Введение в многопоточность Python
Оглавление
- Что такое поток?
- Запуск потока
- Работа со многими потоками
- Использование ThreadPoolExecutor
- Условия гонки
- Базовая синхронизация с помощью блокировки
- Тупиковая ситуация
- Потоковая передача производитель-потребитель
- Объекты потоковой обработки
- Заключение: Потоковая обработка в Python
Потоковая обработка в Python позволяет параллельно выполнять различные части программы и может упростить ее разработку. Если у вас есть некоторый опыт работы с Python и вы хотите ускорить работу своей программы с помощью потоков, то этот учебник для вас!
В этой статье вы узнаете:
- Что такое потоки
- Как создавать потоки и ждать их завершения
- Как использовать
ThreadPoolExecutor - Как избежать условий гонки
- Как использовать общие инструменты, которые предоставляет Python
threading
В этой статье предполагается, что вы уже знакомы с основами Python и используете версию не ниже 3.6 для выполнения примеров. Если вам нужно освежить знания, вы можете начать с Python Learning Paths и войти в курс дела.
Если вы не уверены, хотите ли вы использовать Python threading, asyncio или multiprocessing, то вы можете ознакомиться с Speed Up Your Python Program With Concurrency.
Все исходники, используемые в этом руководстве, доступны вам в репозитории Real Python GitHub.
Бесплатный бонус: 5 Thoughts On Python Mastery - бесплатный курс для разработчиков на Python, который покажет вам дорожную карту и образ мышления, необходимые для того, чтобы поднять ваши навыки работы на Python на новый уровень.
Пройдите тест: Проверьте свои знания с помощью нашего интерактивного теста "Python Threading". По завершении вы получите оценку, чтобы отслеживать прогресс в обучении с течением времени:
Что такое поток?
Поток - это отдельный поток выполнения. Это означает, что в вашей программе будут одновременно выполняться две задачи. Но в большинстве реализаций Python 3 различные потоки на самом деле не выполняются одновременно: они лишь кажутся таковыми.
Заманчиво думать о потоках как о двух (или более) различных процессорах, работающих с вашей программой, каждый из которых выполняет независимую задачу в одно и то же время. Это почти верно. Потоки могут быть запущены на разных процессорах, но одновременно они будут выполняться только по одному.
Для одновременного выполнения нескольких задач требуется нестандартная реализация Python, написание части кода на другом языке или использование multiprocessing, что влечет за собой дополнительные накладные расходы.
Из-за того, как работает реализация Python в CPython, использование потоков может ускорить не все задачи. Это связано с взаимодействием с GIL, которое, по сути, ограничивает одновременный запуск одного потока Python.
Задачи, которые проводят большую часть времени в ожидании внешних событий, обычно являются хорошими кандидатами для организации потоков. Задачи, требующие тяжелых вычислений на процессоре и тратящие мало времени на ожидание внешних событий, могут вообще не работать быстрее.
Это справедливо для кода, написанного на Python и выполняющегося на стандартной реализации CPython. Если ваши потоки написаны на C, они могут освободить GIL и работать параллельно. Если вы работаете на другой реализации Python, проверьте в документации, как она работает с потоками.
Если вы используете стандартную реализацию Python, пишете только на Python и столкнулись с проблемой нехватки процессора, вам стоит обратить внимание на модуль multiprocessing.
Архитектура вашей программы для использования потоков также может дать выигрыш в ясности проектирования. Большинство примеров, с которыми вы познакомитесь в этом учебнике, не обязательно будут работать быстрее из-за использования потоков. Использование потоков в них помогает сделать дизайн чище и проще для рассуждений.
Итак, давайте перестанем говорить о резьбе и начнем ее использовать!
Запуск потока
Теперь, когда вы имеете представление о том, что такое нить, давайте научимся ее создавать. Стандартная библиотека Python предоставляет модуль threading, который содержит большинство примитивов, с которыми вы познакомитесь в этой статье. Thread в этом модуле красиво инкапсулирует потоки, предоставляя чистый интерфейс для работы с ними.
Чтобы запустить отдельный поток, вы создаете экземпляр Thread, а затем говорите ему .start():
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
logging.info("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,))
logging.info("Main : before running thread")
x.start()
logging.info("Main : wait for the thread to finish")
# x.join()
logging.info("Main : all done")
Если вы посмотрите вокруг записи в журнал, то увидите, что раздел main создает и начинает поток:
x = threading.Thread(target=thread_function, args=(1,))
x.start()
Когда вы создаете поток, вы передаете ему функцию Thread и список, содержащий аргументы этой функции. В данном случае вы указываете Thread выполнить thread_function() и передать ей 1 в качестве аргумента.
В этой статье вы будете использовать последовательные целые числа в качестве имен для потоков. Существует threading.get_ident(), который возвращает уникальное имя для каждого потока, но оно обычно не бывает ни коротким, ни легко читаемым.
thread_function() сам по себе мало что дает. Он просто регистрирует несколько сообщений с символом time.sleep() между ними.
Когда вы запустите эту программу в ее нынешнем виде (с закомментированной двадцатой строкой), вывод будет выглядеть так:
$ ./single_thread.py
Main : before creating thread
Main : before running thread
Thread 1: starting
Main : wait for the thread to finish
Main : all done
Thread 1: finishing
Вы заметите, что Thread завершился после того, как завершился раздел Main вашего кода. Вы вернетесь к вопросу о том, почему это так, и поговорите о загадочной двадцатой строке в следующем разделе.
Фоновые потоки
В информатике daemon - это процесс, который выполняется в фоновом режиме.
Python threading имеет более конкретное значение daemon. Поток daemon немедленно завершается при выходе из программы. Один из способов осмыслить эти определения - считать поток daemon потоком, который работает в фоновом режиме, не заботясь о его завершении.
Если в программе запущены Threads, которые не являются daemons, то программа будет ждать завершения этих потоков, прежде чем завершится. Threads, которые являются демонами, однако, просто убиваются, где бы они ни находились, когда программа завершается.
Давайте посмотрим на вывод вашей программы чуть внимательнее. Интересны последние две строки. Когда вы запустите программу, то заметите, что после того, как __main__ выведет свое all done сообщение, и до того, как поток завершится, возникает пауза (около 2 секунд).
Эта пауза - это ожидание Python завершения работы недемонического потока. Когда ваша программа Python завершается, частью процесса завершения является очистка рутины потоков.
Если вы посмотрите на исходный текст Python threading, то увидите, что threading._shutdown() проходит по всем запущенным потокам и вызывает .join() на каждом, у которого не установлен флаг daemon.
Таким образом, ваша программа ожидает выхода, потому что сам поток находится в состоянии сна. Как только он завершит работу и напечатает сообщение, .join() вернется, и программа сможет выйти.
Часто такое поведение - это то, что вам нужно, но у нас есть и другие возможности. Давайте сначала повторим программу с потоком daemon. Для этого нужно изменить способ построения Thread, добавив флаг daemon=True:
x = threading.Thread(target=thread_function, args=(1,), daemon=True)
Запустив программу сейчас, вы должны увидеть такой вывод:
$ ./daemon_thread.py
Main : before creating thread
Main : before running thread
Thread 1: starting
Main : wait for the thread to finish
Main : all done
Разница в том, что в выводе отсутствует последняя строка. У thread_function() не было возможности завершить работу. Это был daemon поток, поэтому, когда __main__ достиг конца своего кода и программа захотела завершиться, демон был убит.
join() потока
Потоки демона удобны, но как быть, когда нужно дождаться остановки потока? Как быть, если вы хотите сделать это и не выходить из программы? Теперь давайте вернемся к вашей исходной программе и посмотрим на закомментированную двадцатую строку:
# x.join()
Чтобы сказать одному потоку подождать завершения другого потока, вы вызываете .join(). Если вы не будете комментировать эту строку, главный поток приостановится и будет ждать, пока поток x завершит выполнение.
Вы проверяли это на коде с потоком демона или обычным потоком? Оказалось, что это не имеет значения. Если вы .join() запустите поток, то это утверждение будет ждать, пока не завершится любой из типов потоков.
Работа с большим количеством потоков
До сих пор код примера работал только с двумя потоками: основным потоком и потоком, который вы запустили с помощью объекта threading.Thread.
Нередко вы хотите запустить несколько потоков и поручить им интересную работу. Давайте начнем с рассмотрения более сложного способа сделать это, а затем перейдем к более простому методу.
Более сложный способ запуска нескольких потоков - тот, который вы уже знаете:
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
threads = list()
for index in range(3):
logging.info("Main : create and start thread %d.", index)
x = threading.Thread(target=thread_function, args=(index,))
threads.append(x)
x.start()
for index, thread in enumerate(threads):
logging.info("Main : before joining thread %d.", index)
thread.join()
logging.info("Main : thread %d done", index)
Этот код использует тот же механизм, который вы видели выше, чтобы запустить поток, создать объект Thread, а затем вызвать .start(). Программа сохраняет список объектов Thread, чтобы затем ожидать их с помощью .join().
Многократное выполнение этого кода, вероятно, приведет к интересным результатам. Вот пример вывода с моей машины:
$ ./multiple_threads.py
Main : create and start thread 0.
Thread 0: starting
Main : create and start thread 1.
Thread 1: starting
Main : create and start thread 2.
Thread 2: starting
Main : before joining thread 0.
Thread 2: finishing
Thread 1: finishing
Thread 0: finishing
Main : thread 0 done
Main : before joining thread 1.
Main : thread 1 done
Main : before joining thread 2.
Main : thread 2 done
Если вы внимательно просмотрите вывод, то увидите, что все три потока начинаются в том порядке, в котором вы ожидаете, но в данном случае они заканчиваются в обратном порядке! При многократном запуске порядок будет отличаться. Ищите сообщение Thread x: finishing, которое подскажет вам, когда каждый поток закончил работу.
Порядок выполнения потоков определяется операционной системой и может быть довольно трудно предсказуем. Он может (и, скорее всего, будет) меняться от выполнения к выполнению, поэтому вам необходимо учитывать это при разработке алгоритмов, использующих потоки.
К счастью, Python предоставляет вам несколько примитивов, которые вы рассмотрите позже, чтобы помочь скоординировать потоки и заставить их работать вместе. Но прежде давайте рассмотрим, как сделать управление группой потоков немного проще.
Использование ThreadPoolExecutor
Существует более простой способ создания группы потоков, чем тот, который вы видели выше. Он называется ThreadPoolExecutor и является частью стандартной библиотеки в concurrent.futures (начиная с Python 3.2).
Ознакомтесь с детальным руководством ThreadPoolExecutor в Python: полное руководство
Проще всего создать его в качестве менеджера контекста, используя оператор with для управления созданием и уничтожением пула.
Вот __main__ из последнего примера, переписанный для использования ThreadPoolExecutor:
import concurrent.futures
# [rest of code]
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
executor.map(thread_function, range(3))
Код создает ThreadPoolExecutor в качестве менеджера контекста, указывая ему, сколько рабочих потоков он хочет иметь в пуле. Затем он использует .map() для прохождения через итерабель вещей, в вашем случае range(3), передавая каждую из них потоку в пуле.
По окончании блока with блок ThreadPoolExecutor выполняет .join() на каждом из потоков в пуле. Настоятельно рекомендуется использовать ThreadPoolExecutor в качестве менеджера контекста, когда это возможно, чтобы никогда не забывать .join() о потоках.
Примечание: Использование ThreadPoolExecutor может привести к возникновению непонятных ошибок.
Например, если вы вызовете функцию, которая не принимает параметров, но передадите ей параметры в .map(), поток выбросит исключение.
К сожалению, ThreadPoolExecutor скроет это исключение, и (в приведенном выше случае) программа завершится без вывода. Поначалу это может сбить с толку при отладке.
При выполнении исправленного кода примера вывод будет выглядеть следующим образом:
$ ./executor.py
Thread 0: starting
Thread 1: starting
Thread 2: starting
Thread 1: finishing
Thread 0: finishing
Thread 2: finishing
Опять же, обратите внимание, как Thread 1 закончился раньше Thread 0. Планирование потоков осуществляется операционной системой и не следует плану, который легко вычислить.
Условия гонки
Прежде чем вы перейдете к другим возможностям, скрытым в Python threading, давайте немного поговорим об одной из самых сложных проблем, с которыми вы столкнетесь при написании потоковых программ: условия гонки.
После того как вы узнали, что такое состояние гонки, и посмотрели, как оно возникает, вы перейдете к некоторым примитивам, предоставляемым стандартной библиотекой для предотвращения возникновения состояния гонки.
Состояния гонки могут возникать, когда два или более потоков обращаются к общему фрагменту данных или ресурса. В этом примере вы создадите большое состояние гонки, которое будет возникать каждый раз, но имейте в виду, что большинство состояний гонки не так очевидны. Зачастую они возникают лишь изредка и могут приводить к запутанным результатам. Как вы можете себе представить, это делает их довольно сложными для отладки.
К счастью, это состояние гонки будет возникать каждый раз, и вы подробно рассмотрите его, чтобы объяснить, что происходит.
В этом примере вы напишете класс, который обновляет базу данных. Хорошо, на самом деле у вас не будет базы данных: вы просто подделаете ее, потому что это не суть важно для данной статьи.
Ваш FakeDatabase будет иметь .__init__() и .update() методы:
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: starting update", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: finishing update", name)
FakeDatabase ведет учет одного числа: .value. Это будут общие данные, на которых вы увидите состояние гонки.
.__init__() просто инициализирует .value в ноль. Пока все хорошо.
.update() выглядит немного странно. Он имитирует чтение значения из базы данных, выполнение некоторых вычислений, а затем запись нового значения обратно в базу данных.
В данном случае чтение из базы данных означает просто копирование .value в локальную переменную. Вычисления сводятся к тому, что к значению прибавляется единица, а затем .sleep() на некоторое время. Наконец, он записывает значение обратно, копируя локальное значение обратно в .value.
Вот как вы будете использовать это FakeDatabase:
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
Программа создает ThreadPoolExecutor с двумя потоками, а затем вызывает .submit() на каждом из них, указывая им выполнить database.update().
.submit() имеет сигнатуру, которая позволяет передавать функции, выполняющейся в потоке, как позиционные, так и именованные аргументы:
.submit(function, *args, **kwargs)
В приведенном выше примере index передается в качестве первого и единственного позиционного аргумента в database.update(). Далее в этой статье вы увидите, что аналогичным образом можно передавать несколько аргументов.
<<<Поскольку каждый поток выполняет .update(), а .update() добавляет единицу к .value, вы можете ожидать, что database.value будет 2, когда он будет выведен в конце. Но если бы это было так, вы бы не смотрели на этот пример. Если вы выполните приведенный выше код, вывод будет выглядеть так:
$ ./racecond.py
Testing unlocked update. Starting value is 0.
Thread 0: starting update
Thread 1: starting update
Thread 0: finishing update
Thread 1: finishing update
Testing unlocked update. Ending value is 1.
Вы, наверное, ожидали этого, но давайте рассмотрим детали того, что здесь происходит на самом деле, поскольку так будет легче понять решение этой проблемы.
Один поток
Прежде чем погрузиться в эту проблему с двумя потоками, давайте сделаем шаг назад и немного поговорим о некоторых деталях работы потоков.
Здесь вы не будете вдаваться во все подробности, поскольку на данном уровне это не так важно. Мы также упростим некоторые моменты, которые не будут технически точными, но дадут вам правильное представление о происходящем.
Когда вы говорите своему ThreadPoolExecutor запустить каждый поток, вы указываете ему, какую функцию запускать и какие параметры ей передавать: executor.submit(database.update, index).
В результате каждый из потоков в пуле вызовет database.update(index). Обратите внимание, что database - это ссылка на один объект FakeDatabase, созданный в __main__. Вызов .update() на этом объекте вызывает метод экземпляра на этом объекте.
Каждый поток будет иметь ссылку на один и тот же объект FakeDatabase, database. Каждый поток также будет иметь уникальное значение, index, чтобы было легче читать отчеты о регистрации:
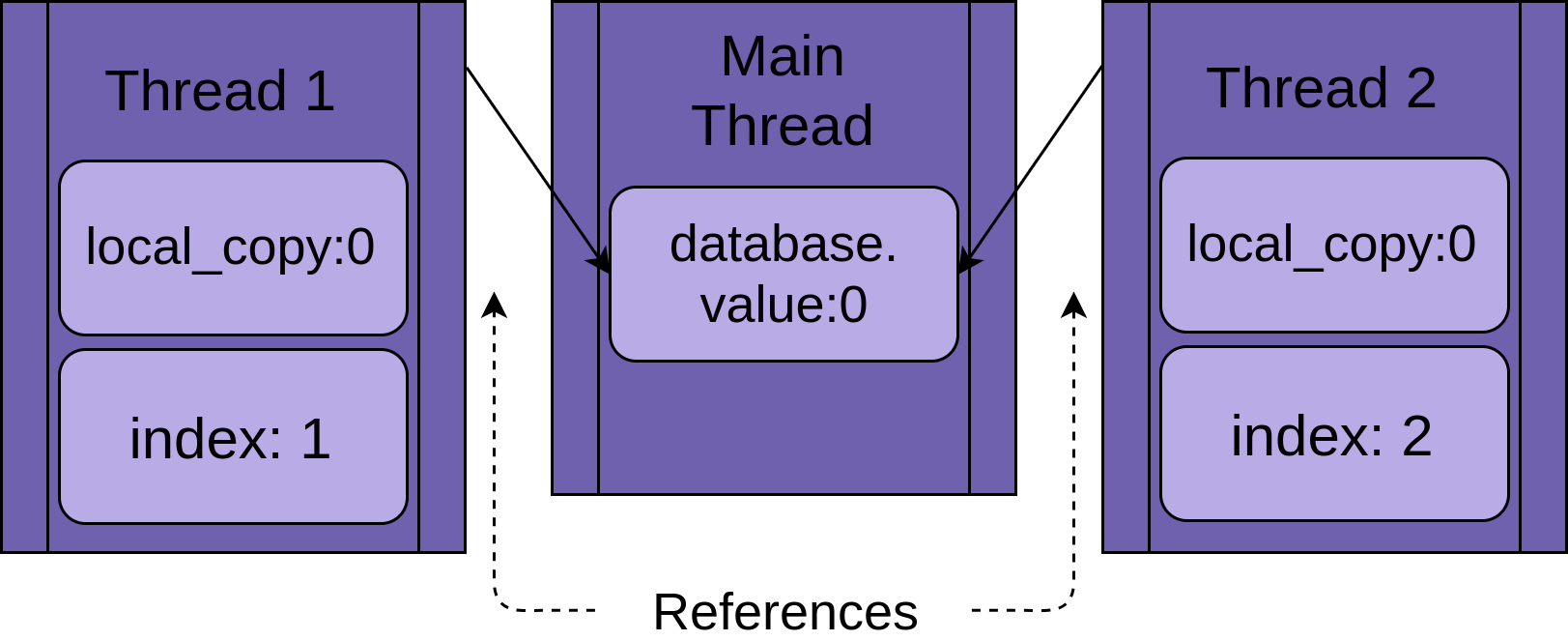
Когда поток начинает выполняться .update(), у него есть своя версия всех данных локальных для функции. В случае .update() это local_copy. Это, безусловно, хорошо. Иначе два потока, выполняющие одну и ту же функцию, постоянно путали бы друг друга. Это означает, что все переменные, привязанные (или локальные) к функции, являются потокобезопасными.
Теперь можно приступить к рассмотрению того, что произойдет, если запустить приведенную выше программу с одним потоком и одним вызовом .update().
На рисунке ниже показано выполнение .update(), если запущен только один поток. Слева показан оператор, а затем диаграмма, показывающая значения в local_copy и в общем database.value:
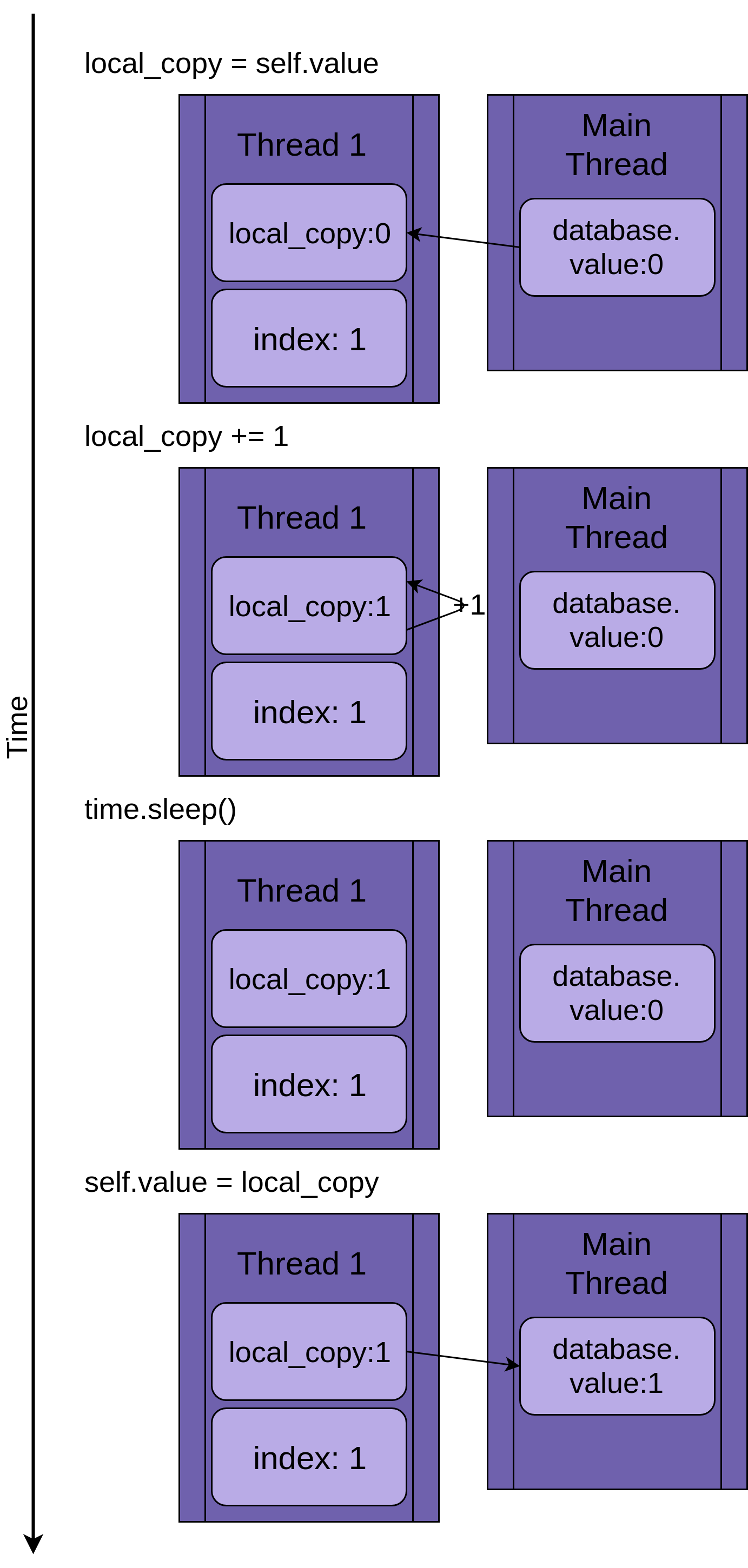
Диаграмма построена таким образом, что время увеличивается по мере продвижения сверху вниз. Она начинается, когда создается Thread 1, и заканчивается, когда он завершается.
Когда начинается Thread 1, FakeDatabase.value равен нулю. Первая строка кода в методе, local_copy = self.value, копирует значение ноль в локальную переменную. Далее она увеличивает значение local_copy с помощью оператора local_copy += 1. Вы можете видеть, как .value в Thread 1 устанавливается в единицу.
Вызывается
Next time.sleep(), что заставляет текущий поток приостановиться и позволяет запустить другие потоки. Поскольку в данном примере имеется только один поток, это не имеет никакого эффекта.
Когда Thread 1 просыпается и продолжает работу, он копирует новое значение из local_copy в FakeDatabase.value, после чего поток завершается. Вы можете видеть, что значение database.value установлено в единицу.
Пока все хорошо. Вы выполнили .update() один раз, и FakeDatabase.value увеличилось до единицы.
Два потока
Возвращаясь к условию гонки, можно сказать, что два потока будут выполняться одновременно, но не в одно и то же время. У каждого из них будет своя версия local_copy и каждый будет указывать на один и тот же database. Именно этот общий объект database будет вызывать проблемы.
Программа начинается с Thread 1, запущенной .update():
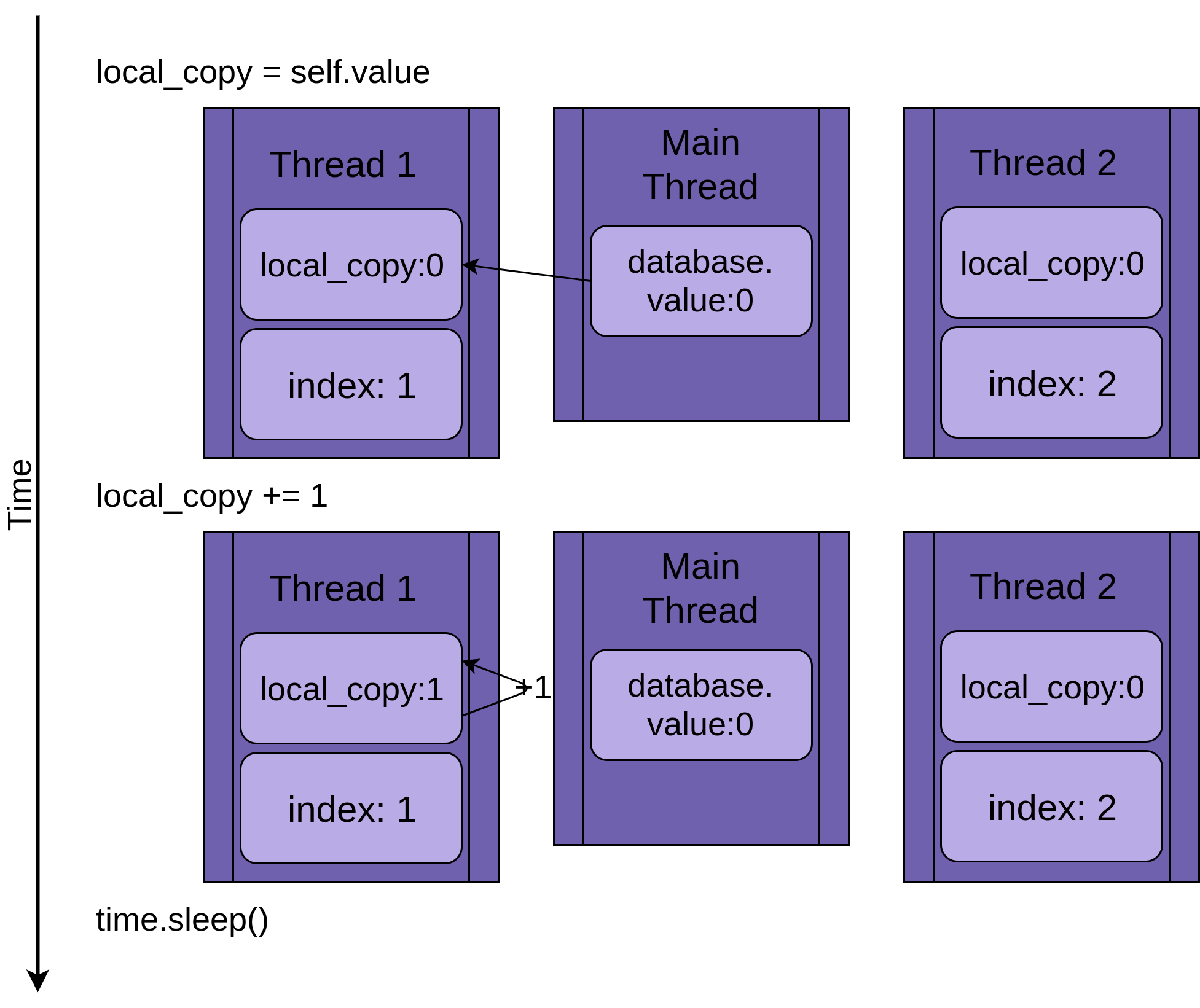
Когда Thread 1 вызывает time.sleep(), он позволяет другому потоку начать выполнение. Вот тут-то все и становится интересным.
Thread 2 запускается и выполняет те же операции. Он также копирует database.value в свой частный local_copy, а этот общий database.value еще не обновлен:
Когда Thread 2 наконец переходит в спящий режим, общий database.value по-прежнему не модифицирован и имеет нулевое значение, а обе приватные версии local_copy имеют значение один.
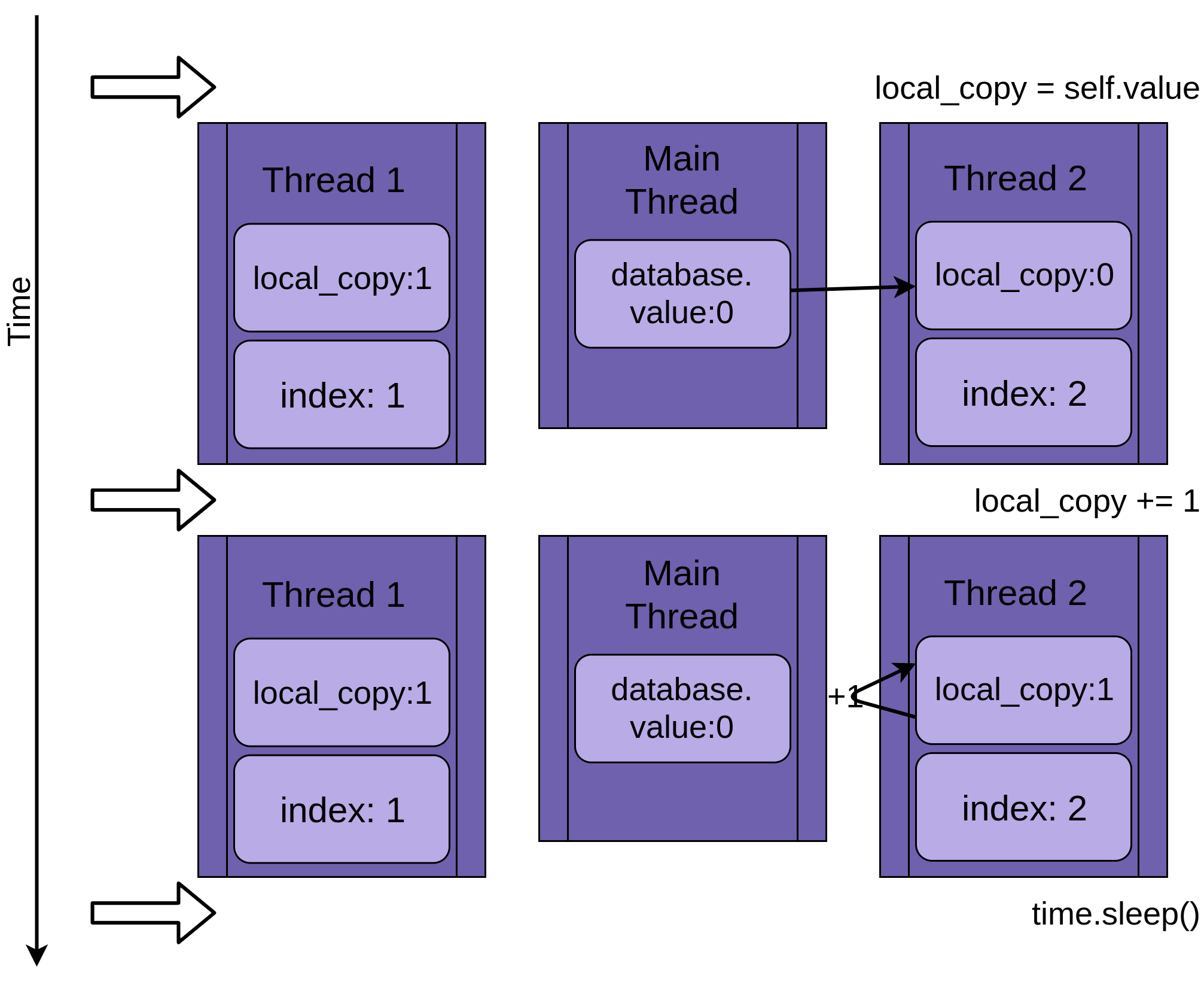
Thread 1 теперь просыпается и сохраняет свою версию local_copy, а затем завершает работу, давая Thread 2 последний шанс на выполнение. Thread 2 понятия не имеет, что Thread 1 запустился и обновил database.value, пока он спал. Он сохраняет свою версию local_copy в database.value, также устанавливая ее в единицу:
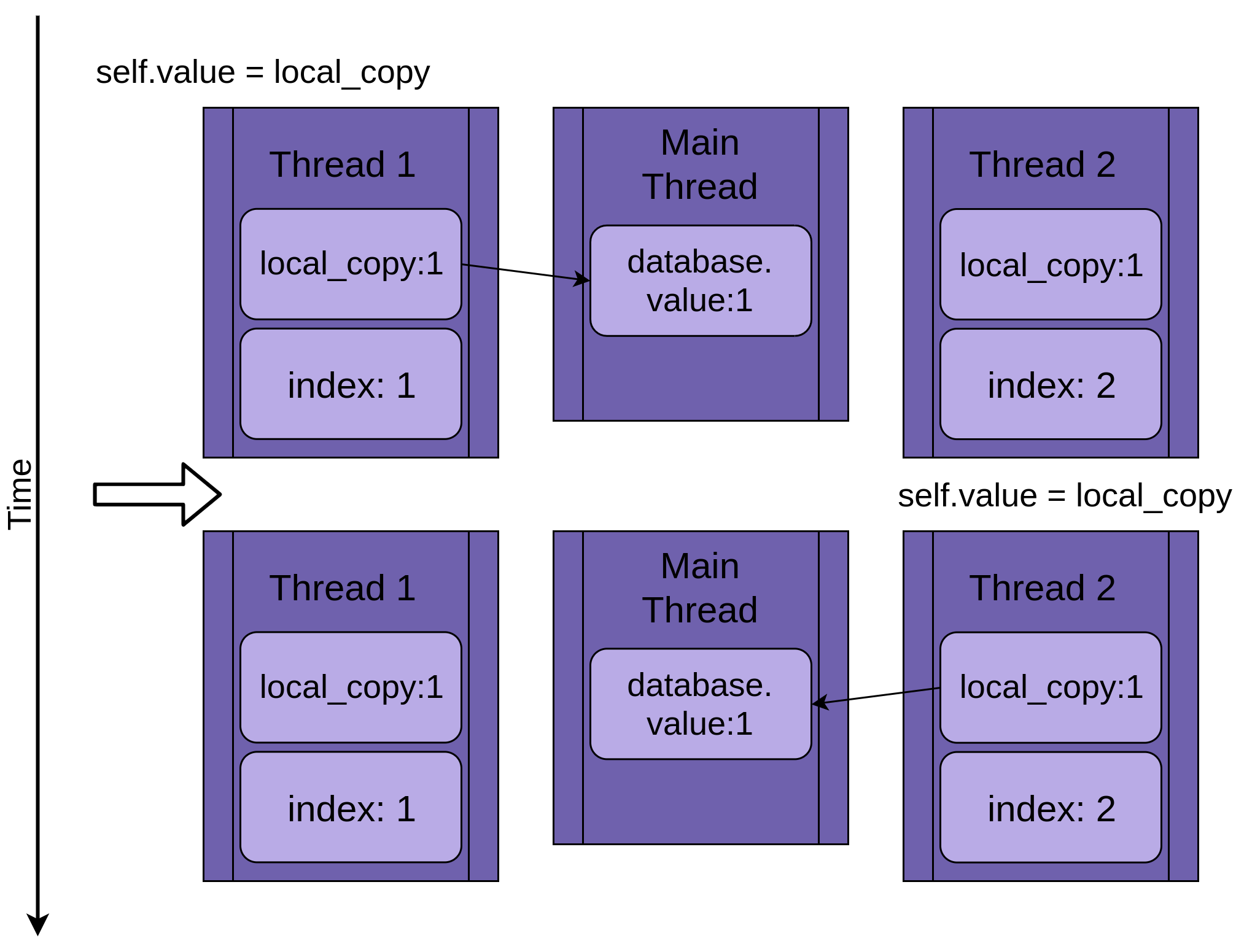
Два потока имеют чередующийся доступ к одному общему объекту, перезаписывая результаты друг друга. Аналогичные условия гонки могут возникать, когда один поток освобождает память или закрывает файловый хэндл до того, как другой поток закончит к нему обращаться.
Почему это не глупый пример
Приведенный выше пример надуман для того, чтобы убедиться, что состояние гонки возникает каждый раз, когда вы запускаете свою программу. Поскольку операционная система может поменять поток местами в любой момент, можно прервать выполнение оператора x = x + 1 после того, как он прочитал значение x, но до того, как он записал обратно увеличенное значение.
Подробности того, как это происходит, довольно интересны, но не нужны для остальной части этой статьи, поэтому смело пропускайте этот раздел.
Как на самом деле это работает
Приведенный выше код не так уж прост, как вы могли подумать изначально. Он был разработан для принудительного возникновения состояния гонки каждый раз, когда вы его запускаете, но это значительно упрощает решение, чем большинство условий гонки.
При рассмотрении условий гонки следует учитывать две вещи:
- Даже такая операция, как
x += 1требует от процессора много шагов. Каждый из этих шагов представляет собой отдельную инструкцию процессору.- Операционная система может поменять запущенный поток в любое время. Нить можно заменить после любой из этих небольших инструкций. Это означает, что поток можно перевести в режим ожидания, чтобы позволить другому потоку работать в середине инструкции Python.
Давайте рассмотрим это подробнее. В приведенном ниже REPL показана функция, которая принимает параметр и увеличивает его:
>>> def inc(x): ... x += 1 ... >>> import dis >>> dis.dis(inc) 2 0 LOAD_FAST 0 (x) 2 LOAD_CONST 1 (1) 4 INPLACE_ADD 6 STORE_FAST 0 (x) 8 LOAD_CONST 0 (None) 10 RETURN_VALUEВ примере REPL используется
disиз стандарта Python библиотека, чтобы показать более мелкие шаги, которые процессор выполняет для реализации вашей функции. Он выполняетLOAD_FASTзначения данныхx, он выполняетLOAD_CONST 1, а затем используетINPLACE_ADDчтобы сложить эти значения.Мы останавливаемся здесь по определенной причине. Это точка в
.update()выше, гдеtime.sleep()заставляет потоки переключаться. Вполне возможно, что время от времени операционная система будет переключать потоки именно в этот момент даже безsleep(), но при вызовеsleep()так происходит каждый раз.Как вы узнали выше, операционная система может менять потоки в любое время. Вы прошли по этому списку до утверждения, отмеченного
4. Если операционная система заменяет этот поток и запускает другой поток, который также изменяетx, то при возобновлении работы этого потока он перезапишетxневерным значением. .Технически в этом примере не будет состояния гонки, поскольку
xявляется локальным дляinc(). Однако он иллюстрирует, как поток может быть прерван во время одной операции Python. Тот же набор операций LOAD, MODIFY, STORE также выполняется с глобальными и общими значениями. Вы можете изучить это с помощью модуляdisи убедиться в этом сами.Подобное состояние гонки встречается редко, но помните, что редкое событие, возникающее в течение миллионов итераций, вполне вероятно. Редкость этих состояний гонки делает их гораздо сложнее отлаживать, чем обычные ошибки.
Теперь, когда вы увидели состояние гонки в действии, давайте узнаем, как его решить!
Базовая синхронизация с помощью Lock
Существует несколько способов избежать или устранить условия гонки. Здесь мы не будем рассматривать все из них, но есть несколько, которые часто используются. Начнем с Lock.
Чтобы решить вышеописанное состояние гонки, вам нужно найти способ разрешить только одному потоку одновременно входить в секцию чтения-модификации-записи вашего кода. Наиболее распространенный способ сделать это называется Lock в Python. В некоторых других языках эта же идея называется mutex. Mutex происходит от MUTual EXclusion, а это именно то, что делает Lock.
А Lock - это объект, который действует как пропуск в зал. Только один поток одновременно может обладать Lock. Любой другой поток, желающий получить Lock, должен ждать, пока владелец Lock не отдаст его.
Основными функциями для этого являются .acquire() и .release(). Поток вызовет my_lock.acquire(), чтобы получить блокировку. Если блокировка уже удерживается, вызывающий поток будет ждать, пока она не будет освобождена. Здесь есть важный момент. Если один поток получит блокировку, но так и не вернет ее, ваша программа застрянет. Подробнее об этом вы прочитаете позже.
К счастью, в Python Lock также работает как менеджер контекста, поэтому вы можете использовать его в операторе with, и он автоматически освобождается при выходе из блока with по какой-либо причине.
Давайте посмотрим на FakeDatabase с добавленным к нему Lock. Вызывающая функция осталась прежней:
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock()
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
logging.debug("Thread %s about to lock", name)
with self._lock:
logging.debug("Thread %s has lock", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s about to release lock", name)
logging.debug("Thread %s after release", name)
logging.info("Thread %s: finishing update", name)
Кроме добавления кучи отладочных логов, чтобы вы могли более четко видеть блокировку, главное изменение здесь заключается в добавлении члена ._lock, который представляет собой объект threading.Lock(). Этот ._lock инициализируется в разблокированном состоянии, а блокируется и освобождается оператором with.
Здесь стоит отметить, что поток, выполняющий эту функцию, будет удерживать эту Lock до тех пор, пока полностью не завершит обновление базы данных. В данном случае это означает, что он будет удерживать Lock, пока копирует, обновляет, спит, а затем записывает значение обратно в базу данных.
Если вы запустите эту версию с протоколированием на уровне предупреждения, вы увидите следующее:
$ ./fixrace.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 1: starting update
Thread 0: finishing update
Thread 1: finishing update
Testing locked update. Ending value is 2.
Посмотрите на это. Ваша программа наконец-то работает!
Вы можете включить полное протоколирование, установив уровень DEBUG, добавив это утверждение после настройки вывода протоколирования в __main__:
logging.getLogger().setLevel(logging.DEBUG)
Запуск этой программы с включенным DEBUG протоколированием выглядит следующим образом:
$ ./fixrace.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 0 about to lock
Thread 0 has lock
Thread 1: starting update
Thread 1 about to lock
Thread 0 about to release lock
Thread 0 after release
Thread 0: finishing update
Thread 1 has lock
Thread 1 about to release lock
Thread 1 after release
Thread 1: finishing update
Testing locked update. Ending value is 2.
В этом выводе видно, что Thread 0 приобретает блокировку и продолжает удерживать ее, когда переходит в спящий режим. Затем запускается Thread 1 и пытается получить ту же самую блокировку. Поскольку Thread 0 все еще удерживает ее, Thread 1 вынужден ждать. Это и есть взаимное исключение, которое обеспечивает Lock.
Во многих примерах, приведенных в этой статье, будет вестись протоколирование на уровнях WARNING и DEBUG. Как правило, мы будем показывать только вывод уровня WARNING, так как журналы DEBUG могут быть довольно длинными. Попробуйте программы с включенным протоколированием и посмотрите, что они делают.
Тупиковая ситуация
Прежде чем двигаться дальше, стоит обратить внимание на распространенную проблему при использовании Locks. Как вы видели, если Lock уже был получен, второй вызов .acquire() будет ждать, пока поток, удерживающий Lock, вызовет .release(). Как вы думаете, что произойдет, если запустить этот код:
import threading
l = threading.Lock()
print("before first acquire")
l.acquire()
print("before second acquire")
l.acquire()
print("acquired lock twice")
Когда программа вызывает l.acquire() во второй раз, она зависает, ожидая освобождения Lock. В этом примере вы можете устранить тупик, удалив второй вызов, но тупики обычно возникают из-за одной из двух тонких вещей:
- Ошибка реализации, когда
Lockне освобождается должным образом - Проблема проектирования, когда полезная функция должна вызываться функциями, которые могут иметь или не иметь
Lock
Первая ситуация иногда случается, но использование Lock в качестве менеджера контекста значительно снижает ее частоту. Рекомендуется по возможности писать код с использованием менеджеров контекста, так как они помогают избежать ситуаций, когда исключение пропускает вас через вызов .release().
В некоторых языках вопрос оформления может быть немного сложнее. К счастью, в потоковой системе Python есть второй объект, называемый RLock, который предназначен как раз для такой ситуации. Он позволяет потоку .acquire() RLock несколько раз, прежде чем он вызовет .release(). Этот поток все равно должен вызвать .release() столько же раз, сколько и .acquire(), но он должен делать это в любом случае.
Lock и RLock - два основных инструмента, используемых в потоковом программировании для предотвращения условий гонки. Есть еще несколько других, которые работают по-разному. Прежде чем рассмотреть их, давайте перейдем к немного другой проблемной области.
Потоковая передача производитель-потребитель
Producer-Consumer Problem - это стандартная задача информатики, используемая для изучения проблем потоков или синхронизации процессов. Вы рассмотрите один из ее вариантов, чтобы получить представление о том, какие примитивы предоставляет модуль Python threading.
В этом примере вы представите себе программу, которая должна читать сообщения из сети и записывать их на диск. Программа не запрашивает сообщения, когда ей захочется. Она должна слушать и принимать сообщения по мере их поступления. Сообщения не будут поступать регулярно, а будут приходить очередями. Эта часть программы называется производителем.
С другой стороны, когда у вас есть сообщение, вам нужно записать его в базу данных. Доступ к базе данных медленный, но достаточно быстрый, чтобы успевать за средним темпом сообщений. Он не достаточно быстр, чтобы не отставать, когда поступает большое количество сообщений. Эта часть является потребителем.
Между производителем и потребителем вы создадите Pipeline, который будет той частью, которая будет меняться по мере изучения различных объектов синхронизации.
Это основная схема. Давайте рассмотрим решение с использованием Lock. Оно не работает идеально, но в нем используются уже знакомые вам инструменты, так что с него можно начать.
Производитель-Потребитель, использующий Lock
Поскольку это статья о Python threading, и поскольку вы только что прочитали о примитиве Lock, давайте попробуем решить эту проблему с двумя потоками, используя Lock или два.
Общая схема такова: есть поток producer, который читает из фальшивой сети и помещает сообщение в поток Pipeline:
import random
SENTINEL = object()
def producer(pipeline):
"""Pretend we're getting a message from the network."""
for index in range(10):
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
# Send a sentinel message to tell consumer we're done
pipeline.set_message(SENTINEL, "Producer")
Чтобы сгенерировать фальшивое сообщение, producer получает случайное число от одного до ста. Он вызывает .set_message() на pipeline, чтобы отправить его на consumer.
В producer также используется значение SENTINEL, чтобы сигнализировать потребителю об остановке после отправки десяти значений. Это немного неудобно, но не волнуйтесь, вы увидите способы избавиться от этого значения SENTINEL после того, как разберетесь с этим примером.
На другой стороне pipeline находится потребитель:
def consumer(pipeline):
"""Pretend we're saving a number in the database."""
message = 0
while message is not SENTINEL:
message = pipeline.get_message("Consumer")
if message is not SENTINEL:
logging.info("Consumer storing message: %s", message)
Программа consumer считывает сообщение из pipeline и записывает его в поддельную базу данных, которая в данном случае просто выводит его на дисплей. Если он получает значение SENTINEL, то возвращается из функции, которая завершает поток.
Прежде чем вы посмотрите на действительно интересную часть, Pipeline, вот раздел __main__, который порождает эти нити:
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline)
executor.submit(consumer, pipeline)
Это должно выглядеть довольно знакомо, поскольку близко к коду __main__ в предыдущих примерах.
Помните, что вы можете включить DEBUG ведение журнала, чтобы увидеть все сообщения журнала, откомментировав эту строку:
# logging.getLogger().setLevel(logging.DEBUG)
Возможно, стоит просмотреть сообщения журнала DEBUG, чтобы увидеть, где именно каждый поток приобретает и освобождает блокировки.
Теперь давайте посмотрим на Pipeline, который передает сообщения от producer к consumer:
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
logging.debug("%s:about to acquire getlock", name)
self.consumer_lock.acquire()
logging.debug("%s:have getlock", name)
message = self.message
logging.debug("%s:about to release setlock", name)
self.producer_lock.release()
logging.debug("%s:setlock released", name)
return message
def set_message(self, message, name):
logging.debug("%s:about to acquire setlock", name)
self.producer_lock.acquire()
logging.debug("%s:have setlock", name)
self.message = message
logging.debug("%s:about to release getlock", name)
self.consumer_lock.release()
logging.debug("%s:getlock released", name)
Ух ты! Это очень много кода. Большая его часть - это просто операторы логирования, чтобы было проще понять, что происходит при выполнении. Вот тот же код с удаленными операторами логирования:
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
self.consumer_lock.acquire()
message = self.message
self.producer_lock.release()
return message
def set_message(self, message, name):
self.producer_lock.acquire()
self.message = message
self.consumer_lock.release()
Это кажется немного более управляемым. В этой версии вашего кода Pipeline имеет три члена:
.messageхранит сообщение для передачи..producer_lock-threading.Lockобъект, ограничивающий доступ к сообщению со стороныproducerпотока..consumer_lockтакже являетсяthreading.Lock, ограничивающим доступ к сообщению со стороныconsumerпотока.
__init__() инициализирует эти три члена, а затем вызывает .acquire() на .consumer_lock. Это то состояние, в котором вы хотите начать работу. Член producer может добавить новое сообщение, но член consumer должен подождать, пока сообщение не появится.
.get_message() и .set_messages() почти противоположны. .get_message() вызывает .acquire() на consumer_lock. Именно этот вызов заставит consumer ждать, пока сообщение не будет готово.
После того как consumer получил .consumer_lock, он копирует значение в .message, а затем вызывает .release() на .producer_lock. Освобождение этой блокировки позволяет producer вставить следующее сообщение в pipeline.
Прежде чем перейти к .set_message(), в .get_message() происходит нечто неуловимое, что довольно легко пропустить. Может показаться заманчивым избавиться от message и просто завершить функцию на return self.message. Попробуйте понять, почему вы не хотите этого делать, прежде чем двигаться дальше.
Вот ответ. Как только consumer вызовет .producer_lock.release(), его можно поменять местами, и producer начнет выполняться. Это может произойти до того, как .release() вернется! Это означает, что есть небольшая вероятность того, что когда функция вернет self.message, это может быть следующее сообщение , и вы потеряете первое сообщение. Это еще один пример состояния гонки.
Переходя к .set_message(), вы можете увидеть противоположную сторону транзакции. producer вызовет это с сообщением. Он получит .producer_lock, установит .message, а затем вызовет .release() на consumer_lock, что позволит consumer прочитать это значение.
Давайте запустим код, в котором логирование установлено на WARNING, и посмотрим, как это выглядит:
$ ./prodcom_lock.py
Producer got data 43
Producer got data 45
Consumer storing data: 43
Producer got data 86
Consumer storing data: 45
Producer got data 40
Consumer storing data: 86
Producer got data 62
Consumer storing data: 40
Producer got data 15
Consumer storing data: 62
Producer got data 16
Consumer storing data: 15
Producer got data 61
Consumer storing data: 16
Producer got data 73
Consumer storing data: 61
Producer got data 22
Consumer storing data: 73
Consumer storing data: 22
Сначала вам может показаться странным, что производитель получает два сообщения еще до запуска потребителя. Если вы оглянетесь на producer и .set_message(), то заметите, что единственное место, где он будет ждать Lock, - это когда он попытается поместить сообщение в конвейер. Это делается после того, как producer получит сообщение и зафиксирует, что оно у него есть.
Когда producer попытается отправить это второе сообщение, он вызовет .set_message() во второй раз и заблокирует его.
Операционная система может поменять потоки местами в любой момент, но обычно она дает каждому потоку разумное количество времени для работы, прежде чем поменять его местами. Вот почему producer обычно выполняется до тех пор, пока не блокируется при втором вызове .set_message().
Однако если поток заблокирован, операционная система всегда поменяет его местами и найдет другой поток для выполнения. В данном случае единственным другим потоком, которому есть чем заняться, является consumer.
consumer вызывает .get_message(), который читает сообщение и вызывает .release() на .producer_lock, что позволяет снова запустить producer при следующей смене потоков.
Обратите внимание, что первым сообщением было 43, и именно его прочитал consumer, хотя producer уже сгенерировал сообщение 45.
Хотя это работает для данного ограниченного теста, это не лучшее решение проблемы производитель-потребитель в целом, потому что оно позволяет только одно значение в конвейере за один раз. Когда producer получит шквал сообщений, ему будет некуда их девать.
Перейдем к лучшему способу решения этой проблемы - использованию Queue.
Производитель-Потребитель, использующий Queue
Если вы хотите иметь возможность обрабатывать более одного значения в конвейере одновременно, вам понадобится структура данных для конвейера, которая позволит увеличивать и уменьшать число по мере поступления данных из producer.
В стандартной библиотеке
Python есть модуль queue, который, в свою очередь, имеет класс Queue. Давайте изменим Pipeline, чтобы использовать Queue, а не просто переменную, защищенную Lock. Вы также будете использовать другой способ остановки рабочих потоков, используя другой примитив из Python threading, Event.
Начнем с Event. Объект threading.Event позволяет одному потоку подать сигнал event, в то время как многие другие потоки могут ожидать наступления этого event. Ключевым моментом в этом коде является то, что потоки, ожидающие события, не обязательно должны останавливать свою работу, они могут просто время от времени проверять состояние Event.
Инициировать событие может множество вещей. В этом примере главный поток просто поспит некоторое время, а затем .set() произойдет:
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
Единственными изменениями здесь являются создание объекта event в строке 8, передача event в качестве параметра в строках 10 и 11, и заключительная секция в строках с 13 по 15, которая спит в течение секунды, регистрирует сообщение, а затем вызывает .set() по событию.
В producer также не пришлось сильно меняться:
def producer(pipeline, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
logging.info("Producer received EXIT event. Exiting")
Теперь он будет циклиться до тех пор, пока не увидит, что событие было установлено в строке 3. Он также больше не помещает значение SENTINEL в pipeline.
consumer пришлось изменить еще немного:
def consumer(pipeline, event):
"""Pretend we're saving a number in the database."""
while not event.is_set() or not pipeline.empty():
message = pipeline.get_message("Consumer")
logging.info(
"Consumer storing message: %s (queue size=%s)",
message,
pipeline.qsize(),
)
logging.info("Consumer received EXIT event. Exiting")
Хотя вы убрали код, связанный со значением SENTINEL, вам пришлось сделать немного более сложное условие while. Мало того, что цикл должен выполняться до тех пор, пока не будет установлено значение event, он также должен продолжать цикл до тех пор, пока не будет опустошено значение pipeline.
Убедитесь, что очередь пуста до того, как потребитель завершит работу, чтобы предотвратить еще одну забавную проблему. Если consumer завершается в то время, когда в pipeline находятся сообщения, могут произойти две неприятные вещи. Первая заключается в том, что вы потеряете последние сообщения, но более серьезная - producer может быть поймана при попытке добавить сообщение в полную очередь и никогда не вернуться.
Это происходит, если event срабатывает после того, как producer проверил условие .is_set(), но до вызова pipeline.set_message().
Если это произойдет, то потребитель может проснуться и выйти, когда очередь еще полностью заполнена. Тогда producer вызовет .set_message(), который будет ждать, пока в очереди не освободится место для нового сообщения. Потребитель consumer уже вышел, поэтому этого не произойдет, и producer не выйдет.
Остальные части consumer должны выглядеть знакомо.
Однако Pipeline кардинально изменился:
class Pipeline(queue.Queue):
def __init__(self):
super().__init__(maxsize=10)
def get_message(self, name):
logging.debug("%s:about to get from queue", name)
value = self.get()
logging.debug("%s:got %d from queue", name, value)
return value
def set_message(self, value, name):
logging.debug("%s:about to add %d to queue", name, value)
self.put(value)
logging.debug("%s:added %d to queue", name, value)
Вы видите, что Pipeline является подклассом queue.Queue. Queue имеет необязательный параметр при инициализации для указания максимального размера очереди.
Если вы укажете положительное число для maxsize, это ограничит очередь этим числом элементов, заставляя .put() блокировать до тех пор, пока в ней не будет меньше maxsize элементов. Если вы не укажете maxsize, то очередь будет расти до пределов памяти вашего компьютера.
.get_message() и .set_message() стали намного меньше. По сути, они обертывают .get() и .put() на Queue. Вам может быть интересно, куда делся весь код блокировки, который не позволяет потокам вызывать условия гонки.
Разработчики ядра, написавшие стандартную библиотеку, знали, что Queue часто используется в многопоточных средах, и включили весь этот код блокировки в сам Queue. Queue является потокобезопасным.
Запуск этой программы выглядит следующим образом:
$ ./prodcom_queue.py
Producer got message: 32
Producer got message: 51
Producer got message: 25
Producer got message: 94
Producer got message: 29
Consumer storing message: 32 (queue size=3)
Producer got message: 96
Consumer storing message: 51 (queue size=3)
Producer got message: 6
Consumer storing message: 25 (queue size=3)
Producer got message: 31
[many lines deleted]
Producer got message: 80
Consumer storing message: 94 (queue size=6)
Producer got message: 33
Consumer storing message: 20 (queue size=6)
Producer got message: 48
Consumer storing message: 31 (queue size=6)
Producer got message: 52
Consumer storing message: 98 (queue size=6)
Main: about to set event
Producer got message: 13
Consumer storing message: 59 (queue size=6)
Producer received EXIT event. Exiting
Consumer storing message: 75 (queue size=6)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 13 (queue size=0)
Consumer received EXIT event. Exiting
Если вы прочитаете вывод в моем примере, то увидите несколько интересных вещей. В самом верху видно, что producer создал пять сообщений и поместил четыре из них в очередь. Операционная система вытеснила его, прежде чем он успел поместить пятое сообщение.
Затем consumer подбежал и сорвал первое послание. Он вывел это сообщение, а также информацию о том, насколько глубока была очередь в этот момент:
Consumer storing message: 32 (queue size=3)
Так вы узнаете, что пятое сообщение еще не попало в pipeline. Очередь уменьшилась до третьего размера после удаления одного сообщения. Вы также знаете, что queue вмещает десять сообщений, поэтому поток producer не был заблокирован потоком queue. Она была вытеснена ОС.
Примечание: Ваш вывод будет отличаться. Ваш вывод будет меняться от выполнения к выполнению. В этом и заключается вся прелесть работы с потоками!
Как только программа начинает сворачиваться, вы видите, как главный поток генерирует event, что приводит к немедленному выходу producer. У consumer еще много работы, поэтому он продолжает работать, пока не очистит pipeline.
Попробуйте поиграть с разными размерами очереди и вызовами time.sleep() в producer или consumer, чтобы имитировать более длительное время доступа к сети или диску соответственно. Даже незначительные изменения в этих элементах программы сильно повлияют на ваши результаты.
Это гораздо лучшее решение проблемы "производитель-потребитель", но вы можете упростить его еще больше. Pipeline действительно не нужен для этой проблемы. Как только вы уберете логирование, это просто станет queue.Queue.
Вот как выглядит окончательный код, использующий queue.Queue напрямую:
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(queue, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
queue.put(message)
logging.info("Producer received event. Exiting")
def consumer(queue, event):
"""Pretend we're saving a number in the database."""
while not event.is_set() or not queue.empty():
message = queue.get()
logging.info(
"Consumer storing message: %s (size=%d)", message, queue.qsize()
)
logging.info("Consumer received event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
Это легче читать и показывает, как использование встроенных примитивов Python может упростить сложную проблему.
Lock и Queue - удобные классы для решения проблем параллелизма, но есть и другие, предоставляемые стандартной библиотекой. Прежде чем завершить этот учебник, давайте сделаем краткий обзор некоторых из них.
Объекты потоковой обработки
Есть еще несколько примитивов, предлагаемых модулем Python threading. Хотя в приведенных выше примерах они вам не понадобились, они могут пригодиться в различных случаях, поэтому полезно с ними ознакомиться.
Semaphore
Первым объектом Python threading, на который следует обратить внимание, является threading.Semaphore. Semaphore - это счетчик с несколькими особыми свойствами. Первое из них заключается в том, что подсчет является атомарным. Это означает, что есть гарантия того, что операционная система не переключит поток в середине увеличения или уменьшения счетчика.
Внутренний счетчик инкрементируется при вызове .release() и декрементируется при вызове .acquire().
Следующее особое свойство заключается в том, что если поток вызывает .acquire(), когда счетчик равен нулю, то этот поток будет блокироваться до тех пор, пока другой поток не вызовет .release() и не увеличит счетчик до единицы.
Семафоры часто используются для защиты ресурса, имеющего ограниченную емкость. Например, если у вас есть пул соединений и вы хотите ограничить размер этого пула определенным числом.
Timer
А threading.Timer - это способ запланировать вызов функции по истечении определенного времени. Вы создаете Timer, передавая количество секунд ожидания и функцию для вызова:
t = threading.Timer(30.0, my_function)
Вы начинаете Timer с вызова .start(). Функция будет вызвана в новом потоке в какой-то момент после указанного времени, но имейте в виду, что нет никаких гарантий, что она будет вызвана именно в то время, которое вы хотите.
Если вы хотите остановить Timer, который вы уже начали, вы можете отменить его, вызвав .cancel(). Вызов .cancel() после срабатывания Timer ничего не делает и не приводит к исключению.
А Timer можно использовать для того, чтобы побудить пользователя к действию через определенный промежуток времени. Если пользователь выполнит действие до истечения Timer, можно вызвать .cancel().
Barrier
А threading.Barrier можно использовать для синхронизации фиксированного числа потоков. При создании Barrier вызывающая сторона должна указать, сколько потоков будет синхронизироваться на нем. Каждый поток вызывает .wait() на Barrier. Все они остаются заблокированными до тех пор, пока указанное количество потоков не будет ожидать, а затем все они освобождаются одновременно.
Помните, что потоки планируются операционной системой, поэтому, даже если все потоки освобождаются одновременно, они будут выполняться по очереди.
Одно из применений Barrier - позволить пулу потоков инициализировать себя. Если после инициализации потоки будут ожидать Barrier, это гарантирует, что ни один из потоков не начнет работу до того, как все потоки закончат инициализацию.
Заключение: Потоки в Python
Теперь вы познакомились со многими возможностями Python threading и увидели несколько примеров построения потоковых программ и проблем, которые они решают. Вы также видели несколько примеров проблем, возникающих при написании и отладке программ с потоками.
Если вы хотите изучить другие варианты использования параллелизма в Python, ознакомьтесь с Speed Up Your Python Program With Concurrency.
Если вы заинтересованы в глубоком погружении в модуль asyncio, прочтите Async IO in Python: A Complete Walkthrough.
Что бы вы ни делали, теперь у вас есть информация и уверенность, необходимые для написания программ с использованием потоковой обработки в Python!
Вернуться на верх