем написания скриптов для рефакторинга вашего приложения
Чтобы использовать веревку в качестве библиотеки, сначала установите rope, выполнив pip:
$ pip install rope
Полезно работать с rope в REPL, чтобы вы могли изучать проект и видеть изменения в реальном времени. Для начала импортируйте тип Project и инстанцируйте его, указав путь к проекту:
>>> from rope.base.project import Project
>>> proj = Project('requests')
Переменная proj теперь может выполнять серию команд, таких как get_files и get_file, чтобы получить определенный файл. Получите файл api.py и присвойте его переменной api:
>>> [f.name for f in proj.get_files()]
['structures.py', 'status_codes.py', ...,'api.py', 'cookies.py']
>>> api = proj.get_file('api.py')
Если бы вы захотели переименовать этот файл, вы могли бы просто переименовать его в файловой системе. Однако любые другие файлы Python в вашем проекте, которые импортировали старое имя, теперь будут нарушены. Давайте переименуем api.py в new_api.py:
>>> from rope.refactor.rename import Rename
>>> change = Rename(proj, api).get_changes('new_api')
>>> proj.do(change)
Запустив git status, вы увидите, что rope внесла некоторые изменения в репозиторий:
$ git status
On branch master
Your branch is up to date with 'origin/master'.
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: requests/__init__.py
deleted: requests/api.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
requests/.ropeproject/
requests/new_api.py
no changes added to commit (use "git add" and/or "git commit -a")
Три изменения, внесенные rope, следующие:
- Удалили
requests/api.pyи создалиrequests/new_api.py - Измените
requests/__init__.pyна импорт изnew_apiвместоapi - Создайте папку проекта с именем
.ropeproject
Чтобы сбросить изменения, выполните git reset.
Существуют сотни других рефакторингов, которые можно сделать с помощью rope.
Использование Visual Studio Code для рефакторинга
Visual Studio Code открывает небольшое подмножество команд рефакторинга, доступных в rope, через свой собственный пользовательский интерфейс.
Вы можете:
- Извлечение переменных из оператора
- Извлечение методов из блока кода
- Сортировка импорта в логическом порядке
Вот пример использования команды Extract methods из палитры команд:
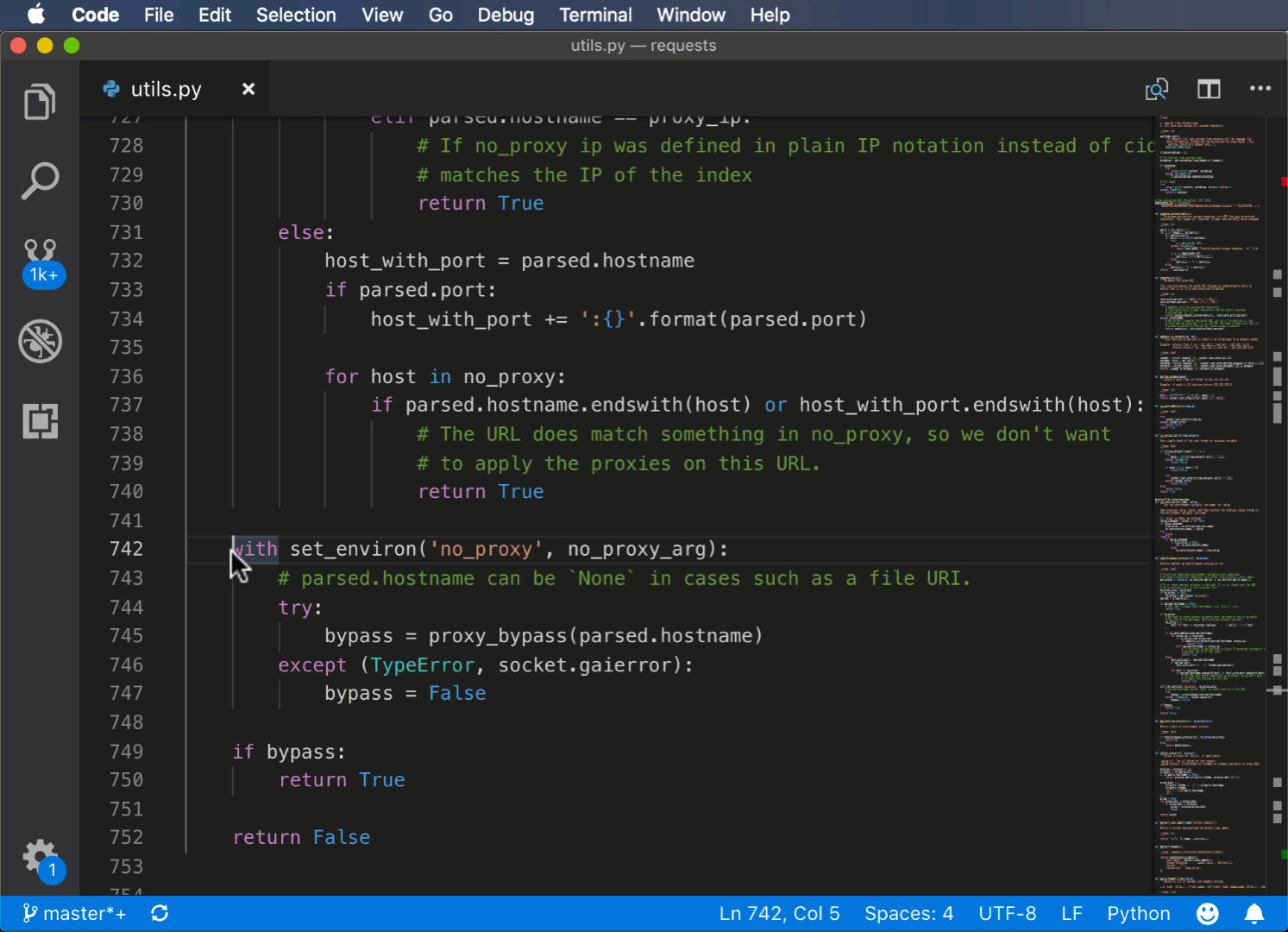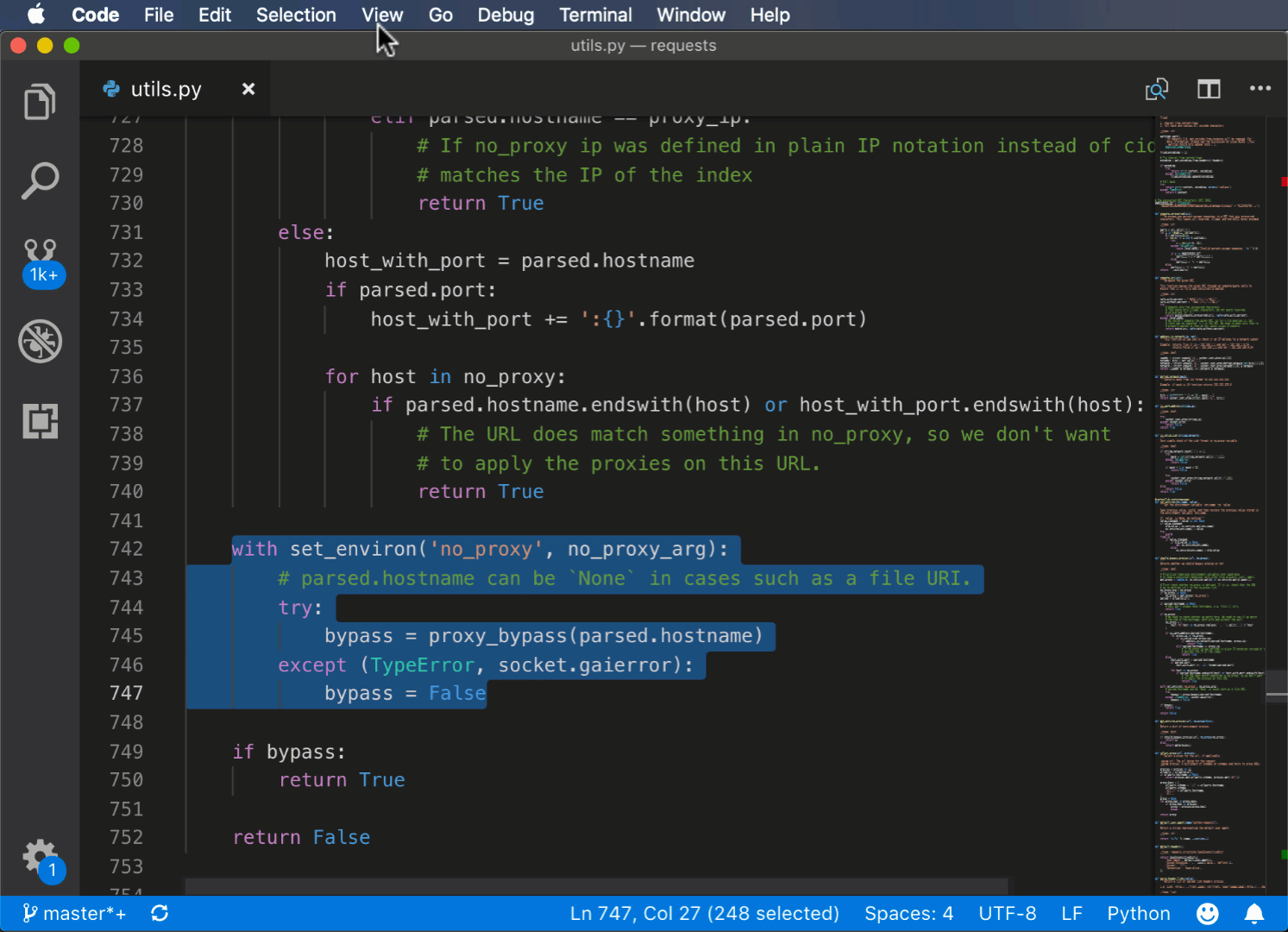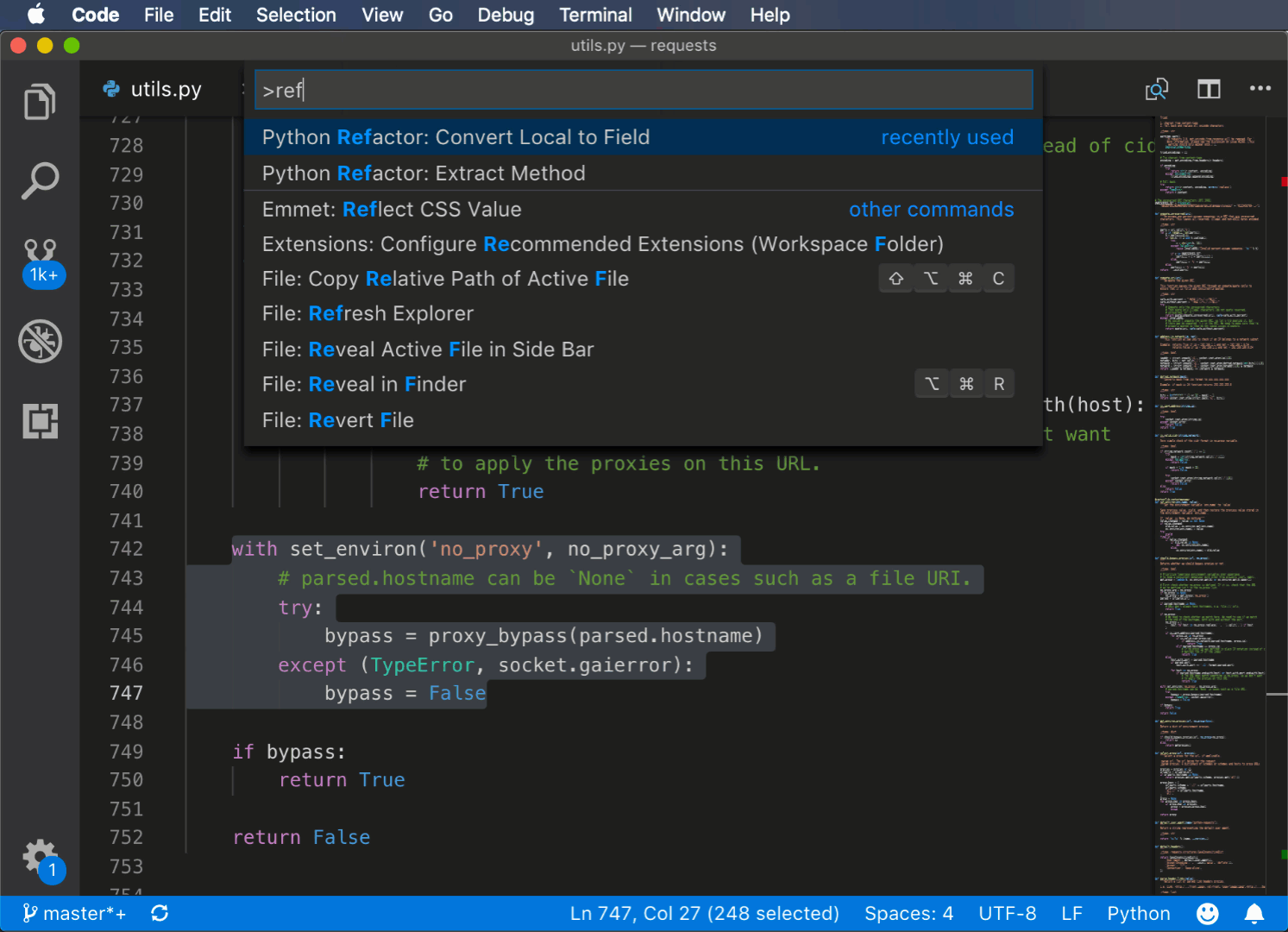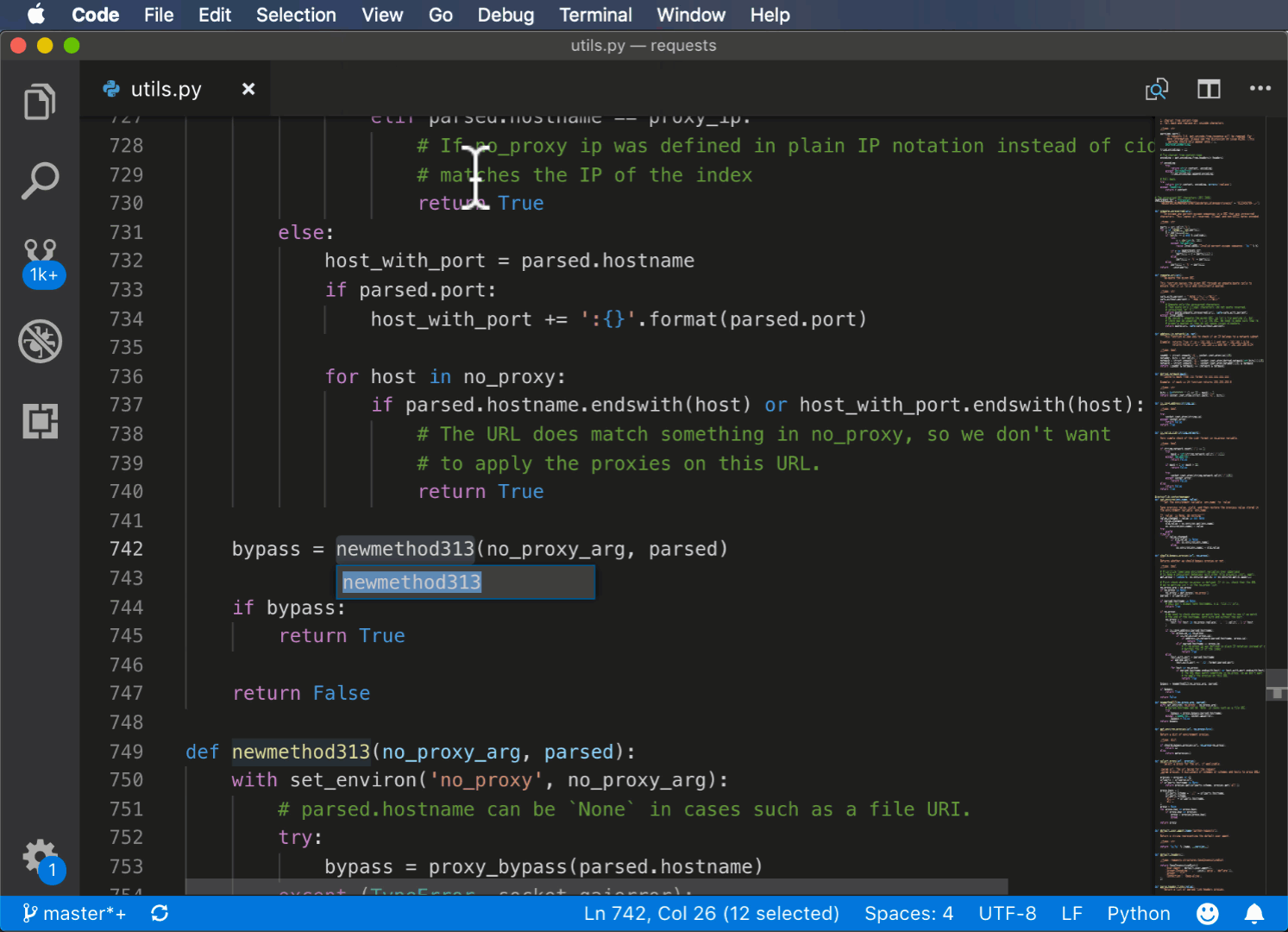
Использование PyCharm для рефакторинга
Если вы используете или собираетесь использовать PyCharm в качестве редактора Python, стоит обратить внимание на мощные возможности рефакторинга, которыми он обладает.
You can access all the refactoring shortcuts with the Ctrl+T command on Windows and macOS. The shortcut to access refactoring in Linux is Ctrl+Shift+Alt+T.
Поиск вызывающих и использующих функций и классов
Прежде чем удалить метод или класс или изменить его поведение, вам нужно знать, какой код от него зависит. PyCharm может найти все случаи использования метода, функции или класса в вашем проекте.
Чтобы получить доступ к этой функции, выберите метод, класс или переменную, щелкнув правой кнопкой мыши, и выберите Find Usages:
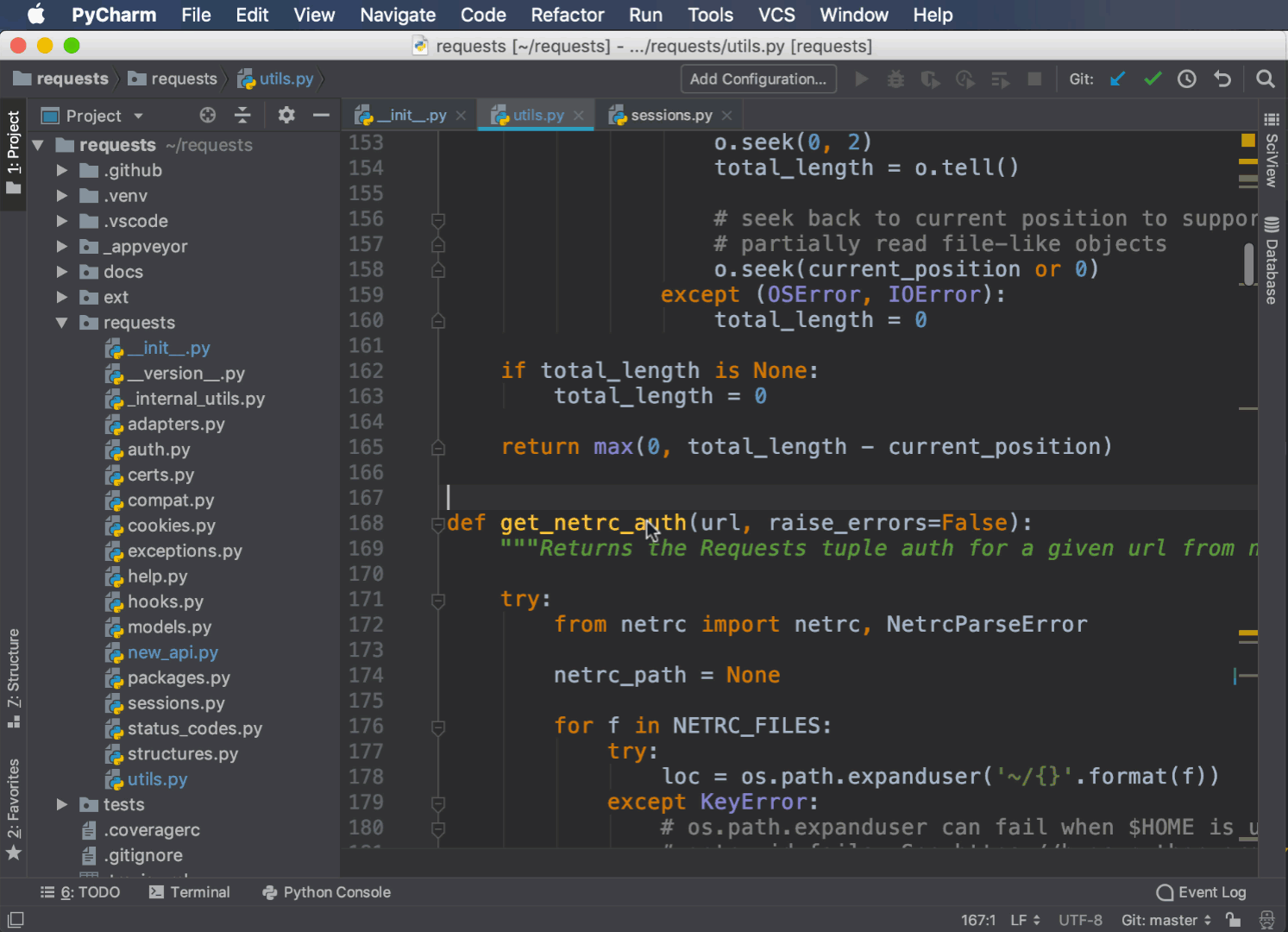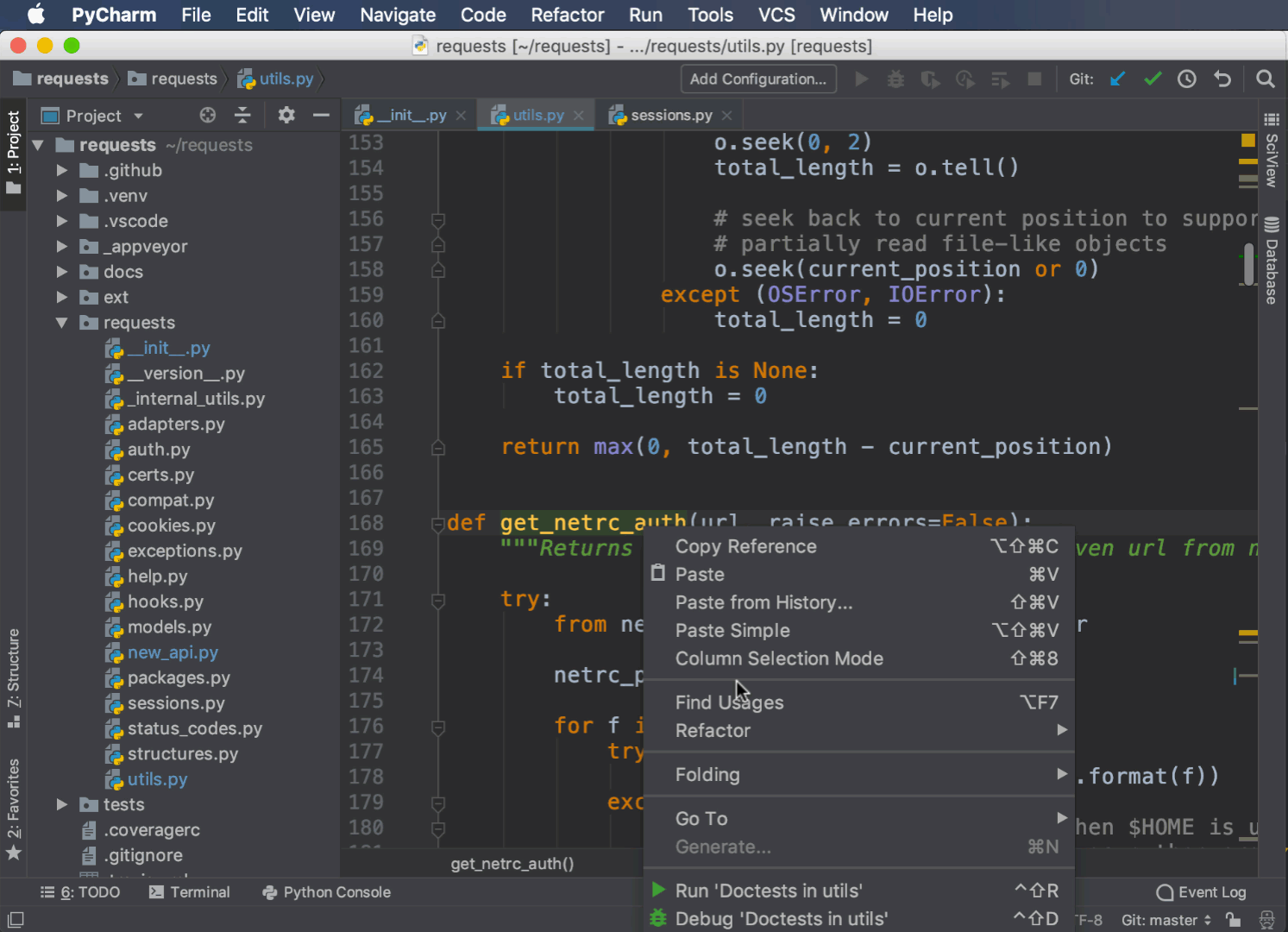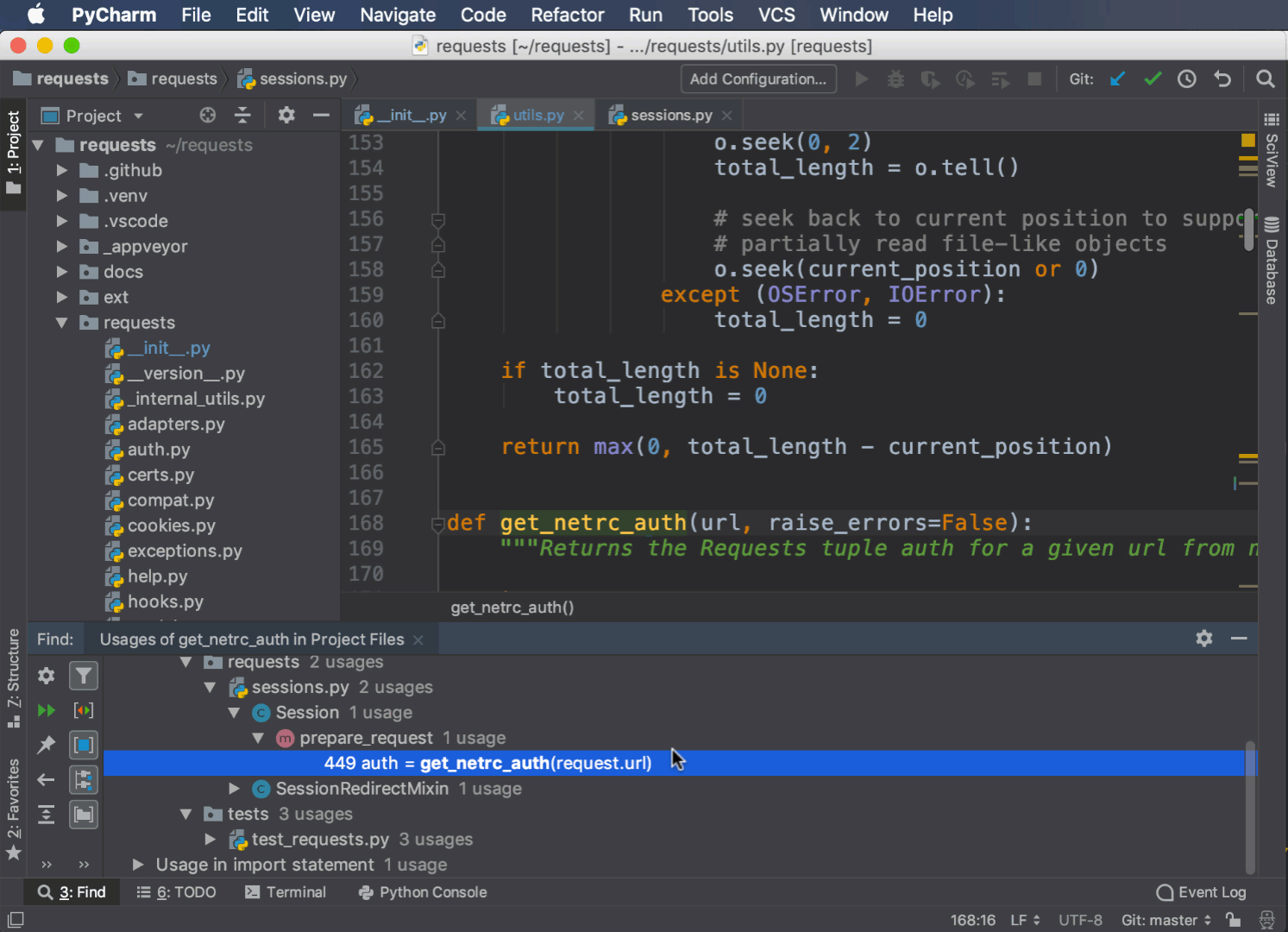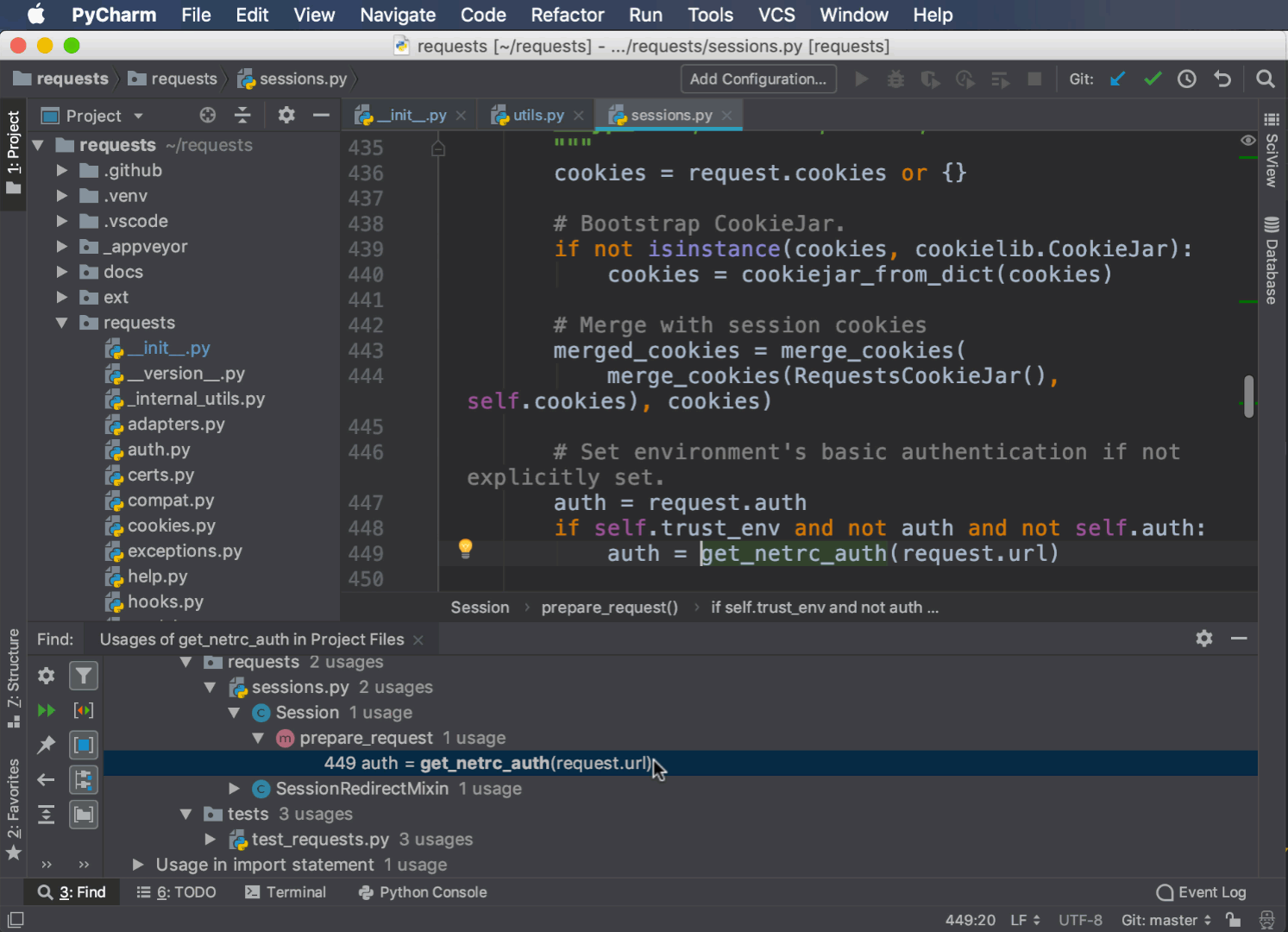
Весь код, использующий ваши критерии поиска, отображается на панели внизу. Вы можете дважды щелкнуть на любом элементе, чтобы перейти непосредственно к соответствующей строке.
Использование инструментов рефакторинга PyCharm
Некоторые из других команд рефакторинга включают возможность:
- Извлечение методов, переменных и констант из существующего кода
- Извлечение абстрактных классов из существующих сигнатур классов, включая возможность указания абстрактных методов
- Переименовывать практически все, от переменной до метода, файла, класса или модуля
Вот пример переименования того же модуля api.py, который вы переименовали ранее с помощью модуля rope в new_api.py:
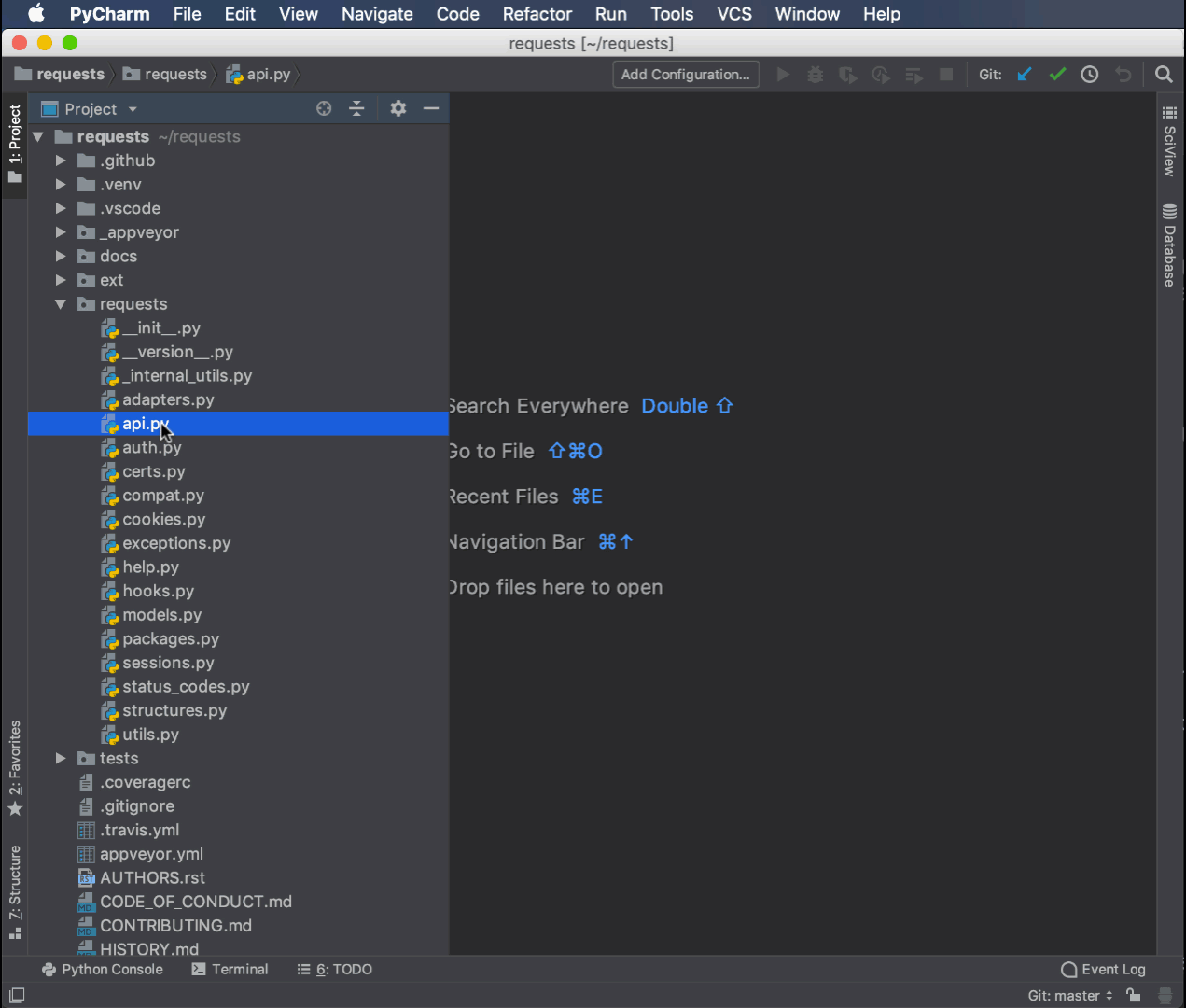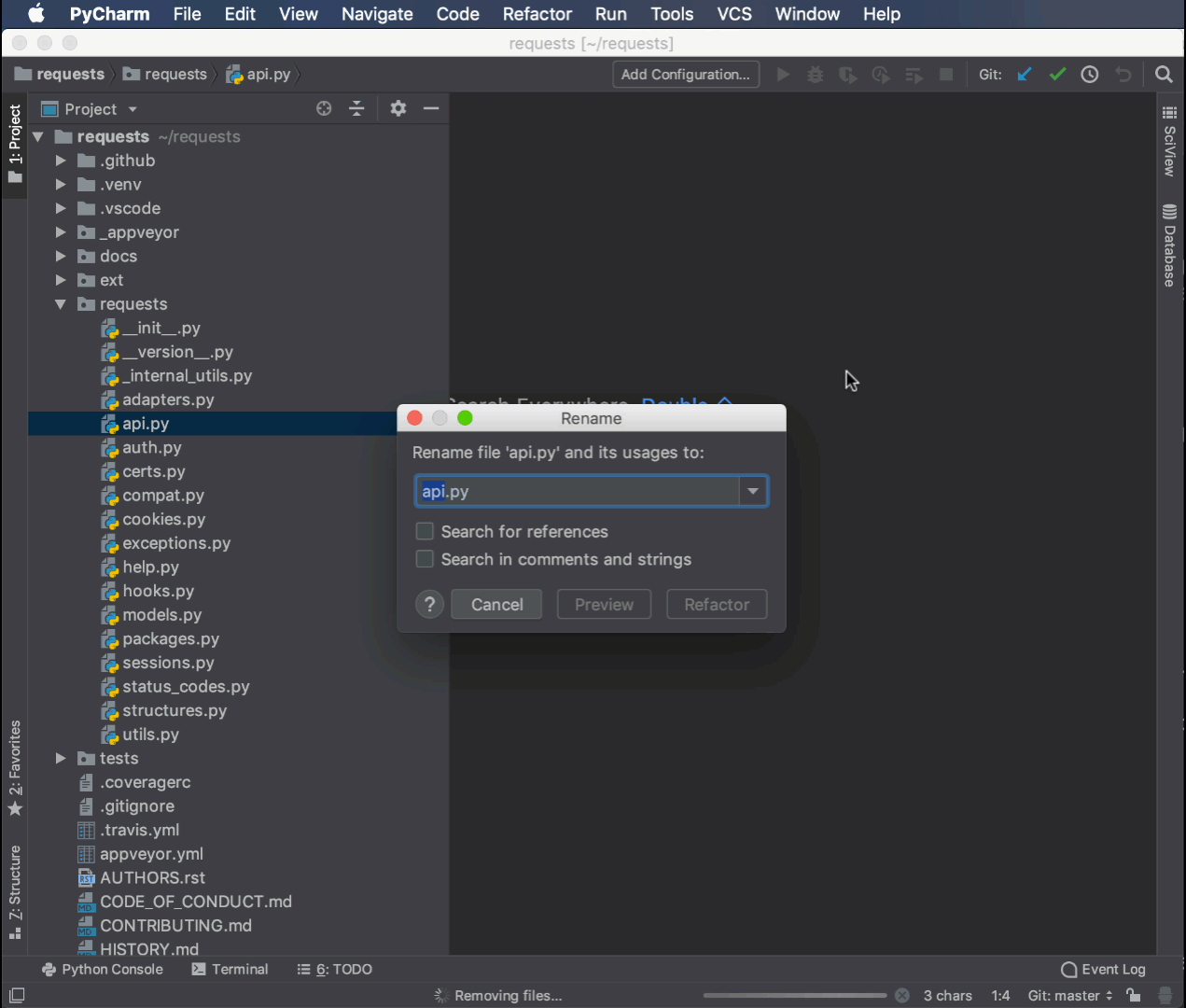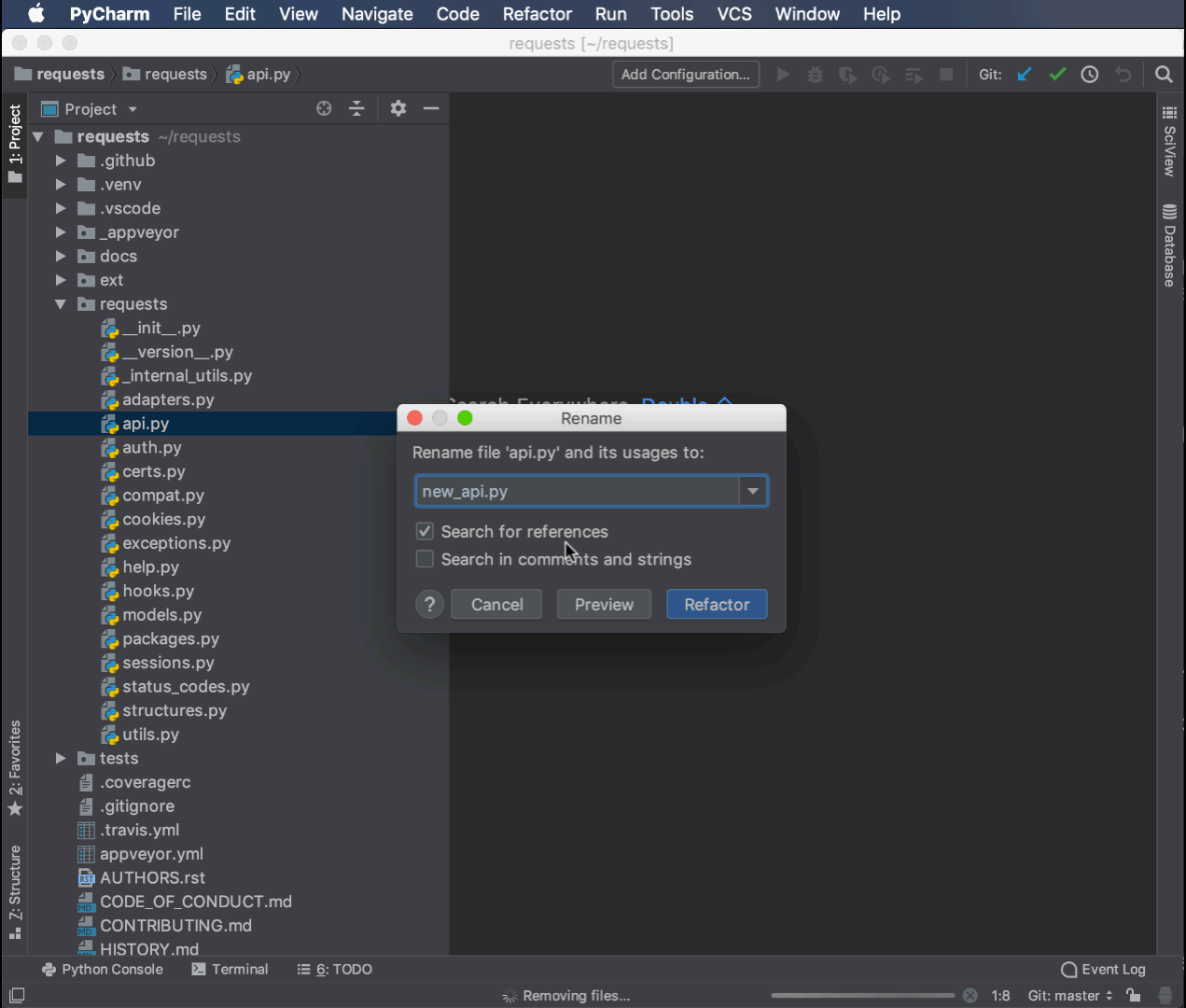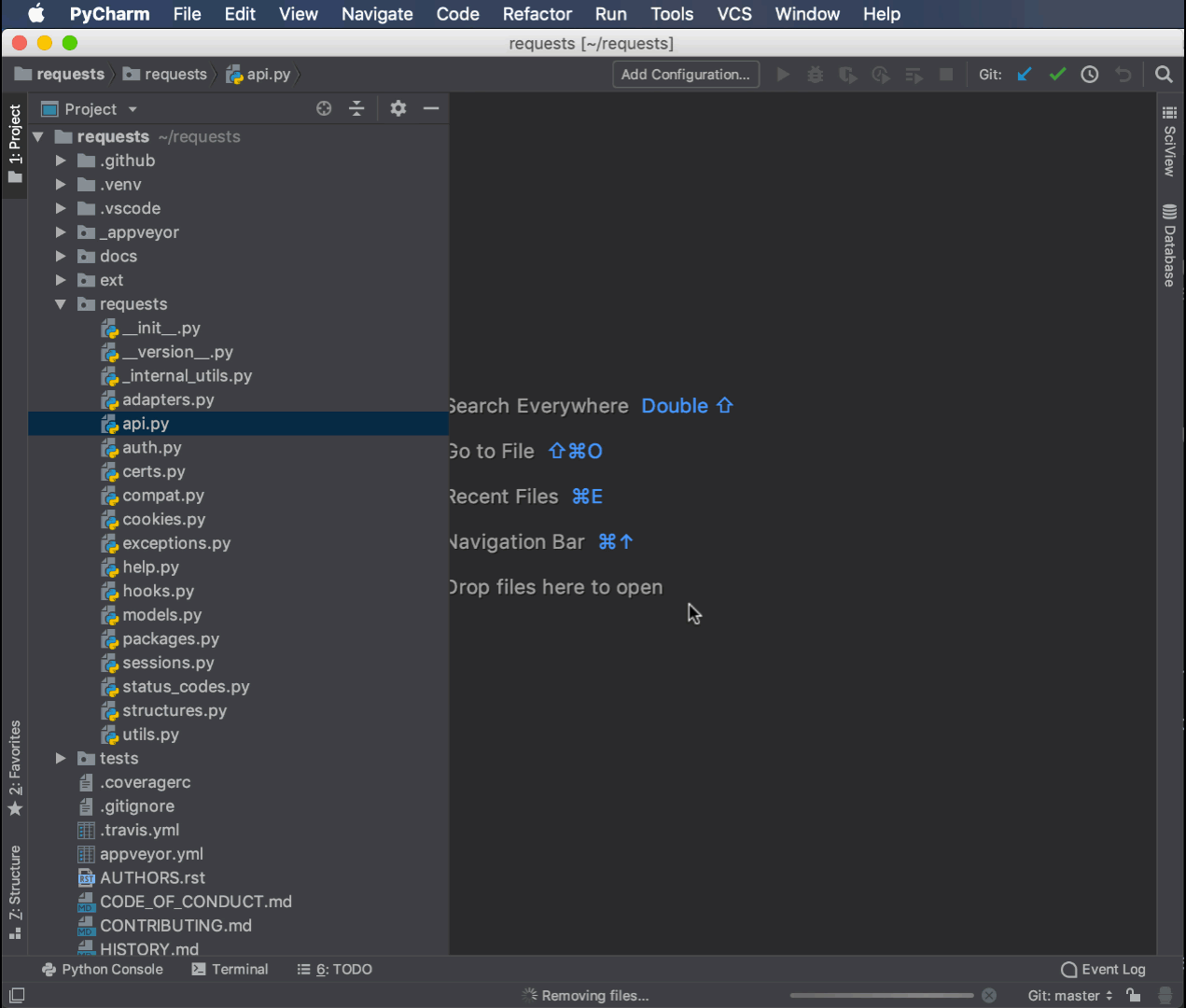
Команда переименования контекстно привязана к пользовательскому интерфейсу, что делает рефакторинг быстрым и простым. Она автоматически обновила импорт в __init__.py с новым именем модуля.
Еще одним полезным рефактором является команда Change Signature. С ее помощью можно добавить, удалить или переименовать аргументы в функции или методе. Она сама найдет нужные варианты и обновит их за вас:
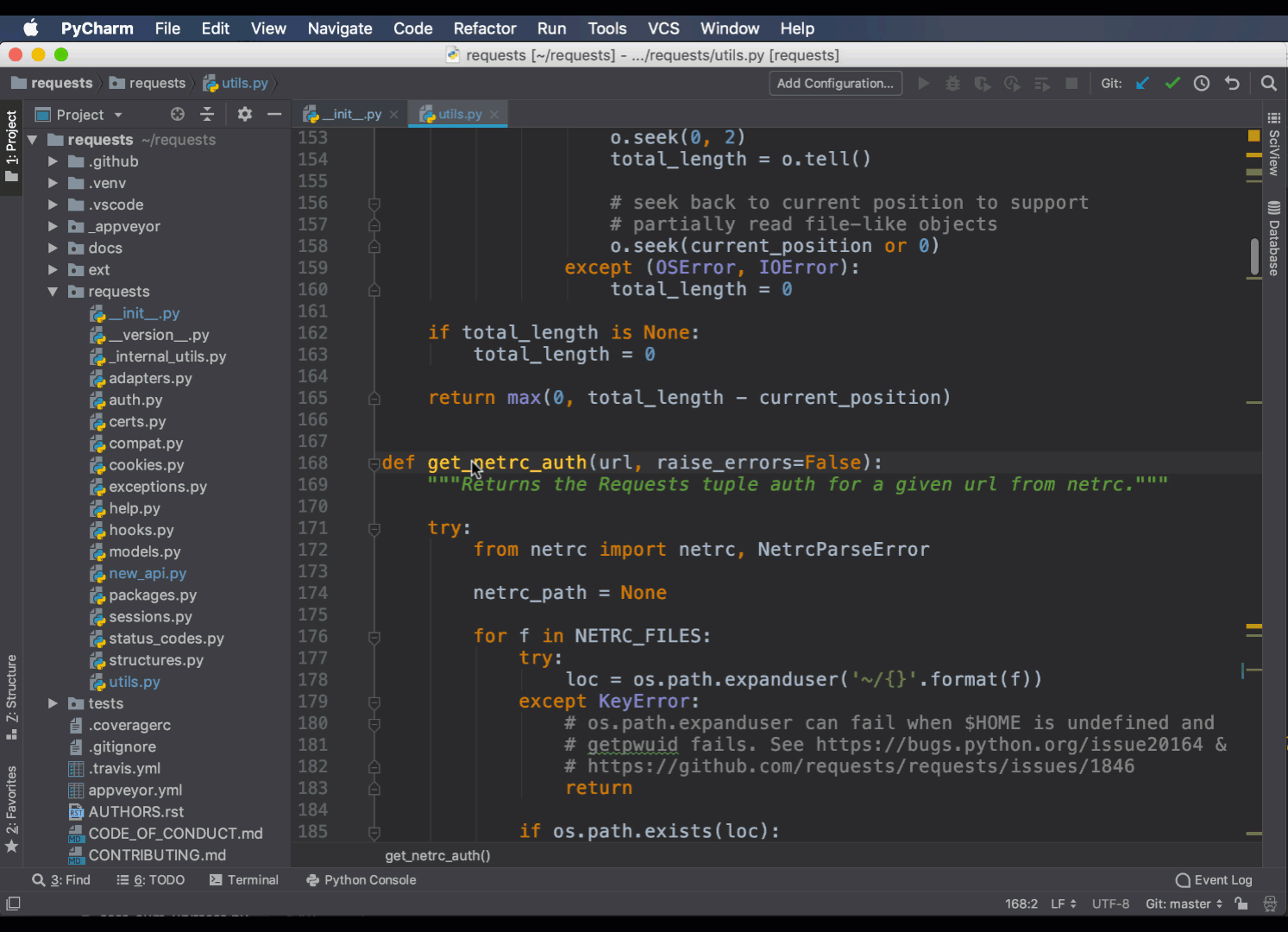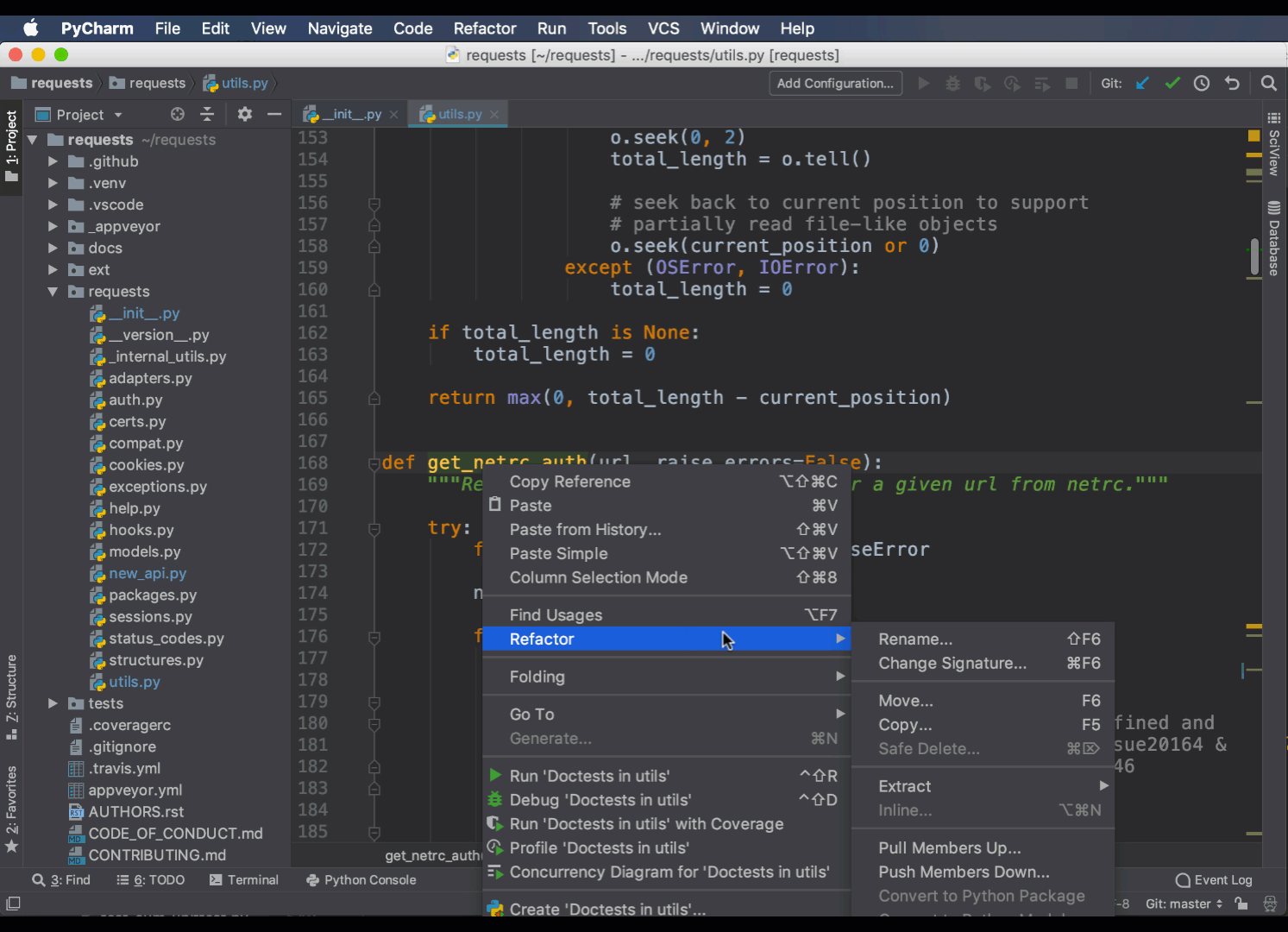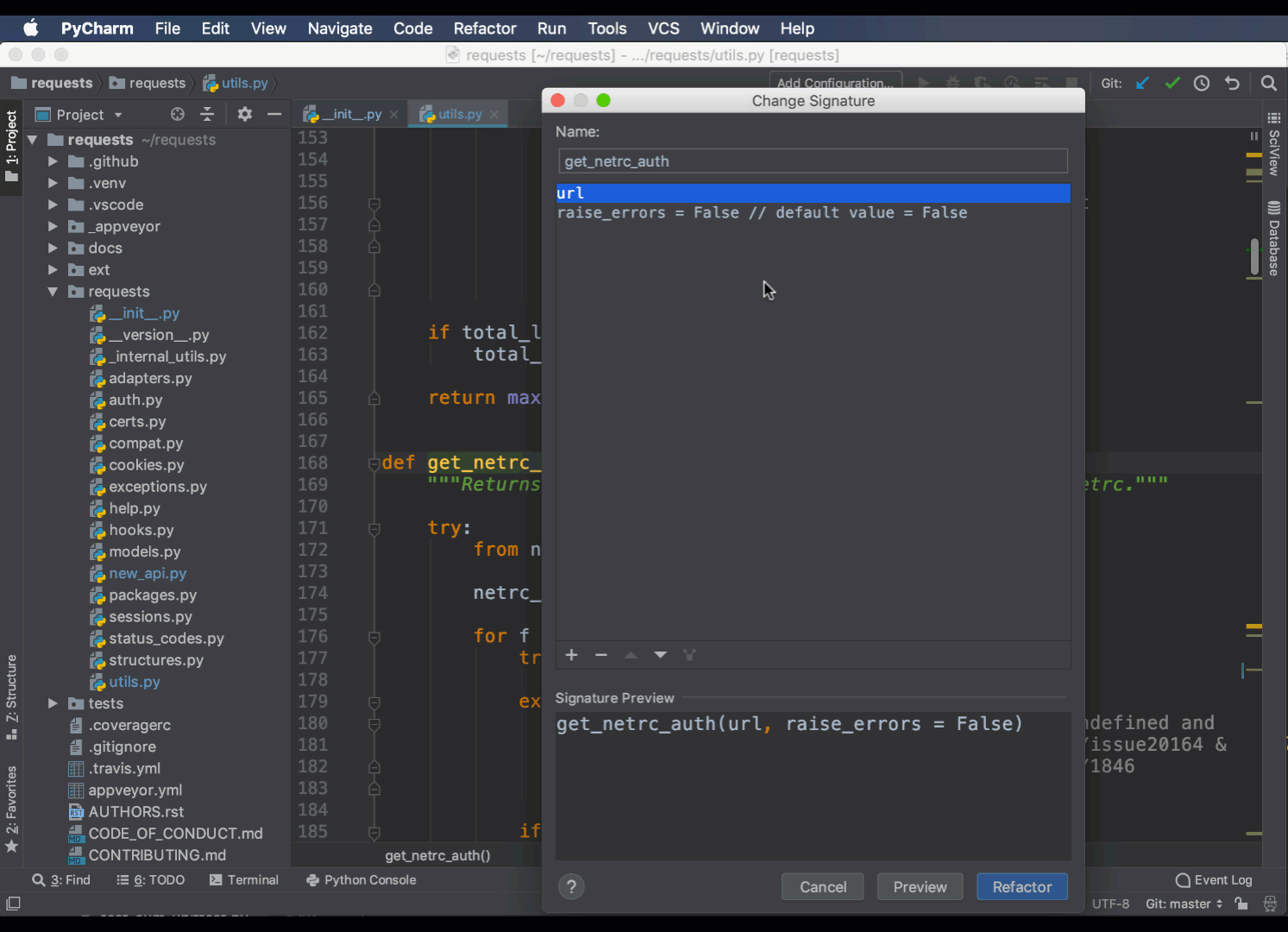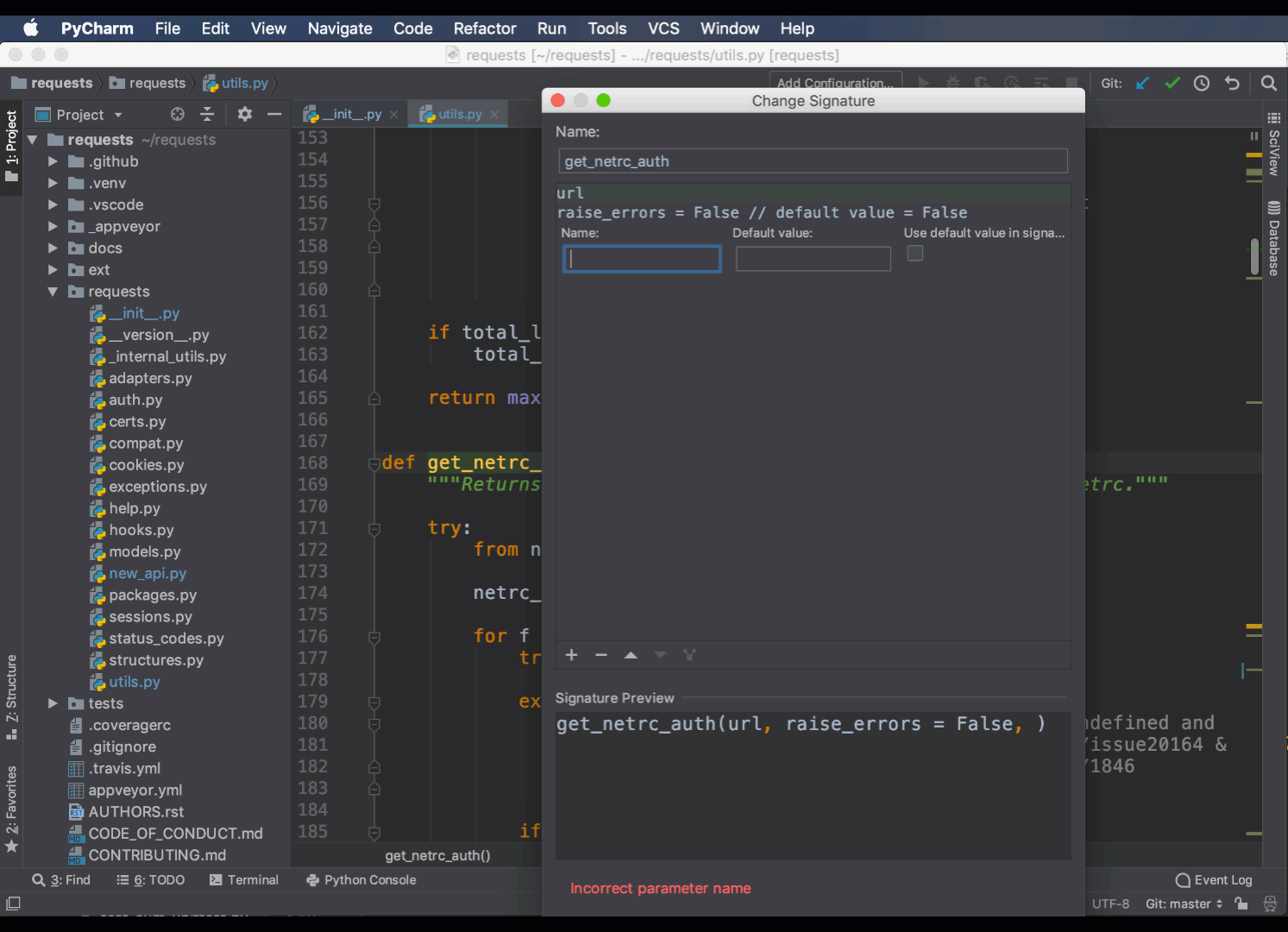
Вы можете установить значения по умолчанию, а также решить, как рефакторинг должен обрабатывать новые аргументы.
Итоги
Рефакторинг - важный навык для любого разработчика. Как вы узнали из этой главы, вы не одиноки. Инструменты и среды разработки уже оснащены мощными функциями рефакторинга, позволяющими быстро вносить изменения.
Антипаттерны сложности
Теперь, когда вы знаете, как можно измерить сложность, как ее измерить и как рефакторить свой код, пришло время узнать 5 распространенных анти-паттернов, которые делают код сложнее, чем нужно:
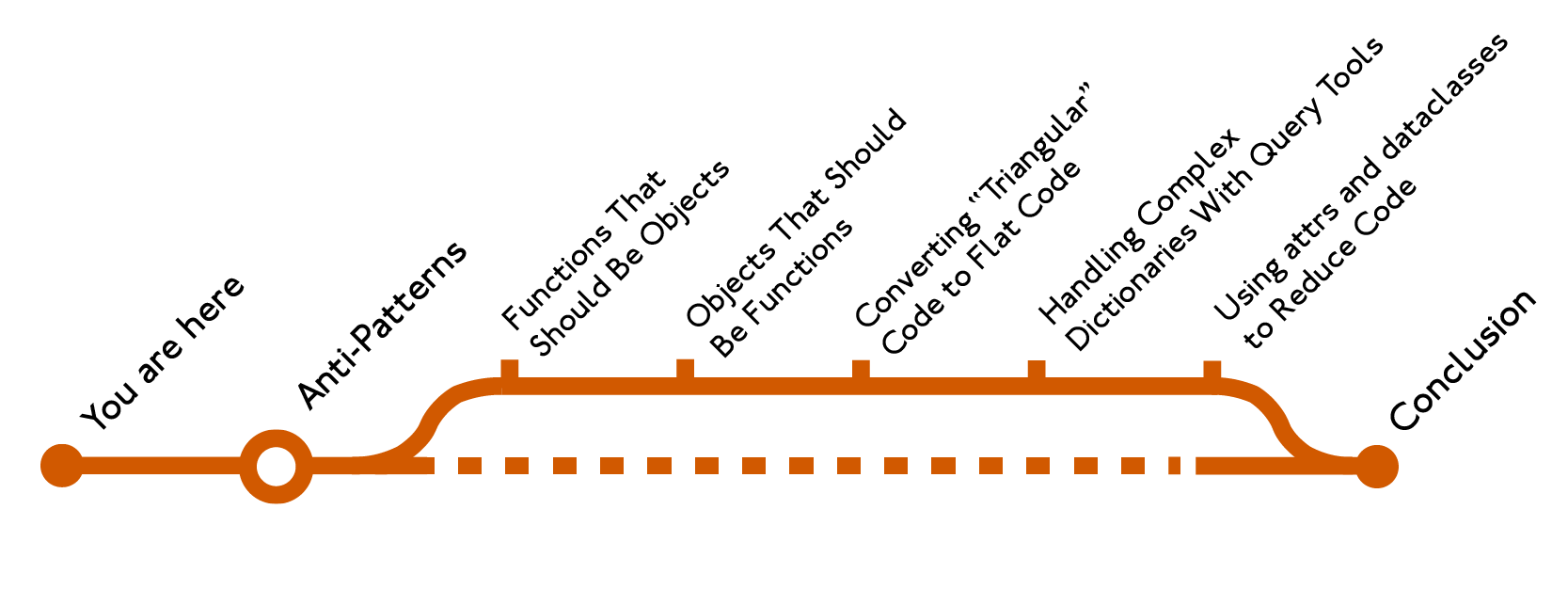
Если вы освоите эти паттерны и будете знать, как их рефакторить, вы вскоре станете на путь (каламбурно) к более удобному для обслуживания приложению на Python.
1. Функции, которые должны быть объектами
Python поддерживает процедурное программирование с использованием функций, а также наследуемые классы. Оба варианта очень мощные и должны применяться для решения разных задач.
Взять хотя бы этот пример модуля для работы с изображениями. Логика в функциях удалена для краткости:
# imagelib.py
def load_image(path):
with open(path, "rb") as file:
fb = file.load()
image = img_lib.parse(fb)
return image
def crop_image(image, width, height):
...
return image
def get_image_thumbnail(image, resolution=100):
...
return image
У этой конструкции есть несколько проблем:
-
Неясно, модифицируют ли
crop_image()иget_image_thumbnail()исходную переменнуюimageили создают новые изображения. Если вы хотите загрузить изображение, а затем создать обрезанное и уменьшенное изображение, нужно ли сначала скопировать экземпляр? Вы могли бы прочитать исходный код функций, но не стоит полагаться на то, что каждый разработчик так поступает. -
Вы должны передавать переменную image в качестве аргумента в каждом вызове функций image.
Вот как может выглядеть код вызова:
from imagelib import load_image, crop_image, get_image_thumbnail
image = load_image('~/face.jpg')
image = crop_image(image, 400, 500)
thumb = get_image_thumbnail(image)
Вот некоторые признаки кода, использующего функции, которые можно рефакторизовать в классы:
- Похожие аргументы в разных функциях
- Большее число Халстеда
h2уникальных операндов - Смесь мутабельных и мутабельных функций
- Функции, распределенные по нескольким файлам Python
Вот рефакторинговая версия этих 3 функций, в которой происходит следующее:
.__init__()заменяетload_image().crop()становится методом класса .get_image_thumbnail()становится свойством.
Разрешение миниатюр стало свойством класса, поэтому его можно изменять глобально или для конкретного экземпляра:
# imagelib.py
class Image(object):
thumbnail_resolution = 100
def __init__(self, path):
...
def crop(self, width, height):
...
@property
def thumbnail(self):
...
return thumb
Если бы в этом коде было гораздо больше функций, связанных с изображениями, рефакторинг до класса мог бы кардинально изменить ситуацию. Следующим соображением будет сложность потребляемого кода.
Вот как будет выглядеть отрефакторенный пример:
from imagelib import Image
image = Image('~/face.jpg')
image.crop(400, 500)
thumb = image.thumbnail
В результирующем коде мы решили исходные задачи:
- Понятно, что
thumbnailвозвращает миниатюру, поскольку это свойство, и что оно не изменяет экземпляр. - Код больше не требует создания новых переменных для операции кадрирования.
2. Объекты, которые должны быть функциями
Иногда верно и обратное. Есть объектно-ориентированный код, для которого лучше подойдет простая функция или две.
Вот несколько признаков неправильного использования классов:
- Классы с 1 методом (кроме
.__init__()) - Классы, содержащие только статические методы
Возьмем этот пример класса аутентификации:
# authenticate.py
class Authenticator(object):
def __init__(self, username, password):
self.username = username
self.password = password
def authenticate(self):
...
return result
Логичнее было бы иметь простую функцию с именем authenticate(), которая принимает username и password в качестве аргументов:
# authenticate.py
def authenticate(username, password):
...
return result
Вам не нужно садиться и вручную искать классы, соответствующие этим критериям: pylint поставляется с правилом, согласно которому классы должны иметь минимум 2 публичных метода. Подробнее о PyLint и других инструментах контроля качества кода вы можете прочитать в Python Code Quality и Writing Cleaner Python Code With PyLint.
Чтобы установить pylint, выполните следующую команду в консоли:
$ pip install pylint
pylint принимает ряд необязательных аргументов, а затем путь к одному или нескольким файлам и папкам. Если запустить pylint с настройками по умолчанию, он выдаст очень много результатов, так как pylint имеет огромное количество правил. Вместо этого можно запустить определенные правила. Идентификатором правила too-few-public-methods является R0903. Вы можете посмотреть его на сайте документации :
$ pylint --disable=all --enable=R0903 requests
************* Module requests.auth
requests/auth.py:72:0: R0903: Too few public methods (1/2) (too-few-public-methods)
requests/auth.py:100:0: R0903: Too few public methods (1/2) (too-few-public-methods)
************* Module requests.models
requests/models.py:60:0: R0903: Too few public methods (1/2) (too-few-public-methods)
-----------------------------------
Your code has been rated at 9.99/10
Этот вывод говорит нам о том, что auth.py содержит 2 класса, которые имеют только 1 публичный метод. Эти классы находятся в строках 72 и 100. В строке 60 models.py также есть класс, имеющий только 1 публичный метод.
3. Преобразование "треугольного" кода в плоский
Если бы вы увеличили масштаб своего исходного кода и наклонили голову на 90 градусов вправо, выглядел бы пробел плоским, как в Голландии, или гористым, как в Гималаях? Гористый код - признак того, что в вашем коде много вложенности.
Вот один из принципов в Дзен Питона:
"Плоское лучше, чем вложенное"
- Тим Питерс, Zen of Python
Почему плоский код лучше вложенного? Потому что вложенный код усложняет чтение и понимание происходящего. Читателю приходится понимать и запоминать условия по мере прохождения ветвей.
Вот симптомы сильно вложенного кода:
- Высокая цикломатическая сложность из-за большого количества ветвлений кода
- Низкий индекс удобства обслуживания из-за высокой цикломатической сложности по отношению к количеству строк кода
Взять хотя бы этот пример, в котором аргумент data просматривается на предмет наличия строк, соответствующих слову error. Сначала проверяется, является ли аргумент data списком. Затем выполняется итерация по каждому элементу и проверяется, является ли он строкой. Если это строка и ее значение равно "error", то возвращается True. В противном случае возвращается False:
def contains_errors(data):
if isinstance(data, list):
for item in data:
if isinstance(item, str):
if item == "error":
return True
return False
Эта функция будет иметь низкий индекс сопровождаемости, потому что она маленькая, но у нее высокая цикломатическая сложность.
Вместо этого мы можем рефакторизовать эту функцию, "возвращаясь раньше", чтобы удалить уровень вложенности, и возвращая False, если значение data не является списком. Затем используйте .count() на объекте list для подсчета экземпляров "error". Возвращаемое значение - это оценка того, что .count() больше нуля:
def contains_errors(data):
if not isinstance(data, list):
return False
return data.count("error") > 0
Другой метод сокращения вложенности - использование понимания списков. Эта распространенная схема создания нового списка, перебора каждого элемента в списке на предмет соответствия критерию, а затем добавления всех совпадений в новый список:
results = []
for item in iterable:
if item == match:
results.append(item)
Этот код можно заменить более быстрым и эффективным пониманием списка.
Переделайте последний пример в списочное понимание и оператор if:
results = [item for item in iterable if item == match]
Этот новый пример меньше по размеру, имеет меньшую сложность и более производительный.
Если ваши данные не являются одномерным списком, то вы можете воспользоваться пакетом itertools в стандартной библиотеке, который содержит функции для создания итераторов из структур данных. Вы можете использовать его для объединения итераторов в цепочки, отображения структур, циклического или повторного использования существующих итераторов.
Itertools также содержит функции для фильтрации данных, например filterfalse(). Подробнее об Itertools читайте в статье Itertools in Python 3, By Example.
4. Работа со сложными словарями с помощью инструментов запросов
Одним из самых мощных и широко используемых основных типов Python является словарь. Он быстрый, эффективный, масштабируемый и очень гибкий.
Если вы впервые знакомитесь со словарями или думаете, что могли бы использовать их более эффективно, вы можете прочитать Dictionaries in Python для получения дополнительной информации.
У этого есть один важный побочный эффект: когда словари сильно вложены, код, который к ним обращается, тоже становится вложенным.
Возьмем этот пример данных, образец линий токийского метро, который вы видели ранее:
data = {
"network": {
"lines": [
{
"name.en": "Ginza",
"name.jp": "銀座線",
"color": "orange",
"number": 3,
"sign": "G"
},
{
"name.en": "Marunouchi",
"name.jp": "丸ノ内線",
"color": "red",
"number": 4,
"sign": "M"
}
]
}
}
Если бы вы хотели получить строку, соответствующую определенному числу, это можно было бы сделать с помощью небольшой функции:
def find_line_by_number(data, number):
matches = [line for line in data if line['number'] == number]
if len(matches) > 0:
return matches[0]
else:
raise ValueError(f"Line {number} does not exist.")
Несмотря на то, что сама функция небольшая, ее вызов неоправданно усложняется из-за вложенности данных:
>>> find_line_by_number(data["network"]["lines"], 3)
Существуют сторонние инструменты для запроса словарей в Python. Одними из самых популярных являются JMESPath, glom, asq и flupy.
JMESPath может помочь с нашей сетью поездов. JMESPath - это язык запросов, разработанный для JSON, с плагином для Python, который работает со словарями Python. Чтобы установить JMESPath, сделайте следующее:
$ pip install jmespath
Затем откройте Python REPL для изучения API JMESPath, скопировав в словарь data. Чтобы начать работу, импортируйте jmespath и вызовите search() со строкой запроса в качестве первого аргумента и данными в качестве второго. Строка запроса "network.lines" означает возврат data['network']['lines']:
>>> import jmespath
>>> jmespath.search("network.lines", data)
[{'name.en': 'Ginza', 'name.jp': '銀座線',
'color': 'orange', 'number': 3, 'sign': 'G'},
{'name.en': 'Marunouchi', 'name.jp': '丸ノ内線',
'color': 'red', 'number': 4, 'sign': 'M'}]
При работе со списками можно использовать квадратные скобки и указывать внутри них запрос. Запрос "все" - это просто *. Затем вы можете добавить имя атрибута внутри каждого элемента, который нужно вернуть. Если вы хотите получить номер строки для каждой строки, вы можете сделать следующее:
>>> jmespath.search("network.lines[*].number", data)
[3, 4]
Вы можете задавать более сложные запросы, например == или <. Синтаксис немного необычен для разработчиков Python, поэтому держите под рукой документацию для справки.
Если мы хотим найти строку с номером 3, это можно сделать одним запросом:
>>> jmespath.search("network.lines[?number==`3`]", data)
[{'name.en': 'Ginza', 'name.jp': '銀座線', 'color': 'orange', 'number': 3, 'sign': 'G'}]
Если бы мы хотели получить цвет этой линии, можно было бы добавить атрибут в конец запроса:
>>> jmespath.search("network.lines[?number==`3`].color", data)
['orange']
JMESPath можно использовать для сокращения и упрощения кода, выполняющего запросы и поиск в сложных словарях.
5. Использование attrs и dataclasses для сокращения кода
Другая цель рефакторинга - просто сократить количество кода в кодовой базе, добившись при этом тех же характеристик. Приемы, показанные до сих пор, могут значительно помочь в рефакторинге кода в более мелкие и простые модули.
Некоторые другие методы требуют знания стандартной библиотеки и некоторых сторонних библиотек.
Что такое Boilerplate?
Шаблонный код - это код, который должен использоваться во многих местах с небольшими изменениями или вообще без них.
Взяв в качестве примера нашу сеть поездов, если бы мы преобразовали ее в типы, используя классы Python и подсказки типов Python 3, она могла бы выглядеть примерно так:
from typing import List
class Line(object):
def __init__(self, name_en: str, name_jp: str, color: str, number: int, sign: str):
self.name_en = name_en
self.name_jp = name_jp
self.color = color
self.number = number
self.sign = sign
def __repr__(self):
return f"<Line {self.name_en} color='{self.color}' number={self.number} sign='{self.sign}'>"
def __str__(self):
return f"The {self.name_en} line"
class Network(object):
def __init__(self, lines: List[Line]):
self._lines = lines
@property
def lines(self) -> List[Line]:
return self._lines
Теперь, возможно, вы захотите добавить другие магические методы, например .__eq__(). Этот код является шаблонным. Здесь нет бизнес-логики или какой-либо другой функциональности: мы просто копируем данные из одного места в другое.
Дело для dataclasses
Введенный в стандартную библиотеку в Python 3.7, с пакетом backport для Python 3.6 на PyPI, модуль dataclasses может помочь удалить множество шаблонов для этих типов классов, где вы просто храните данные.
Чтобы преобразовать приведенный выше класс Line в класс данных, преобразуйте все поля в атрибуты класса и убедитесь, что они имеют аннотации типов:
from dataclasses import dataclass
@dataclass
class Line(object):
name_en: str
name_jp: str
color: str
number: int
sign: str
Затем вы можете создать экземпляр типа Line с теми же аргументами, что и раньше, с теми же полями, и даже .__str__(), .__repr__() и .__eq__() реализованы:
>>> line = Line('Marunouchi', "丸ノ内線", "red", 4, "M")
>>> line.color
red
>>> line2 = Line('Marunouchi', "丸ノ内線", "red", 4, "M")
>>> line == line2
True
Классы данных - это отличный способ сократить код с помощью одного импорта, который уже есть в стандартной библиотеке. Для получения полного обзора вы можете ознакомиться с The Ultimate Guide to Data Classes in Python 3.7.
Некоторые attrs примеры использования
attrs - это сторонний пакет, который существует гораздо дольше, чем dataclasses. attrs имеет гораздо большую функциональность и доступен на Python 2.7 и 3.4+.
Если вы используете Python 3.5 или ниже, attrs является отличной альтернативой dataclasses. Кроме того, он предоставляет гораздо больше возможностей.
Эквивалентный пример с классами данных в attrs будет выглядеть аналогично. Вместо использования аннотаций типов атрибутам класса присваивается значение из attrib(). Это значение может принимать дополнительные аргументы, такие как значения по умолчанию и обратные вызовы для проверки ввода:
from attr import attrs, attrib
@attrs
class Line(object):
name_en = attrib()
name_jp = attrib()
color = attrib()
number = attrib()
sign = attrib()
attrs может быть полезным пакетом для удаления шаблонного кода и проверки ввода в классах данных.
Заключение
Теперь, когда вы научились определять сложный код и справляться с ним, вспомните, какие шаги вы можете предпринять, чтобы сделать ваше приложение более легким для изменения и управления:
- Начните с создания базовой линии вашего проекта с помощью такого инструмента, как
wily. - Просмотрите некоторые метрики и начните с модуля, который имеет самый низкий индекс ремонтопригодности.
- Переделайте этот модуль, используя безопасность, обеспечиваемую тестами, и знания таких инструментов, как PyCharm и
rope.
После выполнения этих шагов и изучения лучших практик, описанных в этой статье, вы сможете делать другие интересные вещи с вашим приложением, например добавлять новые функции и улучшать производительность.
Вернуться на верх