Непрерывная интеграция в Python
Оглавление
- Что такое непрерывная интеграция?
- Почему мне это важно?
- Основные концепции
- Ваша очередь!
- Следующие шаги
- Обзор сервисов непрерывной интеграции
- Заключение
Когда вы пишете код самостоятельно, единственный приоритет - заставить его работать. Однако работа в команде профессиональных разработчиков программного обеспечения сопряжена с множеством проблем. Одна из таких проблем - координация работы многих людей над одним и тем же кодом.
Как профессиональные команды вносят десятки изменений в день и при этом следят за тем, чтобы все было согласовано и ничего не сломалось? Ввести непрерывную интеграцию!
В этом уроке вы узнаете:
- Узнайте основные концепции, лежащие в основе непрерывной интеграции
- Поймите преимущества непрерывной интеграции
- Настройте базовую систему непрерывной интеграции
- Создайте простой пример на Python и подключите его к системе непрерывной интеграции
Что такое непрерывная интеграция?
Непрерывная интеграция (CI) - это практика частого создания и тестирования каждого изменения, вносимого в код, автоматически и как можно раньше. Известный разработчик и автор Мартин Фаулер определяет CI следующим образом:
"Непрерывная интеграция - это практика разработки программного обеспечения, при которой члены команды интегрируют свою работу часто, обычно каждый человек интегрирует по крайней мере ежедневно, что приводит к нескольким интеграциям в день. Каждая интеграция проверяется автоматизированной сборкой (включая тестирование), чтобы как можно быстрее обнаружить ошибки интеграции." (Источник)
Давайте распакуем это.
Программирование итеративно. Исходный код хранится в репозитории, который является общим для всех членов команды. Если вы хотите работать над этим продуктом, вы должны получить его копию. Вы будете вносить изменения, тестировать их и интегрировать обратно в основной репозиторий. Повторять и повторять.
Не так давно эти интеграции были большими и разделенными неделями (или месяцами), вызывая головную боль, тратя время и теряя деньги. Вооружившись опытом, разработчики стали вносить небольшие изменения и интегрировать их чаще. Это снижает вероятность возникновения конфликтов, которые вам придется решать позже.
После каждой интеграции необходимо собрать исходный код. Сборка означает преобразование вашего высокоуровневого кода в формат, который компьютер знает, как запустить. Наконец, результат систематически тестируется, чтобы убедиться, что ваши изменения не привели к ошибкам.
Почему меня это должно волновать?
На личном уровне непрерывная интеграция - это то, как вы и ваши коллеги проводите свое время.
Используя CI, вы будете тратить меньше времени:
- Не беспокоиться о том, что при каждом изменении вы будете вносить ошибку
- Исправление чужих ошибок, чтобы вы могли интегрировать свой код
- Убедитесь, что код работает на всех машинах, операционных системах и браузерах
И наоборот, вы потратите больше времени:
- Решать интересные проблемы
- Написание потрясающего кода вместе со своей командой
- Создание удивительных продуктов, которые приносят пользу пользователям
Как это звучит?
На уровне команды это позволяет создать лучшую инженерную культуру, где вы предоставляете ценность рано и часто. Сотрудничество поощряется, а ошибки выявляются гораздо раньше. Непрерывная интеграция позволит:
- Сделайте вас и вашу команду быстрее
- Дайте вам уверенность в том, что вы создаете стабильное программное обеспечение с меньшим количеством ошибок
- Убедитесь, что ваш продукт работает на других машинах, а не только на вашем ноутбуке
- Избавьтесь от множества утомительных накладных расходов и сосредоточьтесь на главном
- Сократите время, затрачиваемое на разрешение конфликтов (когда разные люди изменяют один и тот же код)
Основные понятия
Есть несколько ключевых идей и практик, которые необходимо понять, чтобы эффективно работать с непрерывной интеграцией. Кроме того, могут быть некоторые слова и фразы, которые вам незнакомы, но часто используются при разговоре о CI. В этой главе вы познакомитесь с этими понятиями и жаргоном, который с ними связан.
Репозиторий с одним источником
Если вы сотрудничаете с другими людьми над одной базой кода, типичным является наличие общего хранилища исходного кода. Каждый разработчик, работающий над проектом, создает локальную копию и вносит в нее изменения. После того как они удовлетворены изменениями, они сливают их обратно в центральный репозиторий.
Стандартом стало использование систем контроля версий (VCS), таких как Git, которые выполняют этот рабочий процесс за вас. Команды обычно используют внешние сервисы для размещения исходного кода и обработки всех движущихся частей. Наиболее популярными являются GitHub, BitBucket и GitLab.
Git позволяет создавать несколько ответвлений от репозитория. Каждая ветвь является независимой копией исходного кода и может быть изменена без влияния на другие ветви. Это очень важная функция, и большинство команд имеют основную ветку (часто называемую мастер-веткой), которая представляет текущее состояние проекта.
Если вы хотите добавить или изменить код, вам следует создать копию основной ветки и работать в новой, ветке разработки. Как только вы закончите, слейте эти изменения обратно в основную ветку.
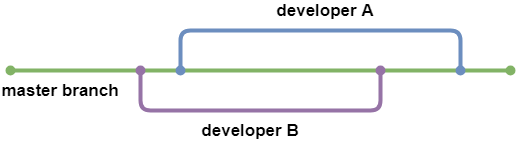
Ветвление в Git
Контроль версий - это не только код. Документация и тестовые сценарии обычно хранятся вместе с исходным кодом. Некоторые программы ищут внешние файлы, используемые для настройки параметров и начальных установок. Другим приложениям нужна схема базы данных. Все эти файлы должны быть в вашем репозитории.
Если вы никогда не пользовались Git'ом или нуждаетесь в курсе, ознакомьтесь с нашей статьей "Введение в Git и GitHub для разработчиков Python" .
Автоматизация сборки
Как уже говорилось ранее, сборка кода означает получение исходного кода и всего необходимого для его выполнения и перевод его в формат, который компьютер может выполнять напрямую. Python - это интерпретированный язык, поэтому его "сборка" в основном сводится к выполнению тестов, а не к компиляции.
Выполнять эти шаги вручную после каждого небольшого изменения очень утомительно и отнимает драгоценное время и внимание от реального решения проблем, которые вы пытаетесь сделать. Большая часть непрерывной интеграции - это автоматизация этого процесса и перемещение его из поля зрения (и из головы).
Что это значит для Python? Подумайте о более сложном фрагменте кода, который вы написали. Если вы использовали библиотеку, пакет или фреймворк, которые не входят в стандартную библиотеку Python (подумайте, что вам нужно установить с помощью pip или conda), Python должен знать об этом, чтобы программа знала, где искать команды, которые она не распознает.
Вы храните список этих пакетов в requirements.txt или Pipfile. Это зависимости вашего кода, которые необходимы для успешной сборки.
Вы часто слышите фразу "сломать сборку". Когда вы ломаете сборку, это означает, что вы внесли изменение, которое сделало конечный продукт непригодным для использования. Не волнуйтесь. Такое случается со всеми, даже с закаленными в боях старшими разработчиками. Вы хотите избежать этого прежде всего потому, что это помешает всем остальным работать.
Весь смысл CI в том, чтобы все работали на известной стабильной базе. Если они клонируют репозиторий, который ломает сборку, они будут работать с неработающей версией кода и не смогут внедрить или протестировать свои изменения. Когда вы ломаете сборку, главным приоритетом является ее исправление, чтобы все могли возобновить работу.
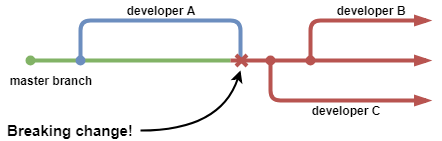
Внесение изменений в мастер-ветку
Когда сборка автоматизирована, вам рекомендуется делать коммит часто, обычно несколько раз в день. Это позволяет людям быстро узнавать об изменениях и замечать, если между двумя разработчиками возник конфликт. Если вместо нескольких масштабных обновлений будет множество мелких изменений, гораздо проще определить, где возникла ошибка. Это также будет стимулировать вас разбивать свою работу на более мелкие фрагменты, которые легче отслеживать и тестировать.
Автоматизированное тестирование
Поскольку все вносят изменения по несколько раз в день, важно знать, что ваше изменение не сломало ничего другого в коде и не внесло ошибок. Во многих компаниях тестирование теперь является обязанностью каждого разработчика. Если вы пишете код, вы должны писать тесты. Как минимум, вы должны покрывать каждую новую функцию юнит-тестом.
Автоматическое выполнение тестов при фиксации каждого изменения - отличный способ выявить ошибки. Неудачный тест автоматически приводит к неудаче сборки. Это привлечет ваше внимание к проблемам, выявленным тестированием, а неудачная сборка заставит вас исправить ошибку, которую вы внесли. Тесты не гарантируют, что ваш код не содержит ошибок, но они защищают от множества небрежных изменений.
Автоматизация выполнения тестов дает вам некоторое спокойствие, поскольку вы знаете, что сервер будет тестировать ваш код при каждой фиксации, даже если вы забыли сделать это локально.
Использование внешнего сервиса непрерывной интеграции
Если что-то работает на вашем компьютере, будет ли оно работать на всех компьютерах? Скорее всего, нет. Это клишированное оправдание и своего рода внутренняя шутка среди разработчиков - говорить: "Ну, это работало на моей машине!". Заставить код работать локально - это еще не конец вашей ответственности.
Для решения этой проблемы большинство компаний используют внешний сервис для интеграции, подобно тому, как GitHub используется для размещения репозитория исходного кода. У внешних служб есть серверы, на которых они собирают код и проводят тесты. Они выступают в роли мониторов для вашего репозитория и не позволяют никому сливаться в мастер-ветку, если их изменения нарушают сборку.
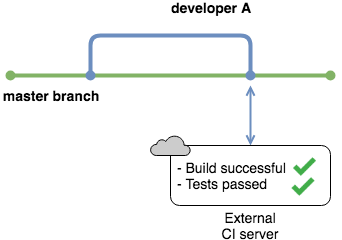
Слияние изменений запускает CI-сервер
Сейчас существует множество подобных сервисов с различными возможностями и ценами. Большинство из них имеют бесплатный уровень, чтобы вы могли поэкспериментировать с одним из своих репозиториев. Вы будете использовать сервис под названием CircleCI в одном из примеров далее в учебнике.
Тестирование в среде Staging Environment
Производственная среда - это то место, где в конечном итоге будет работать ваше программное обеспечение. Даже после успешной сборки и тестирования приложения вы не можете быть уверены, что ваш код будет работать на целевом компьютере. Именно поэтому команды развертывают конечный продукт в среде, которая имитирует производственную среду. Как только вы убедитесь, что все работает, приложение развертывается в производственной среде.
Примечание: Этот шаг больше относится к коду приложений, чем к коду библиотек. Любые написанные вами библиотеки Python все равно необходимо протестировать на сервере сборки, чтобы убедиться, что они работают в среде, отличной от среды вашего локального компьютера.
Вы можете услышать, как люди говорят об этом клоне производственной среды, используя такие термины, как среда разработки, среда постановки или среда тестирования. Обычно используются такие сокращения, как DEV для среды разработки и PROD для производственной среды.
Среда разработки должна как можно точнее повторять производственные условия. Такую настройку часто называют DEV/PROD parity. Поддерживайте на своем локальном компьютере среду, максимально похожую на среды DEV и PROD, чтобы свести к минимуму аномалии при развертывании приложений.
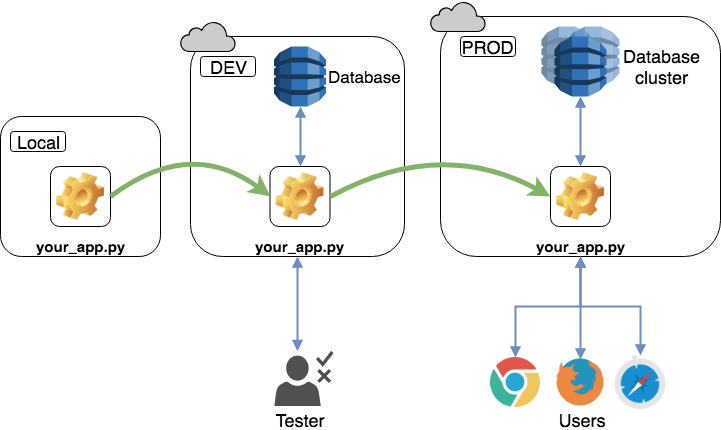
Тестирование в клонах производственной среды
Мы упомянули об этом, чтобы познакомить вас с лексиконом, но постоянное развертывание программного обеспечения на DEV и PROD - это совсем другая тема. Этот процесс, что неудивительно, называется непрерывным развертыванием (CD). Вы можете найти больше ресурсов о нем в разделе "Следующие шаги" этой статьи.
Ваша очередь!
Лучший способ научиться - это делать. Теперь вы понимаете все основные принципы непрерывной интеграции, так что пришло время испачкать руки и создать целую цепочку шагов, необходимых для использования CI. Эту цепочку часто называют CI pipeline.
Это практическое руководство, поэтому запустите свой редактор и приготовьтесь выполнять эти шаги по мере чтения!
Мы предполагаем, что вы знаете основы Python и Git. Мы будем использовать Github в качестве хостинга и CircleCI в качестве внешнего сервиса непрерывной интеграции. Если у вас нет аккаунтов в этих сервисах, зарегистрируйтесь. У обоих есть бесплатные уровни!
Определение проблемы
Помните, что вы сосредоточились на добавлении нового инструмента к своему поясу - непрерывной интеграции. Для этого примера сам код на Python будет простым. Вы хотите потратить большую часть своего времени на освоение шагов по созданию конвейера, а не на написание сложного кода.
Представьте, что ваша команда работает над простым приложением-калькулятором. Ваша задача - написать библиотеку базовых математических функций: сложение, вычитание, умножение и деление. Вас не волнует фактическое приложение, потому что именно его будут разрабатывать ваши коллеги, используя функции из вашей библиотеки.
Создать репо
Войдите в свой аккаунт на GitHub, создайте новый репозиторий и назовите его CalculatorLibrary. Добавьте README и .gitignore, а затем клонируйте репозиторий на свою локальную машину. Если вам нужна дополнительная помощь в этом процессе, посмотрите на walkthrough от GitHub о создании нового репозитория.
Создание рабочей среды
Чтобы другие (и CI-сервер) могли воспроизвести ваши условия работы, необходимо создать окружение. Создайте виртуальную среду где-нибудь за пределами вашего репозитория и активируйте ее:
$ # Create virtual environment
$ python3 -m venv calculator
$ # Activate virtual environment (Mac and Linux)
$ . calculator/bin/activate
Предыдущие команды работают на macOS и Linux. Если вы являетесь пользователем Windows, проверьте таблицу Platforms в официальной документации. Это создаст каталог, содержащий установку Python, и укажет интерпретатору использовать его. Теперь мы можем устанавливать пакеты, зная, что это не повлияет на стандартную установку Python в вашей системе.
Напишите простой пример на Python
Создайте новый файл с именем calculator.py в каталоге верхнего уровня вашего репозитория и скопируйте следующий код:
"""
Calculator library containing basic math operations.
"""
def add(first_term, second_term):
return first_term + second_term
def subtract(first_term, second_term):
return first_term - second_term
Это пример, содержащий две из четырех функций, которые мы будем писать. Как только мы запустим наш CI-конвейер, вы добавите оставшиеся две функции.
Продолжайте фиксировать эти изменения:
$ # Make sure you are in the correct directory
$ cd CalculatorLibrary
$ git add calculator.py
$ git commit -m "Add functions for addition and subtraction"
В вашей папке CalculatorLibrary сейчас должны быть следующие файлы:
CalculatorLibrary/
|
├── .git
├── .gitignore
├── README.md
└── calculator.py
Отлично, вы выполнили одну часть требуемой функциональности. Следующий шаг - добавление тестов, чтобы убедиться, что ваш код работает так, как должен.
Напишите модульные тесты
Вы протестируете свой код в два этапа.
Первый шаг включает в себя линтинг - запуск программы, называемой линтером, для анализа кода на предмет потенциальных ошибок. flake8 обычно используется для проверки соответствия вашего кода стандартному стилю кодирования Python. Линтинг позволяет убедиться, что ваш код легко читается остальными членами сообщества Python.
Вторым шагом является модульное тестирование. Юнит-тест предназначен для проверки одной функции, или блока, кода. Python поставляется со стандартной библиотекой модульного тестирования, но существуют и другие библиотеки, которые очень популярны. В этом примере используется pytest.
Стандартной практикой, которая идет рука об руку с тестированием, является подсчет покрытия кода. Покрытие кода - это процент исходного кода, который "покрывается" вашими тестами. У pytest есть расширение pytest-cov, которое поможет вам понять покрытие кода.
Это внешние зависимости, и вам необходимо установить их:
$ pip install flake8 pytest pytest-cov
Это единственные внешние пакеты, которые вы будете использовать. Обязательно сохраните эти зависимости в файле requirements.txt, чтобы другие могли повторить ваше окружение:
$ pip freeze > requirements.txt
Чтобы запустить свой линтер, выполните следующее:
$ flake8 --statistics
./calculator.py:3:1: E302 expected 2 blank lines, found 1
./calculator.py:6:1: E302 expected 2 blank lines, found 1
2 E302 expected 2 blank lines, found 1
Опция --statistics дает представление о том, сколько раз произошла та или иная ошибка. Здесь у нас два нарушения PEP 8, потому что flake8 ожидает две пустые строки перед определением функции вместо одной. Добавьте пустую строку перед каждым определением функции. Запустите flake8 снова, чтобы проверить, что сообщения об ошибках больше не появляются.
Теперь пришло время написать тесты. Создайте файл с именем test_calculator.py в каталоге верхнего уровня вашего репозитория и скопируйте следующий код:
"""
Unit tests for the calculator library
"""
import calculator
class TestCalculator:
def test_addition(self):
assert 4 == calculator.add(2, 2)
def test_subtraction(self):
assert 2 == calculator.subtract(4, 2)
Эти тесты позволяют убедиться, что наш код работает так, как ожидалось. Они далеко не обширны, потому что вы не проверили потенциальное использование вашего кода, но пока держите их простыми.
Следующая команда запускает ваш тест:
$ pytest -v --cov
collected 2 items
test_calculator.py::TestCalculator::test_addition PASSED [50%]
test_calculator.py::TestCalculator::test_subtraction PASSED [100%]
---------- coverage: platform darwin, python 3.6.6-final-0 -----------
Name Stmts Miss Cover
---------------------------------------------------------------------
calculator.py 4 0 100%
test_calculator.py 6 0 100%
/Users/kristijan.ivancic/code/learn/__init__.py 0 0 100%
---------------------------------------------------------------------
TOTAL 10 0 100%
pytest отлично справляется с обнаружением тестов. Поскольку у вас есть файл с префиксом test, pytest знает, что он будет содержать модульные тесты для выполнения. Те же принципы применимы к именам классов и методов внутри файла.
Флаг -v дает более приятный вывод, говорящий о том, какие тесты прошли, а какие нет. В нашем случае оба теста прошли. Флаг --cov обеспечивает выполнение pytest-cov и дает отчет о покрытии кода для calculator.py.
Вы завершили подготовку. Зафиксируйте тестовый файл и перенесите все изменения в основную ветку:
$ git add test_calculator.py
$ git commit -m "Add unit tests for calculator"
$ git push
После завершения этого раздела в вашей папке CalculatorLibrary должны быть следующие файлы:
CalculatorLibrary/
|
├── .git
├── .gitignore
├── README.md
├── calculator.py
├── requirements.txt
└── test_calculator.py
Превосходно, обе ваши функции проверены и работают правильно.
Подключиться к CircleCI
Наконец-то вы готовы к настройке конвейера непрерывной интеграции!
CircleCI необходимо знать, как запустить вашу сборку, и ожидает, что эта информация будет предоставлена в определенном формате. Для этого требуется папка .circleci в вашем репозитории и конфигурационный файл в ней. Файл конфигурации содержит инструкции для всех шагов, которые должен выполнить сервер сборки. CircleCI ожидает, что этот файл будет называться config.yml.
Файл .yml использует язык сериализации данных, YAML, и у него есть своя спецификация. Цель YAML - быть человекочитаемым и хорошо работать с современными языками программирования для решения обычных, повседневных задач.
В файле YAML есть три основных способа представления данных:
- Сопоставления (пары ключ-значение)
- Последовательности (списки)
- Скаляры (строки или числа)
Читать очень просто:
- Интенция может быть использована для структурирования.
- Двоеточия разделяют пары ключ-значение.
- Тире используются для создания списков.
Создайте папку .circleci в вашем репо и файл config.yml со следующим содержимым:
# Python CircleCI 2.0 configuration file
version: 2
jobs:
build:
docker:
- image: circleci/python:3.7
working_directory: ~/repo
steps:
# Step 1: obtain repo from GitHub
- checkout
# Step 2: create virtual env and install dependencies
- run:
name: install dependencies
command: |
python3 -m venv venv
. venv/bin/activate
pip install -r requirements.txt
# Step 3: run linter and tests
- run:
name: run tests
command: |
. venv/bin/activate
flake8 --exclude=venv* --statistics
pytest -v --cov=calculator
Некоторые из этих слов и понятий могут быть вам незнакомы. Например, что такое Docker и что такое образы? Давайте немного вернемся в прошлое.
Помните проблему, с которой сталкиваются программисты, когда что-то работает на их ноутбуке, но нигде больше? Раньше разработчики создавали программу, которая изолировала часть физических ресурсов компьютера (память, жесткий диск и так далее) и превращала их в виртуальную машину.
Виртуальная машина притворяется целым компьютером сама по себе. У нее даже есть своя операционная система. На этой операционной системе вы развертываете свое приложение или устанавливаете библиотеку и тестируете ее.
Виртуальные машины занимают много ресурсов, что послужило толчком к изобретению контейнеров. Идея аналогична транспортным контейнерам. До изобретения контейнеров производителям приходилось перевозить товары самых разных размеров, в разной упаковке и разными способами (грузовики, поезда, корабли).
Благодаря стандартизации транспортного контейнера эти товары можно было перемещать между различными способами транспортировки без каких-либо изменений. Та же идея применима и к контейнерам для программного обеспечения.
Контейнеры - это легковесные единицы кода и его зависимостей во время выполнения, упакованные стандартным образом, чтобы их можно было быстро подключить и запустить в ОС Linux. Вам не нужно создавать целую виртуальную операционную систему, как в случае с виртуальной машиной.
Контейнеры копируют только те части операционной системы, которые необходимы им для работы. Это уменьшает их размер и дает большой прирост производительности.
Docker в настоящее время является ведущей контейнерной платформой, и она даже может запускать контейнеры Linux на Windows и macOS. Чтобы создать контейнер Docker, вам нужен образ Docker. Образы служат образцами для контейнеров так же, как классы служат образцами для объектов. Подробнее о Docker можно прочитать в руководстве Get Started.
CircleCI поддерживает предварительно собранные Docker-образы для нескольких языков программирования. В приведенном выше файле конфигурации вы указали образ Linux, на котором уже установлен Python. Этот образ создаст контейнер, в котором будет происходить все остальное.
Давайте рассмотрим каждую строку конфигурационного файла по очереди:
-
version: Каждыйconfig.ymlначинается с номера версии CircleCI, используемого для выдачи предупреждений о ломающих изменениях. -
jobs: Задания представляют собой одно выполнение сборки и определяются набором шагов. Если у вас только одно задание, оно должно называтьсяbuild. -
build: Как уже говорилось,build- это имя вашего задания. У вас может быть несколько заданий, в этом случае они должны иметь уникальные имена. -
docker: Шаги задания происходят в среде, называемой исполнителем. Обычным исполнителем в CircleCI является контейнер Docker. Это cloud-hosted среда выполнения, но существуют и другие варианты, например, среда macOS. -
image: Образ Docker - это файл, используемый для создания работающего контейнера Docker. Мы используем образ с предустановленным Python 3.7. -
working_directory: Ваш репозиторий должен быть проверен где-то на сервере сборки. Рабочая директория представляет собой путь к файлу, где будет храниться репозиторий. -
steps: Этот ключ обозначает начало списка шагов, которые должен выполнить сервер сборки. -
checkout: Первое, что должен сделать сервер, - это проверить исходный код в рабочем каталоге. Это выполняется специальным шагом, который называется checkout. -
run:Выполнение программ или команд командной строки происходит внутри клавиши command. Фактические команды оболочки будут вложены внутрь. -
name:Пользовательский интерфейс CircleCI показывает каждый шаг сборки в виде расширяемой секции. Заголовок раздела берется из значения, связанного с ключом name. -
command: Этот ключ представляет собой команду для запуска через оболочку. Символ | указывает на то, что последующие действия являются буквальным набором команд, по одной в строке, точно так же, как в сценарии shell/bash.
Для получения дополнительной информации вы можете ознакомиться с документом CircleCI configuration reference.
Наш конвейер очень прост и состоит из 3 этапов:
- Проверка репозитория
- Установка зависимостей в виртуальной среде
- Запуск линтера и тестов в виртуальной среде
Теперь у нас есть все необходимое для запуска трубопровода. Войдите в свою учетную запись CircleCI и нажмите Add Projects. Найдите репозиторий CalculatorLibrary и нажмите Set Up Project. Выберите Python в качестве языка. Поскольку у нас уже есть config.yml, мы можем пропустить следующие шаги и нажать Start building.
CircleCI переведет вас на панель выполнения задания. Если вы правильно выполнили все шаги, вы должны увидеть, что ваше задание успешно выполнено.
Окончательная версия вашей папки CalculatorLibrary должна выглядеть так:
CalculatorRepository/
|
├── .circleci
├── .git
├── .gitignore
├── README.md
├── calculator.py
├── requirements.txt
└── test_calculator.py
Поздравляем! Вы создали свой первый конвейер непрерывной интеграции. Теперь каждый раз, когда вы делаете push в мастер-ветку, будет запускаться задание. Вы можете просмотреть список текущих и прошлых заданий, нажав на Jobs в боковой панели CircleCI.
Внести изменения
Пора добавить умножение в нашу библиотеку калькуляторов.
На этот раз мы сначала добавим юнит-тест без написания функции. Без кода тест будет провален, что также приведет к провалу задания CircleCI. Добавьте следующий код в конец вашего test_calculator.py:
def test_multiplication(self):
assert 100 == calculator.multiply(10, 10)
Выложите код в мастер-ветку и увидите, как задание провалится в CircleCI. Это показывает, что непрерывная интеграция работает и прикрывает вашу спину, если вы допустили ошибку.
Теперь добавьте в calculator.py код, который заставит тест пройти:
def multiply(first_term, second_term):
return first_term * second_term
Убедитесь, что между функцией умножения и предыдущей функцией есть два пустых пробела, иначе ваш код не пройдет проверку linter.
На этот раз работа должна быть успешной. Такая схема работы, при которой сначала пишется неудачный тест, а затем добавляется код для его прохождения, называется разработка, управляемая тестами (TDD). Это отличный способ работы, потому что он заставляет вас заранее продумывать структуру кода.
Теперь попробуйте сделать это самостоятельно. Добавьте тест для функции деления, посмотрите, как он не работает, и напишите функцию, чтобы тест прошел.
Уведомления
При работе над большими приложениями с большим количеством движущихся частей может потребоваться время для выполнения задания непрерывной интеграции. Большинство команд устанавливают процедуру оповещения, чтобы знать, если одно из заданий не выполняется. Они могут продолжать работу в ожидании выполнения задания.
Наиболее популярными вариантами являются:
- Отправка электронного письма для каждой неудачной сборки
- Отправка уведомлений о сбоях на канал Slack
- Отображение сбоев на приборной панели, видимой для всех
По умолчанию CircleCI должен отправлять вам электронное письмо, когда задание не выполнено.
Следующие шаги
Вы разобрались в основах непрерывной интеграции и попрактиковались в настройке конвейера для простой программы на Python. Это большой шаг вперед на вашем пути разработчика. Возможно, вы спрашиваете себя: "Что дальше?"
Чтобы не усложнять ситуацию, в этом руководстве мы обошли несколько важных тем. Вы можете значительно расширить свой набор навыков, потратив некоторое время на более глубокое изучение каждой темы. Вот некоторые темы, которые вы можете изучить подробнее.
Git Workflows
В Git'е есть гораздо больше, чем то, что вы использовали здесь. У каждой команды разработчиков есть свой рабочий процесс, отвечающий их специфическим потребностям. Большинство из них включает в себя стратегии ветвления и то, что называется peer review. Они вносят изменения в ветки, отдельные от ветки master. Когда вы хотите слить эти изменения с веткой master, другие разработчики должны сначала посмотреть на ваши изменения и одобрить их, прежде чем вы получите разрешение на слияние.
Примечание: Если вы хотите узнать больше о различных рабочих процессах, используемых командами, посмотрите учебники по GitHub и BitBucket.
Если вы хотите отточить свои навыки работы с Git, у нас есть статья Advanced Git Tips for Python Developers.
Управление зависимостями и виртуальные среды
Помимо virtualenv, существуют и другие популярные менеджеры пакетов и окружения. Некоторые из них работают только с виртуальными средами, а некоторые - и с установкой пакетов, и с управлением средами. Один из них - Conda:
"Conda - это система управления пакетами с открытым исходным кодом и система управления окружением, которая работает под Windows, macOS и Linux. Conda быстро устанавливает, запускает и обновляет пакеты и их зависимости. Conda легко создает, сохраняет, загружает и переключается между окружениями на вашем локальном компьютере. Она была разработана для программ на Python, но может упаковывать и распространять программы для любого языка." (Источник)
Другой вариант - Pipenv, более молодой соперник, который набирает популярность среди разработчиков приложений. Pipenv объединяет pip и virtualenv в один инструмент и использует Pipfile вместо requirements.txt. Pipfiles предлагает детерминированное окружение и большую безопасность. Это введение не делает его справедливым, поэтому ознакомьтесь с Pipenv: A Guide to the New Python Packaging Tool.
Тестирование
Простые модульные тесты с pytest - это только вершина айсберга. Существует целый мир, который нужно исследовать! Программное обеспечение можно тестировать на многих уровнях, включая интеграционное тестирование, приемочное тестирование, регрессионное тестирование и так далее. Чтобы поднять свои знания о тестировании кода на Python на новый уровень, перейдите по ссылке Getting Started With Testing in Python.
Упаковка
В этом уроке вы начали создавать библиотеку функций, которые другие разработчики могут использовать в своих проектах. Вам нужно упаковать эту библиотеку в формат, который легко распространять и устанавливать, например, pip.
Создание устанавливаемого пакета требует другого оформления и некоторых дополнительных файлов, таких как __init__.py и setup.py. Прочитайте Python Application Layouts: A Reference для получения дополнительной информации о структурировании кода.
Чтобы узнать, как превратить ваш репозиторий в устанавливаемый пакет Python, прочитайте Packaging Python Projects от Python Packaging Authority.
Непрерывное интегрирование
В этом уроке вы рассмотрели все основы CI на простом примере кода на Python. Обычно на последнем этапе конвейера CI создается развертываемый артефакт. Артефакт представляет собой законченную, упакованную единицу работы, которая готова к развертыванию для пользователей или включению в состав сложных продуктов.
Например, чтобы превратить библиотеку калькуляторов в развертываемый артефакт, вы организуете ее в устанавливаемый пакет. Наконец, вы добавите шаг в CircleCI, чтобы упаковать библиотеку и сохранить этот артефакт там, где другие процессы смогут его взять.
Для более сложных приложений можно создать рабочий процесс, чтобы запланировать и связать несколько заданий CI в одно выполнение. Не стесняйтесь изучать документацию CircleCI.
Непрерывное развертывание
Можно рассматривать непрерывное развертывание как расширение CI. После того как ваш код протестирован и собран в артефакт, пригодный для развертывания, он развертывается в производство, то есть живое приложение обновляется с учетом ваших изменений. Одной из целей является минимизация времени выполнения - времени, прошедшего с момента написания новой строки кода до ее представления пользователям.
Примечание: Чтобы добавить немного путаницы, акроним CD не является уникальным. Она также может означать Continuous Delivery, что почти то же самое, что и непрерывное развертывание, но с ручным шагом проверки между интеграцией и развертыванием. Вы можете интегрировать свой код в любое время, но должны нажать кнопку, чтобы выпустить его в живое приложение.
Большинство компаний используют CI/CD в тандеме, поэтому стоит потратить время, чтобы узнать больше о Continuous Delivery/Deployment.
Обзор сервисов непрерывной интеграции
Вы использовали CircleCI, один из самых популярных сервисов непрерывной интеграции. Однако это большой рынок с множеством сильных соперников. Продукты CI делятся на две основные категории: удаленные и самостоятельные сервисы.
Jenkins - самое популярное решение для самостоятельного хостинга. Он обладает открытым исходным кодом и гибкостью, а сообщество разработало множество расширений.
Что касается удаленных сервисов, то существует множество популярных вариантов, таких как TravisCI, CodeShip и Semaphore. Крупные предприятия часто имеют свои собственные решения и продают их в виде услуг, например AWS CodePipeline, Microsoft Team Foundation Server и Hudson от Oracle.
Какой вариант вы выберете, зависит от платформы и функций, которые нужны вам и вашей команде. Для более подробного описания посмотрите статью Лучшее программное обеспечение для CI от G2Crowd.
Заключение
Теперь, получив знания из этого руководства, вы можете ответить на следующие вопросы:
- Что такое непрерывная интеграция?
- Почему важна непрерывная интеграция?
- Каковы основные практики непрерывной интеграции?
- Как настроить непрерывную интеграцию для моего Python-проекта?
Вы приобрели суперспособность программирования! Понимание философии и практики непрерывной интеграции сделает вас ценным членом любой команды. Отличная работа!
Вернуться на верх