ThreadPoolExecutor в Python: полное руководство
Исполнитель Python ThreadPoolExecutor позволяет создавать и управлять пулами потоков в Python.
Хотя ThreadPoolExecutor был доступен начиная с Python 3.2, он не получил широкого распространения, возможно, из-за непонимания возможностей и ограничений Threads в Python.
В этом руководстве подробно и всесторонне рассматривается ThreadPoolExecutor в Python, включая принцип его работы, способы использования, общие вопросы и лучшие практики.
Это огромное руководство, состоящее из 23 000+ слов. Возможно, вы захотите добавить его в закладки, чтобы обращаться к нему по мере разработки своих параллельных программ.
Давайте погрузимся внутрь.
Оглавление
- Потоки в Python и необходимость пулов потоков
- ThreadPoolExecutor для пулов потоков в Python
- Жизненный цикл ThreadPoolExecutor
- Пример работы с пулом потоков
- Шаблоны использования ThreadPoolExecutor
Потоки Python и необходимость пулов потоков
Итак, что такое потоки и почему мы заботимся о пулах потоков?
Что такое потоки Python
Поток относится к потоку выполнения компьютерной программы.
Каждая программа Python представляет собой процесс с одним потоком, называемым главным, который используется для выполнения инструкций вашей программы. Каждый процесс - это фактически один экземпляр интерпретатора Python, который выполняет инструкции Python (байткод Python), что является немного более низким уровнем, чем код, который вы вводите в свою программу Python.
Иногда нам может понадобиться создать дополнительные потоки в нашем процессе Python для одновременного выполнения задач.
Дополнительно вы можете ознакомится с основами потоков в Python.
Python предоставляет настоящие наивные (системного уровня) потоки через класс threading.Thread.
Задачу можно запустить в новом потоке, создав экземпляр класса Thread и указав функцию для запуска в новом потоке через аргумент target.
# create and configure a new thread to run a function
thread = Thread(target=task)
После создания потока его необходимо запустить, вызвав функцию start().
# start the task in a new thread
thread.start()
Затем мы можем подождать завершения задачи, присоединившись к потоку; например
# wait for the task to complete
thread.join()
Мы можем продемонстрировать это на полном примере с задачей, которая засыпает на мгновение и печатает сообщение.
Ниже приведен полный пример выполнения функции целевой задачи в отдельном потоке.
# SuperFastPython.com
# example of executing a target task function in a separate thread
from time import sleep
from threading import Thread
# a simple task that blocks for a moment and prints a message
def task():
# block for a moment
sleep(1)
# display a message
print('This is coming from another thread')
# create and configure a new thread to run a function
thread = Thread(target=task)
# start the task in a new thread
thread.start()
# display a message
print('Waiting for the new thread to finish...')
# wait for the task to complete
thread.join()
Запуск примера создает объект потока для выполнения функции task().
Поток запускается, а функция task() выполняется в другом потоке. Задача на мгновение засыпает; тем временем в главном потоке печатается сообщение о том, что мы ждем, и главный поток присоединяется к новому потоку.
Наконец, новый поток заканчивает спать, печатает сообщение и закрывается. После этого основной поток продолжает работу и также закрывается, поскольку больше нет инструкций для выполнения.
Waiting for the new thread to finish...
This is coming from another thread
Подробнее о потоках Python вы можете узнать из руководства:
Это полезно для выполнения разовых специальных задач в отдельном потоке, но становится громоздким, когда нужно выполнить много задач.
Каждый создаваемый поток требует применения ресурсов (например, памяти для стекового пространства потока). Вычислительные затраты на создание потоков могут стать дорогостоящими, если мы будем создавать и уничтожать множество потоков снова и снова для решения специальных задач.
Вместо этого мы предпочли бы сохранить рабочие потоки для повторного использования, если мы ожидаем выполнения множества специальных задач в нашей программе.
Этого можно добиться с помощью пула потоков.
Что такое пулы потоков
Пул потоков - это шаблон программирования для автоматического управления пулом рабочих потоков.
Пул отвечает за фиксированное количество потоков.
- Он управляет тем, когда создаются потоки, например, непосредственно в момент, когда они необходимы.
- Он также контролирует, что должны делать потоки, когда они не используются, например, заставлять их ждать, не потребляя вычислительных ресурсов.
Каждый поток в пуле называется рабочим или рабочей нитью. Каждый рабочий поток не зависит от типа выполняемых задач, а пользователь пула потоков может выполнять набор схожих (однородных) или несхожих (разнородных) задач с точки зрения вызываемой функции, аргументов функции, длительности задачи и т. д.
Рабочие потоки предназначены для повторного использования после завершения задачи и обеспечивают защиту от неожиданного сбоя задачи, например, от возникновения исключения, не затрагивая сам рабочий поток.
В отличие от одиночного потока, который настроен на выполнение одной конкретной задачи.
Пул может предоставлять некоторые возможности для настройки рабочих потоков, например, запуск функции инициализации и именование каждого рабочего потока с использованием определенного соглашения об именовании.
Пулы потоков могут предоставить общий интерфейс для выполнения специальных задач с переменным числом аргументов, но не требуют выбора потока для выполнения задачи, запуска потока или ожидания завершения задачи.
Использование пула потоков вместо ручного запуска, управления и закрытия потоков может быть значительно эффективнее, особенно при большом количестве задач.
Python предоставляет пул потоков с помощью класса ThreadPoolExecutor.
Запускайте циклы, используя все процессоры, скачайте БЕСПЛАТНУЮ книгу, чтобы узнать, как это сделать.
ThreadPoolExecutor для пулов потоков в Python
Класс ThreadPoolExecutor Python используется для создания и управления пулами потоков и предоставляется в модуле concurrent.futures.
Модуль concurrent.futures появился в Python 3.2, написанном Брайаном Куинланом, и предоставляет как пулы потоков, так и пулы процессов, хотя в этом руководстве мы сосредоточим свое внимание на пулах потоков.
Если вам интересно, вы можете получить доступ к исходному коду класса ThreadPoolExecutor на языке Python непосредственно через thread.py. Возможно, будет интересно разобраться с тем, как класс работает внутри, после того, как вы ознакомитесь с тем, как он работает снаружи.
Класс ThreadPoolExecutor расширяет класс Executor и при вызове будет возвращать объекты Future.
- Executor: Родительский класс для ThreadPoolExecutor, определяющий основные операции жизненного цикла пула.
- Future: Объект, возвращаемый при отправке задач в пул потоков, которые могут завершиться позже.
Давайте подробнее рассмотрим Executors, Futures и жизненный цикл использования класса ThreadPoolExecutor.
Что такое душеприказчики
Класс ThreadPoolExecutor расширяет абстрактный класс Executor.
Класс Executor определяет три метода, используемые для управления нашим пулом потоков; это: submit(), map() и shutdown().
- submit(): Отправляйте функцию на выполнение и возвращайте будущий объект.
- map(): Применяет функцию к итерируемому множеству элементов.
- shutdown(): Завершение работы исполнителя.
При создании класса запускается Executor, который должен быть выключен явным образом вызовом shutdown(), что приведет к освобождению всех ресурсов, удерживаемых Executor. Мы также можем завершить работу автоматически, но об этом мы поговорим чуть позже.
Функции submit() и map() используются для отправки задач исполнителю для асинхронного выполнения.
Функция map() работает так же, как и встроенная функция map(), и используется для применения функции к каждому элементу итерируемого объекта, например списка. В отличие от встроенной функции map(), каждое применение функции к элементу будет происходить асинхронно, а не последовательно.
Функция submit() принимает функцию, а также любые аргументы и выполняет ее асинхронно, хотя вызов возвращается немедленно и предоставляет объект Future.
В ближайшее время мы рассмотрим каждую из этих трех функций подробнее. Во-первых, что такое будущее?
Что такое фьючерсы
Будущее - это объект, который представляет отложенный результат для асинхронной задачи.
Иногда его также называют обещанием или отсрочкой. Он обеспечивает контекст для результата задачи, которая может выполняться или не выполняться, и способ получения результата, как только он станет доступен.
В Python объект Future возвращается из Executor, например ThreadPoolExecutor при вызове функции submit() для отправки задачи на асинхронное выполнение.
В общем случае мы не создаем объекты Future; мы только получаем их, и нам может понадобиться вызвать функции для них.
Всегда существует один объект Future для каждой задачи, отправленной в ThreadPoolExecutor через вызов submit().
Объект Future предоставляет ряд полезных функций для проверки состояния задачи, таких как: cancelled(), running() и done(), чтобы определить, была ли задача отменена, выполняется ли она в данный момент или завершила выполнение.
- cancelled(): Возвращает True, если задача была отменена до выполнения.
- running(): Возвращает True, если задача в данный момент запущена.
- done(): Возвращает True, если задача завершилась или была отменена.
Выполненное задание не может быть отменено, а выполненное задание могло быть отменено.
Объект Future также предоставляет доступ к результату выполнения задачи через функцию result(). Если при выполнении задачи было поднято исключение, оно будет повторно поднято при вызове функции result() или может быть доступно через функцию exception().
- result(): Доступ к результату выполнения задачи.
- exception(): Доступ к любому исключению, возникшему во время выполнения задачи.
В функциях result() и exception() можно указать в качестве аргумента таймаут - количество секунд, в течение которых следует ждать возврата значения, если задача еще не завершена. Если таймаут истечет, то будет выдано сообщение TimeoutError.
Наконец, мы можем захотеть, чтобы пул потоков автоматически вызывал функцию после завершения задачи.
Этого можно добиться, присоединив обратный вызов к объекту Future для задачи с помощью функции add_done_callback().
- add_done_callback(): Добавляет к задаче функцию обратного вызова, которая будет выполнена пулом потоков после завершения задачи.
Мы можем добавить более одного обратного вызова к каждой задаче, и они будут выполняться в том порядке, в котором были добавлены. Если задача уже завершилась до того, как мы добавили обратный вызов, то обратный вызов будет выполнен немедленно.
Любые исключения, возникающие в функции обратного вызова, не влияют на задачу или пул потоков.
Более подробно мы рассмотрим объект Future в одном из следующих разделов.
Теперь, когда мы знакомы с функциональностью ThreadPoolExecutor, предоставляемой классом Executor, и с объектами Future, возвращаемыми вызовом submit(), давайте подробнее рассмотрим жизненный цикл класса ThreadPoolExecutor.
Запутались в API класса ThreadPoolExecutor? Скачайте БЕСПЛАТНУЮ шпаргалку PDF
Жизненный цикл ThreadPoolExecutor
Исполнитель ThreadPoolExecutor предоставляет пул общих рабочих потоков.
Исполнитель ThreadPoolExecutor был разработан, чтобы быть простым и понятным в использовании.
Если бы многопоточность была похожа на коробку передач для переключения передач в автомобиле, то использование threading.Thread - это ручная коробка передач (например, трудно изучить и использовать), тогда как concurrency.futures.ThreadPoolExecutor - это автоматическая коробка передач (например, легко изучить и использовать).
- threading.Thread: Ручное управление потоками в Python.
- concurrency.futures.ThreadPoolExecutor: Автоматический или "просто работающий" режим для работы с потоками в Python.
В жизненном цикле использования класса ThreadPoolExecutor есть четыре основных этапа: создание, отправка, ожидание и завершение работы.
- 1. Создание: Создайте пул потоков, вызвав конструктор ThreadPoolExecutor().
- 2. Отправка: Отправляйте задания и получайте фьючерсы, вызывая submit() или map().
- 3. Ожидание: Ожидание и получение результатов по мере выполнения задач (необязательно).
- 4. Завершение работы: Выключите пул потоков, вызвав shutdown().
Следующий рисунок помогает представить жизненный цикл класса ThreadPoolExecutor.
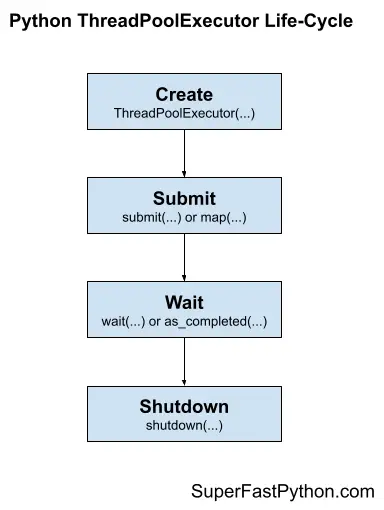
Давайте рассмотрим каждый этап жизненного цикла по очереди.
Шаг 1. Создание пула потоков
Сначала необходимо создать экземпляр ThreadPoolExecutor.
При создании экземпляра ThreadPoolExecutor он должен быть настроен на фиксированное количество потоков в пуле, префикс, используемый при именовании каждого потока в пуле, и имя функции для вызова при инициализации каждого потока вместе с аргументами для функции.
Пул создается с одним потоком для каждого процессора в вашей системе плюс четыре. Это подходит для большинства целей.
- По умолчанию
Общее количество потоков = (Общее количество CPU) + 4
Например, если у вас 4 процессора, каждый с гиперпоточностью (большинство современных процессоров имеют ее), то Python увидит 8 процессоров и выделит (8 + 4) или 12 потоков в пул по умолчанию.
# create a thread pool with the default number of worker threads
executor = ThreadPoolExecutor()
Неплохо бы протестировать ваше приложение, чтобы определить количество потоков, обеспечивающее наилучшую производительность, - от нескольких до сотен потоков.
Обычно не стоит иметь тысячи потоков, так как это может повлиять на объем доступной оперативной памяти и привести к большому количеству переключений между потоками, что может привести к ухудшению производительности.
Подробнее о настройке количества потоков для вашего пула мы поговорим позже.
Вы можете указать количество потоков для создания пула с помощью аргумента max_workers; например:
# create a thread pool with 10 worker threads
executor = ThreadPoolExecutor(max_workers=10)
Шаг 2. Передача заданий в пул потоков
После создания пула потоков можно отправлять задания на асинхронное выполнение.
Как уже говорилось, существует два основных подхода к представлению задач, определенных на родительском классе Executor. Это map() и submit().
Шаг 2a. Передача заданий с помощью map()
Функция map() - это асинхронная версия встроенной функции map() для применения функции к каждому элементу итерируемого объекта, например списка.
Вы можете вызвать функцию map() на пуле и передать ей имя вашей функции и итерируемую переменную.
Вы, скорее всего, используете map() при преобразовании цикла for для запуска с использованием одного потока на итерацию цикла.
# perform all tasks in parallel
results = pool.map(my_task, my_items) # does not block
Где "my_task" - это ваша функция, которую вы хотите выполнить, а "my_items" - это итерация объектов, каждый из которых будет выполнен вашей функцией "my_task".
Задачи будут ставиться в очередь в пуле потоков и выполняться рабочими потоками в пуле по мере их поступления.
Функция map() сразу же возвращает итерируемый объект. Эта итерабель может быть использована для доступа к результатам из целевой функции задачи, поскольку они доступны в том порядке, в котором были представлены задачи (например, в порядке предоставленной вами итерабели).
# iterate over results as they become available
for result in executor.map(my_task, my_items):
print(result)
Вы также можете задать таймаут при вызове map() через аргумент "timeout" в секундах, если вы хотите установить ограничение на время ожидания завершения каждой задачи в процессе итерации, после чего будет выдана ошибка TimeOut.
# perform all tasks in parallel
# iterate over results as they become available
for result in executor.map(my_task, my_items, timeout=5):
# wait for task to complete or timeout expires
print(result)
2a. Отправить задание с помощью submit()
Функция submit() отправляет одну задачу в пул потоков для выполнения.
Функция принимает имя вызываемой функции и все аргументы к ней, а затем немедленно возвращает объект Future.
Объект Future представляет собой обещание вернуть результаты выполнения задачи (если таковые имеются) и обеспечивает способ определения того, была ли конкретная задача выполнена или нет.
# submit a task with arguments and get a future object
future = executor.submit(my_task, arg1, arg2) # does not block
Где "my_task" - это функция, которую вы хотите выполнить, а "arg1" и "arg2" - первый и второй аргументы для передачи в функцию "my_task".
Вы можете использовать функцию submit() для отправки заданий, которые не принимают никаких аргументов; например:
# submit a task with no arguments and get a future object
future = executor.submit(my_task) # does not block
Получить доступ к результату выполнения задачи можно с помощью функции result() на возвращаемом объекте Future. Этот вызов будет блокироваться до тех пор, пока задача не будет завершена.
# get the result from a future
result = future.result() # blocks
Вы также можете задать таймаут при вызове result() с помощью аргумента "timeout" в секундах, если хотите установить ограничение на время ожидания завершения каждой задачи, по истечении которого будет выдана ошибка TimeOut.
# wait for task to complete or timeout expires
result = future.result(timeout=5) # blocks
Шаг 3. Дождитесь завершения заданий (необязательно)
Модуль concurrent.futures предоставляет две служебные функции модуля для ожидания задач через их объекты Future.
Напомните, что объекты Future создаются только тогда, когда мы вызываем submit(), чтобы поместить задачи в пул потоков.
Эти функции ожидания использовать необязательно, так как вы можете ждать результатов непосредственно после вызова map() или submit() или дождаться завершения всех задач в пуле потоков.
Эти две функции модуля - wait() для ожидания завершения работы объектов Future и as_completed() для получения объектов Future по мере завершения их задач.
- wait(): Ожидание одного или нескольких объектов Future до их завершения.
- as_completed(): Возвращает объекты Future из коллекции по мере завершения их выполнения.
Вы можете использовать обе функции с объектами Future, созданными одним или несколькими пулами потоков, они не являются специфичными для какого-либо конкретного пула потоков в вашем приложении. Это удобно, если вы хотите выполнять операции ожидания в нескольких пулах потоков, выполняющих различные типы задач.
Обе функции полезно использовать с идиомой отправки нескольких задач в пул потоков через submit в сжатии списка; например:
# dispatch tasks into the thread pool and create a list of futures
futures = [executor.submit(my_task, my_data) for my_data in my_datalist]
Здесь my_task - это наша пользовательская целевая функция задачи, "my_data" - это один элемент данных, переданный в качестве аргумента "my_task", а "my_datalist" - это наш источник объектов my_data.
Затем мы можем передать объекты Future в wait() или as_completed().
Создание списка объектов Future таким образом не является обязательным, просто это обычная схема при преобразовании циклов for в задачи, передаваемые в пул потоков.
Шаг 3a. Дождитесь завершения фьючерсов
Функция wait() может принимать один или несколько объектов Future и вернется, когда произойдет указанное действие, например, все задания завершатся, одно задание завершится, или одно задание вызовет исключение.
Функция вернет один набор объектов Future, которые соответствуют условию, заданному через "return_when". Второй набор будет содержать все фьючерсы для задач, не удовлетворяющих условию. Эти наборы фьючерсов называются "done" и "not_done".
Это полезно для ожидания большой партии работы и для прекращения ожидания, когда мы получим первый результат.
Это можно сделать с помощью константы FIRST_COMPLETED, передаваемой в аргументе "return_when".
# wait until we get the first result
done, not_done = wait(futures, return_when=concurrent.futures.FIRST_COMPLETED)
В качестве альтернативы мы можем дождаться завершения всех задач с помощью константы ALL_COMPLETED.
Это может быть полезно, если вы используете submit() для отправки заданий и ищете простой способ дождаться завершения всей работы.
# wait for all tasks to complete
done, not_done = wait(futures, return_when=concurrent.futures.ALL_COMPLETED)
Также есть возможность дождаться первого исключения с помощью константы FIRST_EXCEPTION.
# wait for the first exception
done, not_done = wait(futures, return_when=concurrent.futures.FIRST_EXCEPTION)
Шаг 3b. Ожидание фьючерсов как завершенное
Прелесть одновременного выполнения задач в том, что мы можем получать результаты по мере их поступления, а не ждать, пока все задачи будут завершены.
Функция as_completed() будет возвращать объекты Future для задач по мере их завершения в пуле потоков.
Мы можем вызвать функцию и предоставить ей список объектов Future, созданных вызовом submit(), и она будет возвращать объекты Future по мере их завершения в любом порядке.
Обычно функция as_completed() используется в цикле по списку объектов Future, созданных при вызове submit; например:
# iterate over all submitted tasks and get results as they are available
for future in as_completed(futures):
# get the result for the next completed task
result = future.result() # blocks
Примечание: это отличается от итерации по результатам вызова map() двумя способами. Во-первых, map() возвращает итератор над объектами, а не над объектами Future. Во-вторых, map() возвращает результаты в том порядке, в котором задания были поданы, а не в том, в котором они были выполнены.
Шаг 4. Выключите пул потоков
После выполнения всех задач мы можем закрыть пул потоков, что приведет к освобождению каждого потока и всех ресурсов, которые он может занимать (например, пространства стека потоков).
# shutdown the thread pool
executor.shutdown() # blocks
Функция shutdown() по умолчанию будет ждать завершения всех задач в пуле потоков перед возвратом.
Это поведение можно изменить, установив аргумент "wait" в значение False при вызове shutdown(), в этом случае функция вернется немедленно. Ресурсы, используемые пулом потоков, не будут освобождены до тех пор, пока все текущие и поставленные в очередь задачи не будут завершены.
# shutdown the thread pool
executor.shutdown(wait=False) # does not blocks
Мы также можем поручить пулу отменить все поставленные в очередь задачи, чтобы предотвратить их выполнение. Этого можно добиться, установив аргумент "cancel_futures" в значение True. По умолчанию поставленные в очередь задачи не отменяются при вызове shutdown().
# cancel all queued tasks
executor.shutdown(cancel_futures=True) # blocks
Если мы забудем закрыть пул потоков, он будет закрыт автоматически при выходе из главного потока. Если мы забудем закрыть пул, а задачи все еще будут выполняться, главный поток не завершится, пока не будут выполнены все задачи в пуле и все поставленные в очередь задачи.
Контекстный менеджер ThreadPoolExecutor
Предпочтительным способом работы с классом ThreadPoolExecutor является использование менеджера контекста.
Это соответствует предпочтительному способу работы с другими ресурсами, такими как файлы и сокеты.
Использование ThreadPoolExecutor с контекстным менеджером предполагает использование ключевого слова "with" для создания блока, в котором вы можете использовать пул потоков для выполнения задач и получения результатов.
После завершения блока пул потоков автоматически закрывается. Внутренне менеджер контекста вызовет функцию shutdown() с аргументами по умолчанию, ожидая завершения всех поставленных в очередь и выполняющихся задач, после чего вернется и продолжит работу.
Ниже приведен фрагмент кода, демонстрирующий создание пула потоков с помощью менеджера контекста.
# create a thread pool
with ThreadPoolExecutor(max_workers=10) as pool:
# submit tasks and get results
# ...
# automatically shutdown the thread pool...
# the pool is shutdown at this point
Это очень удобная идиома, если вы преобразуете цикл for в многопоточный.
Это менее полезно, если вы хотите, чтобы пул потоков работал в фоновом режиме, пока вы выполняете другую работу в основном потоке вашей программы, или если вы хотите повторно использовать пул потоков несколько раз в течение вашей программы.
Теперь, когда мы знакомы с тем, как использовать ThreadPoolExecutor, давайте рассмотрим несколько работающих примеров.
Пример работы с пулом потоков (ThreadPoolExecutor)
В этом разделе мы рассмотрим более полный пример использования ThreadPoolExecutor.
Пожалуй, самым распространенным вариантом использования ThreadPoolExecutor является одновременная загрузка файлов из Интернета.
Это полезная проблема, потому что существует множество способов загрузки файлов. Мы будем использовать эту задачу в качестве основы для изучения различных паттернов с ThreadPoolExecutor для одновременной загрузки файлов.
Для начала разработаем серийную (неконкурентную) версию программы.
Серийная загрузка файлов
Рассмотрим ситуацию, когда мы можем захотеть иметь локальную копию некоторой документации Python API по параллелизму для последующего просмотра.
Возможно, мы летим на самолете, и у нас не будет доступа к интернету, а нам нужно будет обратиться к документации в формате HTML, как она представлена на сайте docs.python.org. Это надуманный сценарий; Python устанавливается вместе с docs, и у нас также есть команда pydoc, но согласитесь со мной.
Мы можем захотеть загрузить локальные копии следующих десяти URL-адресов, которые охватывают все возможности Python concurrency API.
Мы можем определить эти URL как список строк для обработки в нашей программе.
# python concurrency API docs
URLS = ['https://docs.python.org/3/library/concurrency.html',
'https://docs.python.org/3/library/concurrent.html',
'https://docs.python.org/3/library/concurrent.futures.html',
'https://docs.python.org/3/library/threading.html',
'https://docs.python.org/3/library/multiprocessing.html',
'https://docs.python.org/3/library/multiprocessing.shared_memory.html',
'https://docs.python.org/3/library/subprocess.html',
'https://docs.python.org/3/library/queue.html',
'https://docs.python.org/3/library/sched.html',
'https://docs.python.org/3/library/contextvars.html']
URL достаточно легко загружаются в Python.
Сначала мы можем попытаться открыть соединение с сервером с помощью функции urllib.request.urlopen(), указав URL и разумный тайм-аут в секундах.
Это создаст соединение, по которому мы сможем вызвать функцию read() для чтения содержимого файла. Использование контекстного менеджера для соединения обеспечит его автоматическое закрытие, даже если возникнет исключение.
Приведенная ниже функция download_url() реализует это, принимая в качестве параметра URL и возвращая содержимое файла или None, если файл по какой-то причине не может быть загружен. Мы установим длительный таймаут в 3 секунды на случай, если наше интернет-соединение по какой-то причине окажется нестабильным.
# download a url and return the raw data, or None on error
def download_url(url):
try:
# open a connection to the server
with urlopen(url, timeout=3) as connection:
# read the contents of the html doc
return connection.read()
except:
# bad url, socket timeout, http forbidden, etc.
return None
Получив данные для URL, мы можем сохранить их в локальном файле.
Сначала нам нужно получить имя файла, указанного в URL. Существует несколько способов сделать это, но функция os.path.basename() является общепринятым подходом при работе с путями. Затем мы можем использовать функцию os.path.join() для построения выходного пути для сохранения файла, используя указанную нами директорию и имя файла.
Затем мы можем использовать встроенную функцию open(), чтобы открыть файл в режиме записи двоичных файлов и сохранить его содержимое, снова используя менеджер контекста, чтобы убедиться, что файл закрыт, когда мы закончим.
Приведенная ниже функция save_file() реализует это, принимая URL, который был загружен, содержимое файла, который был загружен, и локальный путь вывода, где мы хотим сохранить загруженные файлы. Она возвращает путь вывода, который был использован для сохранения файла, на случай, если мы хотим сообщить пользователю о прогрессе.
# save data to a local file
def save_file(url, data, path):
# get the name of the file from the url
filename = basename(url)
# construct a local path for saving the file
outpath = join(path, filename)
# save to file
with open(outpath, 'wb') as file:
file.write(data)
return outpath
Далее мы можем вызвать функцию download_url() для заданного URL в нашем списке, а затем save_file() для сохранения каждого загруженного файла.
Приведенная ниже функция download_and_save() реализует это, сообщая о ходе выполнения и обрабатывая URL-адреса, которые не могут быть загружены.
# download and save a url as a local file
def download_and_save(url, path):
# download the url
data = download_url(url)
# check for no data
if data is None:
print(f'>Error downloading {url}')
return
# save the data to a local file
outpath = save_file(url, data, path)
# report progress
print(f'>Saved {url} to {outpath}')
Наконец, нам нужна функция, которая будет управлять процессом.
Во-первых, необходимо создать локальное место вывода, куда мы будем сохранять файлы, если оно не существует. Этого можно добиться с помощью функции os.makedirs().
Мы можем перебирать список URL-адресов и вызывать нашу функцию download_and_save() для каждого из них.
Приведенная ниже функция download_docs() реализует this.
# download a list of URLs to local files
def download_docs(urls, path):
# create the local directory, if needed
makedirs(path, exist_ok=True)
# download each url and save as a local file
for url in urls:
download_and_save(url, path)
И это все.
Затем мы можем вызвать нашу download_docs() со списком URL-адресов и выходным каталогом. В данном случае мы будем использовать подкаталог 'docs/' нашего текущего рабочего каталога (где находится Python-скрипт) в качестве выходного каталога.
Ниже приведен полный пример последовательной загрузки файлов.
# SuperFastPython.com
# download document files and save to local files serially
from os import makedirs
from os.path import basename
from os.path import join
from urllib.request import urlopen
# download a url and return the raw data, or None on error
def download_url(url):
try:
# open a connection to the server
with urlopen(url, timeout=3) as connection:
# read the contents of the html doc
return connection.read()
except:
# bad url, socket timeout, http forbidden, etc.
return None
# save data to a local file
def save_file(url, data, path):
# get the name of the file from the url
filename = basename(url)
# construct a local path for saving the file
outpath = join(path, filename)
# save to file
with open(outpath, 'wb') as file:
file.write(data)
return outpath
# download and save a url as a local file
def download_and_save(url, path):
# download the url
data = download_url(url)
# check for no data
if data is None:
print(f'>Error downloading {url}')
return
# save the data to a local file
outpath = save_file(url, data, path)
# report progress
print(f'>Saved {url} to {outpath}')
# download a list of URLs to local files
def download_docs(urls, path):
# create the local directory, if needed
makedirs(path, exist_ok=True)
# download each url and save as a local file
for url in urls:
download_and_save(url, path)
# python concurrency API docs
URLS = ['https://docs.python.org/3/library/concurrency.html',
'https://docs.python.org/3/library/concurrent.html',
'https://docs.python.org/3/library/concurrent.futures.html',
'https://docs.python.org/3/library/threading.html',
'https://docs.python.org/3/library/multiprocessing.html',
'https://docs.python.org/3/library/multiprocessing.shared_memory.html',
'https://docs.python.org/3/library/subprocess.html',
'https://docs.python.org/3/library/queue.html',
'https://docs.python.org/3/library/sched.html',
'https://docs.python.org/3/library/contextvars.html']
# local path for saving the files
PATH = 'docs'
# download all docs
download_docs(URLS, PATH)
При выполнении примера выполняется итерация по списку URL-адресов и загрузка каждого из них по очереди.
Затем каждый файл сохраняется в локальном файле в указанном каталоге.
Процесс занимает от 700 миллисекунд до одной секунды (1 000 миллисекунд) в моей системе.
Попробуйте запустить его несколько раз; сколько времени это займет на вашей системе?
Дайте мне знать в комментариях.
>Saved https://docs.python.org/3/library/concurrency.html to docs/concurrency.html
>Saved https://docs.python.org/3/library/concurrent.html to docs/concurrent.html
>Saved https://docs.python.org/3/library/concurrent.futures.html to docs/concurrent.futures.html
>Saved https://docs.python.org/3/library/threading.html to docs/threading.html
>Saved https://docs.python.org/3/library/multiprocessing.html to docs/multiprocessing.html
>Saved https://docs.python.org/3/library/multiprocessing.shared_memory.html to docs/multiprocessing.shared_memory.html
>Saved https://docs.python.org/3/library/subprocess.html to docs/subprocess.html
>Saved https://docs.python.org/3/library/queue.html to docs/queue.html
>Saved https://docs.python.org/3/library/sched.html to docs/sched.html
>Saved https://docs.python.org/3/library/contextvars.html to docs/contextvars.html
Далее мы можем посмотреть, как сделать программу параллельной, используя пул потоков.
Загрузка файлов одновременно с submit()
Давайте рассмотрим, как обновить нашу программу, чтобы использовать ThreadPoolExecutor для одновременной загрузки файлов.
Первой мыслью может быть использование map(), поскольку мы просто хотим сделать цикл for-loop concurrent.
К сожалению, функция download_and_save(), которую мы вызываем на каждой итерации цикла, принимает два параметра, только один из которых является итерируемым.
Альтернативный подход заключается в использовании submit() для вызова download_and_save() в отдельном потоке для каждого URL в предоставленном списке.
Для этого сначала нужно сконфигурировать пул потоков с количеством потоков, равным количеству URL в списке. Мы будем использовать менеджер контекста для пула потоков, чтобы он автоматически закрывался для нас, когда мы закончим работу.
Затем мы можем вызвать функцию submit() для каждого URL, используя сжатие списка. Нам даже не нужны объекты Future, возвращаемые при вызове submit, поскольку мы не ждем результата.
# create the thread pool
n_threads = len(urls)
with ThreadPoolExecutor(n_threads) as executor:
# download each url and save as a local file
_ = [executor.submit(download_and_save, url, path) for url in urls]
После завершения каждого потока менеджер контекста закроет для нас пул потоков, и мы закончим.
Нам даже не нужно добавлять явный вызов wait, хотя мы могли бы, если бы хотели сделать код более читабельным; например:
# create the thread pool
n_threads = len(urls)
with ThreadPoolExecutor(n_threads) as executor:
# download each url and save as a local file
futures = [executor.submit(download_and_save, url, path) for url in urls]
# wait for all download tasks to complete
_, _ = wait(futures)
Но добавлять это ожидание не нужно.
Ниже приведена обновленная версия нашей функции download_docs(), которая загружает и сохраняет файлы одновременно.
# download a list of URLs to local files
def download_docs(urls, path):
# create the local directory, if needed
makedirs(path, exist_ok=True)
# create the thread pool
n_threads = len(urls)
with ThreadPoolExecutor(n_threads) as executor:
# download each url and save as a local file
_ = [executor.submit(download_and_save, url, path) for url in urls]
Ниже приведен полный пример.
# SuperFastPython.com
# download document files and save to local files concurrently
from os import makedirs
from os.path import basename
from os.path import join
from urllib.request import urlopen
from concurrent.futures import ThreadPoolExecutor
# download a url and return the raw data, or None on error
def download_url(url):
try:
# open a connection to the server
with urlopen(url, timeout=3) as connection:
# read the contents of the html doc
return connection.read()
except:
# bad url, socket timeout, http forbidden, etc.
return None
# save data to a local file
def save_file(url, data, path):
# get the name of the file from the url
filename = basename(url)
# construct a local path for saving the file
outpath = join(path, filename)
# save to file
with open(outpath, 'wb') as file:
file.write(data)
return outpath
# download and save a url as a local file
def download_and_save(url, path):
# download the url
data = download_url(url)
# check for no data
if data is None:
print(f'>Error downloading {url}')
return
# save the data to a local file
outpath = save_file(url, data, path)
# report progress
print(f'>Saved {url} to {outpath}')
# download a list of URLs to local files
def download_docs(urls, path):
# create the local directory, if needed
makedirs(path, exist_ok=True)
# create the thread pool
n_threads = len(urls)
with ThreadPoolExecutor(n_threads) as executor:
# download each url and save as a local file
_ = [executor.submit(download_and_save, url, path) for url in urls]
# python concurrency API docs
URLS = ['https://docs.python.org/3/library/concurrency.html',
'https://docs.python.org/3/library/concurrent.html',
'https://docs.python.org/3/library/concurrent.futures.html',
'https://docs.python.org/3/library/threading.html',
'https://docs.python.org/3/library/multiprocessing.html',
'https://docs.python.org/3/library/multiprocessing.shared_memory.html',
'https://docs.python.org/3/library/subprocess.html',
'https://docs.python.org/3/library/queue.html',
'https://docs.python.org/3/library/sched.html',
'https://docs.python.org/3/library/contextvars.html']
# local path for saving the files
PATH = 'docs'
# download all docs
download_docs(URLS, PATH)
Запуск примера загружает и сохраняет файлы, как и прежде.
На этот раз операция завершается за доли секунды. В моем случае около 300 миллисекунд, что меньше половины времени, которое потребовалось для последовательной загрузки всех файлов в предыдущем примере.
Сколько времени заняла загрузка всех файлов в вашей системе?
>Saved https://docs.python.org/3/library/concurrent.html to docs/concurrent.html
>Saved https://docs.python.org/3/library/multiprocessing.shared_memory.html to docs/multiprocessing.shared_memory.html
>Saved https://docs.python.org/3/library/concurrency.html to docs/concurrency.html
>Saved https://docs.python.org/3/library/sched.html to docs/sched.html
>Saved https://docs.python.org/3/library/contextvars.html to docs/contextvars.html
>Saved https://docs.python.org/3/library/queue.html to docs/queue.html
>Saved https://docs.python.org/3/library/concurrent.futures.html to docs/concurrent.futures.html
>Saved https://docs.python.org/3/library/threading.html to docs/threading.html
>Saved https://docs.python.org/3/library/subprocess.html to docs/subprocess.html
>Saved https://docs.python.org/3/library/multiprocessing.html to docs/multiprocessing.html
Это один из подходов к созданию параллельной программы, но давайте рассмотрим некоторые альтернативы.
Загрузка файлов одновременно с submit() и as_completed()
Возможно, мы хотим сообщать о ходе загрузки по мере ее завершения.
Пул потоков позволяет нам сделать это, храня объекты Future, возвращаемые из вызовов submit(), а затем вызывая as_completed() на коллекции объектов Future.
Кроме того, учтите, что в задаче мы делаем две вещи. Первая - это загрузка с удаленного сервера, что является операцией, связанной с IO, которую мы можем выполнять одновременно. Вторая - сохранение содержимого файла на локальном жестком диске, что является еще одной операцией, связанной с IO, которую мы не можем выполнять одновременно, поскольку большинство жестких дисков могут сохранять только один файл за раз.
Поэтому, возможно, лучше сделать так, чтобы часть программы, связанная с загрузкой файла, была только параллельной задачей, а часть программы, связанная с сохранением файла, - последовательной.
Это потребует дополнительных изменений в программе.
Мы можем вызвать функцию download_url() для каждого URL, и это может быть нашей параллельной задачей, переданной в пул потоков.
Когда мы вызываем result() на каждом объекте Future, он выдает нам данные, которые были загружены, но мы не знаем, с какого URL они были загружены. Объект Future не будет знать.
Поэтому мы можем обновить download_url(), чтобы вернуть и данные, которые были загружены, и URL, который был предоставлен в качестве аргумента.
Ниже приведена обновленная версия функции download_url(), которая возвращает кортеж из данных и входного URL.
# download a url and return the raw data, or None on error
def download_url(url):
try:
# open a connection to the server
with urlopen(url, timeout=3) as connection:
# read the contents of the html doc
return (connection.read(), url)
except:
# bad url, socket timeout, http forbidden, etc.
return (None, url)
Затем мы можем отправить вызов этой функции на каждый URL в пул потоков, чтобы получить объект Future.
# download each url and save as a local file
futures = [executor.submit(download_url, url) for url in urls]
Пока все хорошо.
Теперь мы хотим сохранять локальные файлы и сообщать о ходе их загрузки.
Для этого нам необходимо уничтожить функцию download_and_save() и перенести ее обратно в функцию download_docs(), которая используется для управления программой.
Мы можем перебирать фьючерсы с помощью функции as_completed(), которая будет возвращать объекты Future в порядке завершения загрузки, а не в том порядке, в котором мы отправляли их в пул потоков.
Затем мы можем получить данные и URL из объекта Future.
# process each result as it is available
for future in as_completed(futures):
# get the downloaded url data
data, url = future.result()
Мы можем проверить, не была ли загрузка успешной, и сообщить об ошибке, в противном случае сохранить файл и сообщить о прогрессе, как обычно. Прямая копи-паста из функции download_and_save().
# check for no data
if data is None:
print(f'>Error downloading {url}')
continue
# save the data to a local file
outpath = save_file(url, data, path)
# report progress
print(f'>Saved {url} to {outpath}')
Ниже приведена обновленная версия нашей функции download_docs(), которая будет загружать файлы только одновременно, а затем сохранять их последовательно по мере загрузки.
# download a list of URLs to local files
def download_docs(urls, path):
# create the local directory, if needed
makedirs(path, exist_ok=True)
# create the thread pool
n_threads = len(urls)
with ThreadPoolExecutor(n_threads) as executor:
# download each url and save as a local file
futures = [executor.submit(download_url, url) for url in urls]
# process each result as it is available
for future in as_completed(futures):
# get the downloaded url data
data, url = future.result()
# check for no data
if data is None:
print(f'>Error downloading {url}')
continue
# save the data to a local file
outpath = save_file(url, data, path)
# report progress
print(f'>Saved {url} to {outpath}')
Ниже приведен полный пример.
# SuperFastPython.com
# download document files concurrently and save the files locally serially
from os import makedirs
from os.path import basename
from os.path import join
from urllib.request import urlopen
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
# download a url and return the raw data, or None on error
def download_url(url):
try:
# open a connection to the server
with urlopen(url, timeout=3) as connection:
# read the contents of the html doc
return (connection.read(), url)
except:
# bad url, socket timeout, http forbidden, etc.
return (None, url)
# save data to a local file
def save_file(url, data, path):
# get the name of the file from the url
filename = basename(url)
# construct a local path for saving the file
outpath = join(path, filename)
# save to file
with open(outpath, 'wb') as file:
file.write(data)
return outpath
# download a list of URLs to local files
def download_docs(urls, path):
# create the local directory, if needed
makedirs(path, exist_ok=True)
# create the thread pool
n_threads = len(urls)
with ThreadPoolExecutor(n_threads) as executor:
# download each url and save as a local file
futures = [executor.submit(download_url, url) for url in urls]
# process each result as it is available
for future in as_completed(futures):
# get the downloaded url data
data, url = future.result()
# check for no data
if data is None:
print(f'>Error downloading {url}')
continue
# save the data to a local file
outpath = save_file(url, data, path)
# report progress
print(f'>Saved {url} to {outpath}')
# python concurrency API docs
URLS = ['https://docs.python.org/3/library/concurrency.html',
'https://docs.python.org/3/library/concurrent.html',
'https://docs.python.org/3/library/concurrent.futures.html',
'https://docs.python.org/3/library/threading.html',
'https://docs.python.org/3/library/multiprocessing.html',
'https://docs.python.org/3/library/multiprocessing.shared_memory.html',
'https://docs.python.org/3/library/subprocess.html',
'https://docs.python.org/3/library/queue.html',
'https://docs.python.org/3/library/sched.html',
'https://docs.python.org/3/library/contextvars.html']
# local path for saving the files
PATH = 'docs'
# download all docs
download_docs(URLS, PATH)
При запуске программы файлы загружаются и сохраняются, как и раньше, возможно, на несколько миллисекунд быстрее.
Взглянув на вывод программы, мы видим, что порядок сохраненных файлов отличается.
Маленькие файлы, такие как "sched.html", которые отправлялись почти последними, загружались быстрее (например, меньше байт для загрузки) и, в свою очередь, быстрее сохранялись в локальных файлах.
Это подтверждает, что мы действительно обрабатываем загрузки в порядке выполнения заданий, а не в порядке их подачи.
>Saved https://docs.python.org/3/library/concurrent.html to docs/concurrent.html
>Saved https://docs.python.org/3/library/sched.html to docs/sched.html
>Saved https://docs.python.org/3/library/concurrency.html to docs/concurrency.html
>Saved https://docs.python.org/3/library/contextvars.html to docs/contextvars.html
>Saved https://docs.python.org/3/library/queue.html to docs/queue.html
>Saved https://docs.python.org/3/library/multiprocessing.shared_memory.html to docs/multiprocessing.shared_memory.html
>Saved https://docs.python.org/3/library/threading.html to docs/threading.html
>Saved https://docs.python.org/3/library/concurrent.futures.html to docs/concurrent.futures.html
>Saved https://docs.python.org/3/library/subprocess.html to docs/subprocess.html
>Saved https://docs.python.org/3/library/multiprocessing.html to docs/multiprocessing.html
Теперь, когда мы увидели несколько примеров, давайте рассмотрим некоторые общие шаблоны использования ThreadPoolExecutor.
Озадачены ли вы параллельными API в python? Скачайте БЕСПЛАТНЫЕ Python Concurrency Mind Maps
Паттерны использования ThreadPoolExecutor
Последователь ThreadPoolExecutor обеспечивает большую гибкость для выполнения параллельных задач в Python.
Тем не менее, существует несколько общих моделей использования, которые подойдут для большинства программных сценариев.
В этом разделе перечислены общие шаблоны использования с примерами, которые вы можете скопировать и вставить в свой собственный проект и адаптировать по мере необходимости.
Мы рассмотрим следующие шаблоны:
- Обработка и ожидание шаблона
- Отправить и использовать как завершенный образец
- Отправить и использовать последовательно
- Отправить и использовать обратный вызов
- Отправить и дождаться всех шаблон
- Отправить и дождаться первого шаблона
В каждом примере мы будем использовать надуманную задачу, которая будет спать в течение случайного времени, меньшего, чем одна секунда. Вы можете легко заменить эту задачу на свою собственную в каждом примере.
Кроме того, напомним, что в каждой программе Python по умолчанию есть один поток, называемый главным, в котором мы и выполняем свою работу. Мы будем создавать пул потоков в главном потоке в каждом примере и можем ссылаться на действия в главном потоке в некоторых паттернах, в отличие от действий в потоках в пуле потоков.
Паттерн отображения и ожидания
Пожалуй, самый распространенный паттерн при использовании ThreadPoolExecutor - это преобразование цикла for, выполняющего функцию для каждого элемента коллекции, для использования потоков.
Предполагается, что функция не имеет побочных эффектов, то есть она не обращается к данным за пределами функции и не изменяет предоставленные ей данные. Она принимает данные и выдает результат.
Такие типы циклов for могут быть явно написаны в Python; например:
# apply a function to each element in a collection
for item in mylist:
result = task(item)
Лучше использовать встроенную функцию map(), которая применит функцию к каждому элементу итерабельной таблицы за вас.
# apply the function to each element in the collection
results = map(task, mylist)
Это не выполняет функцию task() для каждого элемента, пока мы не выполним итерацию результатов, так называемое ленивое оценивание:
# iterate the results from map
for result in results:
print(result)
Поэтому обычно эта операция сводится к следующему:
# iterate the results from map
for result in map(task, mylist):
print(result)
Мы можем выполнить эту же операцию, используя пул потоков, только каждое применение функции к элементу списка - это задача, которая выполняется асинхронно. Например:
# iterate the results from map
for result in executor.map(task, mylist):
print(result)
Хотя задачи выполняются параллельно, результаты итерируются в порядке итерируемой таблицы, предоставляемой функции map(), как и встроенной функции map().
Таким образом, мы можем рассматривать версию пула потоков map() как параллельную версию функции map(), и это идеальный вариант, если вы хотите обновить цикл for, чтобы использовать потоки.
Нижеприведенный пример демонстрирует использование шаблона map and wait с задачей, которая будет спать случайное количество времени меньше одной секунды и вернет указанное значение.
# SuperFastPython.com
# example of the map and wait pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
return name
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# execute tasks concurrently and process results in order
for result in executor.map(task, range(10)):
# retrieve the result
print(result)
Запустив пример, мы видим, что результаты выдаются в том порядке, в котором задачи были созданы и отправлены в пул потоков.
0
1
2
3
4
5
6
7
8
9
Функция map() поддерживает целевые функции, принимающие более одного аргумента, путем предоставления более чем iterable в качестве аргументов при вызове map().
Например, мы можем определить целевую функцию для map, которая принимает два аргумента, а затем предоставить две итерации одинаковой длины для вызова map.
Полный пример приведен ниже.
# SuperFastPython.com
# example of calling map with two iterables
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(value1, value2):
# sleep for less than a second
sleep(random())
return (value1, value2)
# start the thread pool
with ThreadPoolExecutor() as executor:
# submit all tasks
for result in executor.map(task, ['1', '2', '3'], ['a', 'b', 'c']):
print(result)
Запуск примера выполняет задачи, как и ожидалось, предоставляя два аргумента для map и сообщая результат, который объединяет оба аргумента.
('1', 'a')
('2', 'b')
('3', 'c')
При вызове функции map все задания будут немедленно переданы в пул потоков, даже если вы не будете итерировать итерабель результатов.
В отличие от встроенной функции map(), которая является ленивой и не вычисляет каждый вызов, пока вы не запросите результат во время итерации.
Приведенный ниже пример подтверждает это, выдавая все задания с картой и не итерируя результаты.
# SuperFastPython.com
# example of calling map and not iterating the results
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(value):
# sleep for less than a second
sleep(random())
print(f'Done: {value}')
return value
# start the thread pool
with ThreadPoolExecutor() as executor:
# submit all tasks
executor.map(task, range(5))
print('All done!')
Запустив пример, мы видим, что задачи отправляются в пул потоков и выполняются без необходимости явно передавать итерабель результатов, который был возвращен.
Использование менеджера контекста позволило не завершать работу пула потоков до тех пор, пока все задачи не будут выполнены.
Done: 0
Done: 2
Done: 1
Done: 3
Done: 4
All done!
Отправить и использовать как завершенный
Пожалуй, второй наиболее распространенный паттерн при использовании ThreadPoolExecutor - это отправка заданий и использование результатов по мере их поступления.
Этого можно достичь, используя функцию submit() для передачи задач в пул потоков, который возвращает объекты Future, затем вызывая метод модуля as_completed() на списке объектов Future, который будет возвращать каждый объект Future по мере выполнения его задачи.
Пример ниже демонстрирует эту схему, представляя задания в порядке от 0 до 9 и показывая результаты в том порядке, в котором они были выполнены.
# SuperFastPython.com
# example of the submit and use as completed pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
return name
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# process task results as they are available
for future in as_completed(futures):
# retrieve the result
print(future.result())
Запустив пример, мы видим, что результаты извлекаются и выводятся в порядке выполнения заданий, а не в том порядке, в котором задания были отправлены в пул потоков.
5
9
6
1
0
7
3
8
4
2
Подавать и использовать последовательно
Мы можем потребовать результаты выполнения заданий в том порядке, в котором они были представлены.
Это может быть связано с тем, что задания имеют естественную упорядоченность.
Мы можем реализовать этот паттерн, вызывая submit() для каждой задачи, чтобы получить список объектов Future, затем итерируя объекты Future в том порядке, в котором задачи были представлены, и получая результаты.
Основное отличие от шаблона "as completed" заключается в том, что мы перечисляем список фьючерсов напрямую, а не вызываем функцию as_completed().
# process task results in the order they were submitted
for future in futures:
# retrieve the result
print(future.result())
Приведенный ниже пример демонстрирует эту схему, отправляя задания в порядке от 0 до 9 и показывая результаты в том порядке, в котором они были отправлены.
# SuperFastPython.com
# example of the submit and use sequentially pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
return name
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# process task results in the order they were submitted
for future in futures:
# retrieve the result
print(future.result())
Выполнив пример, мы видим, что результаты извлекаются и печатаются в том порядке, в котором задания были отправлены, а не в том, в котором они были выполнены.
0
1
2
3
4
5
6
7
8
9
Отправить и использовать обратный вызов
Возможно, мы не захотим явно обрабатывать результаты, как только они станут доступны; вместо этого мы хотим вызвать функцию для результата.
Вместо того чтобы делать это вручную, как в приведенном выше шаблоне as completed, мы можем заставить пул потоков вызвать функцию для нас с результатом автоматически.
Этого можно добиться, установив обратный вызов на каждый объект Future, вызвав функцию add_done_callback() и передав ей имя функции.
Затем пул потоков будет вызывать функцию обратного вызова по мере завершения каждой задачи, передавая объекты Future для задачи.
Нижеприведенный пример демонстрирует этот шаблон, регистрируя пользовательскую функцию обратного вызова, которая будет применяться к каждой задаче по мере ее выполнения.
# SuperFastPython.com
# example of the submit and use a callback pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
return name
# custom callback function called on tasks when they complete
def custom_callback(fut):
# retrieve the result
print(fut.result())
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# register the callback on all tasks
for future in futures:
future.add_done_callback(custom_callback)
# wait for tasks to complete...
Выполнив пример, мы видим, что результаты извлекаются и печатаются в порядке их выполнения, а не в том порядке, в котором задания были выполнены.
8
0
7
1
4
6
5
3
2
9
Мы можем зарегистрировать несколько обратных вызовов для каждого объекта Future; он не ограничен одним обратным вызовом.
Функции обратного вызова вызываются в том порядке, в котором они были зарегистрированы для каждого объекта Future.
Следующий пример демонстрирует наличие двух обратных вызовов для каждого Future.
# SuperFastPython.com
# example of the submit and use multiple callbacks for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
return name
# custom callback function called on tasks when they complete
def custom_callback1(fut):
# retrieve the result
print(f'Callback 1: {fut.result()}')
# custom callback function called on tasks when they complete
def custom_callback2(fut):
# retrieve the result
print(f'Callback 2: {fut.result()}')
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# register the callbacks on all tasks
for future in futures:
future.add_done_callback(custom_callback1)
future.add_done_callback(custom_callback2)
# wait for tasks to complete...
Выполнив пример, мы видим, что результаты сообщаются в порядке выполнения задач и что две функции обратного вызова вызываются для каждой задачи в том порядке, в котором мы зарегистрировали их для каждого объекта Future.
Callback 1: 3
Callback 2: 3
Callback 1: 9
Callback 2: 9
Callback 1: 7
Callback 2: 7
Callback 1: 2
Callback 2: 2
Callback 1: 0
Callback 2: 0
Callback 1: 5
Callback 2: 5
Callback 1: 1
Callback 2: 1
Callback 1: 8
Callback 2: 8
Callback 1: 4
Callback 2: 4
Callback 1: 6
Callback 2: 6
Отправить и ждать всех
Обычно нужно отправить все задания, а затем дождаться завершения всех заданий в пуле потоков.
Этот шаблон может быть полезен, когда задачи не возвращают результат напрямую, например, если каждая задача хранит результат в каком-либо ресурсе, например, в файле.
Для ожидания завершения задач существует два способа: вызов функции модуля wait() или вызов shutdown().
Наиболее вероятный случай - вы хотите явно дождаться завершения набора или подмножества задач в пуле потоков.
Вы можете добиться этого, передав список задач в функцию wait(), которая по умолчанию будет ждать завершения всех задач.
# wait for all tasks to complete
wait(futures)
Мы можем явно указать на ожидание всех задач, установив аргумент "return_when" в константу ALL_COMPLETED; например:
# wait for all tasks to complete
wait(futures, return_when=ALL_COMPLETED)
<<<Пример ниже демонстрирует эту схему. Обратите внимание, что мы намеренно игнорируем возврат после вызова wait(), поскольку в данном случае нам не нужно его проверять.
# SuperFastPython.com
# example of the submit and wait for all pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
# display the result
print(name)
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# wait for all tasks to complete
wait(futures)
print('All tasks are done!')
Запустив пример, мы видим, что результаты обрабатываются каждой задачей по мере ее выполнения. Важно отметить, что главный поток ожидает завершения всех задач, прежде чем продолжить выполнение и вывести сообщение.
3
9
0
8
4
6
2
1
5
7
All tasks are done!
Альтернативный подход заключается в том, чтобы выключить пул потоков и дождаться завершения всех выполняемых и поставленных в очередь задач, прежде чем двигаться дальше.
Это может быть предпочтительнее, когда у нас нет списка объектов Future или когда мы собираемся использовать пул потоков только один раз для набора задач.
Мы можем реализовать этот паттерн с помощью менеджера контекста; например:
# SuperFastPython.com
# example of the submit and wait for all with shutdown pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
# display the result
print(name)
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# wait for all tasks to complete
print('All tasks are done!')
Запустив пример, мы видим, что главный поток не переходит к печати сообщения до тех пор, пока не будут выполнены все задачи, после того как пул потоков будет автоматически закрыт менеджером контекста.
1
2
8
4
5
3
9
0
7
6
All tasks are done!
Шаблон автоматического отключения контекстного менеджера может смутить разработчиков, не знакомых с работой пулов потоков, поэтому в предыдущем примере в конце блока контекстного менеджера есть комментарий.
Мы можем добиться того же эффекта без менеджера контекста и явного вызова shutdown.
# wait for all tasks to complete and close the pool
executor.shutdown()
Напомните, что функция shutdown() по умолчанию будет ждать завершения всех задач и не отменит ни одной поставленной в очередь задачи, но мы можем сделать это явным, установив аргумент "wait" в True и аргумент "cancel_futures" в False; например:
# wait for all tasks to complete and close the pool
executor.shutdown(wait=True, cancel_futures=False)
Приведенный ниже пример демонстрирует модель ожидания завершения всех задач в пуле потоков путем вызова shutdown(), прежде чем двигаться дальше.
# SuperFastPython.com
# example of the submit and wait for all with shutdown pattern for the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
# display the result
print(name)
# start the thread pool
executor = ThreadPoolExecutor(10)
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# wait for all tasks to complete
executor.shutdown()
print('All tasks are done!')
Запустив пример, мы видим, что все задачи сообщают о своем результате по мере завершения и что главный поток не переходит к выполнению до тех пор, пока все задачи не будут завершены и пул потоков не будет закрыт.
3
5
2
6
8
9
7
1
4
0
All tasks are done!
Отправить и ждать первого
Обычно можно выдать много заданий, и беспокоиться только о первом полученном результате.
То есть не результат первой задачи, а результат любой задачи, которая первой завершает свое выполнение.
Это может произойти, если вы пытаетесь получить доступ к одному и тому же ресурсу из нескольких мест, например к файлу или каким-то данным.
Этого можно добиться, используя функцию модуля wait() и установив аргумент "return_when" в константу FIRST_COMPLETED.
# wait until any task completes
done, not_done = wait(futures, return_when=FIRST_COMPLETED)
Мы также должны управлять пулом потоков вручную, создавая его и вызывая shutdown() вручную, чтобы мы могли продолжить выполнение главного потока, не дожидаясь завершения всех остальных задач.
Приведенный ниже пример демонстрирует эту схему и прекращает ожидание, как только первая задача будет выполнена.
# SuperFastPython.com
# example of the submit and wait for first the ThreadPoolExecutor
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
from concurrent.futures import FIRST_COMPLETED
# custom task that will sleep for a variable amount of time
def task(name):
# sleep for less than a second
sleep(random())
return name
# start the thread pool
executor = ThreadPoolExecutor(10)
# submit tasks and collect futures
futures = [executor.submit(task, i) for i in range(10)]
# wait until any task completes
done, not_done = wait(futures, return_when=FIRST_COMPLETED)
# get the result from the first task to complete
print(done.pop().result())
# shutdown without waiting
executor.shutdown(wait=False, cancel_futures=True)
Запустив пример, мы дождемся завершения любой из задач, затем получим результат первой выполненной задачи и выключим пул потоков.
Важно, что задачи будут продолжать выполняться в пуле потоков в фоновом режиме, а главный поток не будет закрываться до тех пор, пока все задачи не завершатся.
9
Теперь, когда мы рассмотрели некоторые общие шаблоны использования ThreadPoolExecutor, давайте посмотрим, как мы можем настроить конфигурацию пула потоков.
Как настроить ThreadPoolExecutor
Мы можем настроить конфигурацию пула потоков при создании экземпляра ThreadPoolExecutor.
Есть три аспекта пула потоков, которые мы можем захотеть настроить для нашего приложения; это количество рабочих потоков, имена потоков в пуле и инициализация каждого потока в пуле.
Давайте рассмотрим каждый из них по очереди.
Настройте количество потоков
Количество потоков в пуле потоков может быть задано аргументом "max_workers".
Он принимает целое положительное число и по умолчанию равен количеству процессоров в вашей системе плюс четыре.
- Общее количество рабочих потоков = (CPU в вашей системе) + 4
Например, если у вас в системе 2 физических процессора и каждый из них имеет гиперпоточность (распространенную в современных процессорах), то у вас будет 2 физических и 4 логических процессора. Python будет видеть 4 процессора. Тогда количество рабочих потоков в вашей системе по умолчанию будет равно (4 + 4) или 8.
Если это число окажется больше 32 (например, 16 физических ядер, 32 логических ядра, плюс четыре), то по умолчанию верхняя граница будет ограничена 32 потоками.
Обычно в системе больше потоков, чем процессоров (физических или логических).
Причина этого в том, что потоки используются для задач, связанных с IO, а не с процессором. Это означает, что потоки используются для задач, которые ждут ответа от относительно медленных ресурсов, таких как жесткие диски, DVD-приводы, принтеры, сетевые соединения и многое другое. Мы обсудим наилучшее применение потоков в следующем разделе.
Поэтому нередко в приложении могут быть десятки, сотни и даже тысячи потоков, в зависимости от ваших конкретных потребностей. Необычно иметь более одного или нескольких тысяч потоков. Если вам требуется такое количество потоков, то можно предпочесть альтернативные решения, например AsyncIO. Мы обсудим Threads vs. AsyncIO в одном из следующих разделов.
Сначала давайте проверим, сколько потоков создано для пулов потоков в вашей системе.
Взглянув на исходный код ThreadPoolExecutor, мы увидим, что количество рабочих потоков, выбранных по умолчанию, хранится в свойстве _max_workers, к которому мы можем получить доступ и сообщить о нем после создания пула потоков.
Примечание: "_max_workers" является защищенным членом и может измениться в будущем.
В приведенном ниже примере сообщается о количестве потоков по умолчанию в пуле потоков вашей системы.
# SuperFastPython.com
# report the default number of worker threads on your system
from concurrent.futures import ThreadPoolExecutor
# create a thread pool with the default number of worker threads
pool = ThreadPoolExecutor()
# report the number of worker threads chosen by default
print(pool._max_workers)
Запуск примера сообщает о количестве рабочих потоков, используемых по умолчанию в вашей системе.
У меня четыре физических ядра процессора и восемь логических ядер; поэтому по умолчанию используется 8 + 4 или 12 потоков.
12
Сколько рабочих потоков выделено по умолчанию в вашей системе?
Дайте мне знать в комментариях ниже.
Мы можем указать количество рабочих потоков напрямую, и это хорошая идея в большинстве приложений.
В примере ниже показано, как настроить 500 рабочих потоков.
# SuperFastPython.com
# configure and report the default number of worker threads
from concurrent.futures import ThreadPoolExecutor
# create a thread pool with a large number of worker threads
pool = ThreadPoolExecutor(500)
# report the number of worker threads
print(pool._max_workers)
Запуск примера настраивает пул потоков на использование 500 потоков и подтверждает, что он создаст 500 потоков.
500
Сколько нитей следует использовать?
Если у вас сотни задач, вам, вероятно, следует установить количество потоков равным количеству задач.
Если у вас тысячи задач, вам, вероятно, следует ограничить количество потоков сотнями или 1 000.
Если ваше приложение предполагается выполнять несколько раз в будущем, вы можете протестировать разное количество потоков и сравнить общее время выполнения, а затем выбрать количество потоков, которое дает примерно наилучшую производительность. Возможно, вы захотите сымитировать задачу в этих тестах с помощью случайной операции сна.
Настройте имена потоков
У каждого потока в Python есть имя.
Главный поток имеет имя "MainThread". Вы можете получить доступ к главному потоку через вызов функции main_thread() в модуле потоков и затем получить доступ к члену name. Например:
# access the name of the main thread
from threading import main_thread
# access the main thread
thread = main_thread()
# report the thread name
print(thread.name)
Запуск примера открывает доступ к главному потоку и сообщает его имя.
MainThread
Имена по умолчанию уникальны.
Это может быть полезно при отладке программы с несколькими потоками. Сообщения журнала могут сообщать о потоке, выполняющем определенный шаг, или отладка может быть использована для отслеживания потока с определенным именем.
При создании потоков в пуле потоков каждый поток имеет имя "ThreadPoolExecutor-%d_%d", где первый %d указывает номер пула потоков, а второй %d - номер потока, причем оба в порядке создания пулов потоков и потоков.
Мы можем увидеть это, если обратимся к потокам непосредственно внутри пула после выделения некоторого количества работы, чтобы все потоки были созданы.
Мы можем перечислить все потоки в программе (процессе) Python с помощью функции enumerate() в модуле threading, а затем сообщить имя каждого из них.
В приведенном ниже примере создается пул потоков с количеством потоков по умолчанию, выделяется работа для пула, чтобы обеспечить создание потоков, затем сообщаются имена всех потоков в программе.
# SuperFastPython.com
# report the default name of threads in the thread pool
import threading
from concurrent.futures import ThreadPoolExecutor
# a mock task that does nothing
def task(name):
pass
# create a thread pool
executor = ThreadPoolExecutor()
# execute asks
executor.map(task, range(10))
# report all thread names
for thread in threading.enumerate():
print(thread.name)
# shutdown the thread pool
executor.shutdown()
Запуск примера сообщает имена всех потоков в системе, показывая сначала имя главного потока и имена четырех потоков в пуле.
В данном случае было создано всего 4 потока, поскольку задания выполнялись так быстро. Напомним, что рабочие потоки используются после того, как они завершают выполнение своих задач. Эта возможность повторного использования рабочих потоков является основным преимуществом использования пулов потоков.
MainThread
ThreadPoolExecutor-0_0
ThreadPoolExecutor-0_1
ThreadPoolExecutor-0_2
ThreadPoolExecutor-0_3
"ThreadPoolExecutor-%d" является префиксом для всех потоков в пуле потоков, и мы можем настроить его с именем, которое может быть значимым в приложении для типов задач, выполняемых пулом.
Префикс имени потока можно задать через аргумент "thread_name_prefix" при построении пула потоков.
В примере ниже задан префикс "TaskPool", который добавляется к имени каждого потока, созданного в пуле.
# SuperFastPython.com
# set a custom thread name prefix for all threads in the pool
import threading
from concurrent.futures import ThreadPoolExecutor
# a mock task that does nothing
def task(name):
pass
# create a thread pool with a custom name prefix
executor = ThreadPoolExecutor(thread_name_prefix='TaskPool')
# execute asks
executor.map(task, range(10))
# report all thread names
for thread in threading.enumerate():
print(thread.name)
# shutdown the thread pool
executor.shutdown()
Запуск примера сообщает имя главного потока, как и раньше, но в данном случае имена потоков в пуле потоков с пользовательским префиксом имени потока.
MainThread
TaskPool_0
TaskPool_1
TaskPool_2
TaskPool_3
Настройте инициализатор
Рабочие потоки могут вызывать функцию до начала обработки заданий.
Это называется функцией-инициализатором и может быть указано через аргумент "инициализатор" при создании пула потоков. Если функция инициализатора принимает аргументы, они могут быть переданы через аргумент "initargs" пула потоков, который представляет собой кортеж аргументов для передачи функции инициализатора.
По умолчанию функция инициализатора отсутствует.
Мы можем выбрать функцию инициализации для рабочих потоков, если хотим, чтобы каждый поток устанавливал ресурсы, специфичные для него.
В качестве примера можно привести специфичный для потока файл журнала или специфичное для потока соединение с удаленным ресурсом, например сервером или базой данных. В этом случае ресурс будет доступен для всех задач, выполняемых потоком, а не будет создаваться и отбрасываться или открываться и закрываться для каждой задачи.
Затем эти специфические для потока ресурсы могут быть сохранены где-нибудь, куда рабочий поток может ссылаться, например в глобальной переменной или в локальной переменной потока. Необходимо позаботиться о том, чтобы правильно закрыть эти ресурсы после завершения работы с пулом потоков.
В приведенном ниже примере будет создан пул потоков с двумя потоками и использована пользовательская функция инициализации. В данном случае функция не делает ничего, кроме печати имени рабочего потока. Затем мы выполняем десять задач с помощью пула потоков.
# SuperFastPython.com
# example of a custom worker thread initialization function
from time import sleep
from random import random
from threading import current_thread
from concurrent.futures import ThreadPoolExecutor
# function for initializing the worker thread
def initializer_worker():
# get the unique name for this thread
name = current_thread().name
# store the unique worker name in a thread local variable
print(f'Initializing worker thread {name}')
# a mock task that sleeps for a random amount of time less than one second
def task(identifier):
sleep(random())
# get the unique name
return identifier
# create a thread pool
with ThreadPoolExecutor(max_workers=2, initializer=initializer_worker) as executor:
# execute asks
for result in executor.map(task, range(10)):
print(result)
Выполнив пример, мы видим, что два потока инициализируются перед запуском любых задач, а затем все десять задач успешно завершаются.
Initializing worker thread ThreadPoolExecutor-0_0
Initializing worker thread ThreadPoolExecutor-0_1
0
1
2
3
4
5
6
7
8
9
Теперь, когда мы знаем, как настраивать пулы потоков, давайте узнаем больше о том, как проверять и управлять задачами с помощью объектов Future.
Как использовать объекты будущего в деталях
Future объекты создаются, когда мы вызываем submit() для отправки задач в ThreadPoolExecutor для асинхронного выполнения.
Future предоставляют возможность проверять состояние задачи (например, запущена ли она?) и управлять ее выполнением (например, отменять).
В этом разделе мы рассмотрим несколько примеров проверки и манипулирования объектами Future, созданными нашим пулом потоков.
В частности, мы рассмотрим следующее:
- Как проверить состояние фьючерсов
- Как получить результаты от фьючерсов
- Как отменить фьючерсы
- Как добавить обратный вызов в фьючерсы
- Как получить исключения из фьючерсов
Сначала давайте подробнее рассмотрим жизненный цикл будущего объекта.
Жизненный цикл будущего объекта
Объект Future создается при вызове submit() для задачи на ThreadPoolExecutor.
Во время выполнения задачи объект Future имеет статус "running".
Когда задача завершается, она имеет статус "done", и если целевая функция возвращает значение, его можно извлечь.
Перед выполнением задачи она будет вставлена в очередь задач, которую возьмет рабочий поток и начнет выполнять. В этом состоянии "pre-run" задача может быть отменена и имеет состояние "cancelled". Задача в состоянии "running" не может быть отменена.
Задача "отмененная" всегда также находится в состоянии "выполненная".
Во время выполнения задачи может возникнуть не пойманное исключение, что приведет к остановке ее выполнения. Исключение будет сохранено и может быть извлечено напрямую или будет повторно поднято при попытке извлечения результата.
На рисунке ниже представлен жизненный цикл объекта Future.
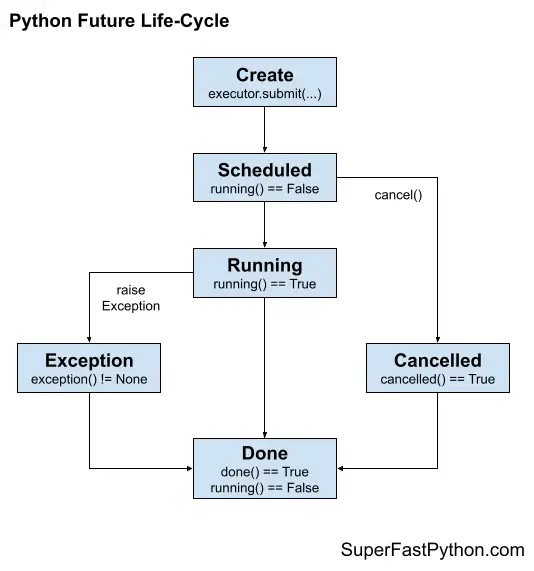
Теперь, когда мы знакомы с жизненным циклом объекта Future, давайте рассмотрим, как мы можем использовать его для проверки и манипулирования им.
Как проверить состояние фьючерсов
Существует два типа нормального состояния объекта Future, которые мы можем захотеть проверить: запущен и выполнен.
У каждого есть своя функция, которая возвращает True, если объект Future находится в этом состоянии, или False в противном случае; например:
- running(): Возвращает True, если задача в данный момент запущена.
- done(): Возвращает True, если задача завершилась или была отменена.
Мы можем разработать простые примеры, демонстрирующие, как проверить состояние объекта Future.
В этом примере мы можем запустить задачу, затем проверить, что она запущена и не выполнена, дождаться ее завершения, затем проверить, что она выполнена и не запущена.
# SuperFastPython.com
# check the status of a Future object for task executed by a thread pool
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# mock task that will sleep for a moment
def work():
sleep(0.5)
# create a thread pool
with ThreadPoolExecutor() as executor:
# start one thread
future = executor.submit(work)
# confirm that the task is running
running = future.running()
done = future.done()
print(f'Future running={running}, done={done}')
# wait for the task to complete
wait([future])
# confirm that the task is done
running = future.running()
done = future.done()
print(f'Future running={running}, done={done}')
Выполнив пример, мы видим, что сразу после отправки задания оно помечается как выполняющееся, а после его завершения мы можем подтвердить, что оно выполнено.
Future running=True, done=False
Future running=False, done=True
Как получить результаты от фьючерсов
Когда задача завершена, мы можем получить результат выполнения задачи, вызвав функцию result() на Future.
Это возвращает результат из функции возврата задачи, которую мы выполнили, или None, если функция не вернула значение.
Функция будет блокироваться до тех пор, пока задание не завершится и не будет получен результат. Если задача уже выполнена, она вернет результат немедленно.
В примере ниже показано, как получить результат из объекта Future.
# SuperFastPython.com
# get the result from a completed future task
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# mock task that will sleep for a moment
def work():
sleep(1)
return "all done"
# create a thread pool
with ThreadPoolExecutor() as executor:
# start one thread
future = executor.submit(work)
# get the result from the task, wait for task to complete
result = future.result()
print(f'Got Result: {result}')
Запуск примера отправляет задание, затем пытается получить результат, блокируя его до тех пор, пока результат не будет доступен, затем сообщает о полученном результате.
Got Result: all done
Мы также можем задать таймаут, сколько времени мы хотим ждать результата в секундах.
Если тайм-аут истекает до получения результата, возникает ошибка TimeoutError.
В примере ниже демонстрируется таймаут, показывающий, как отказаться от ожидания до завершения задачи.
# SuperFastPython.com
# set a timeout when getting results from a future
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import TimeoutError
# mock task that will sleep for a moment
def work():
sleep(1)
return "all done"
# create a thread pool
with ThreadPoolExecutor() as executor:
# start one thread
future = executor.submit(work)
# get the result from the task, wait for task to complete
try:
result = future.result(timeout=0.5)
print(f'Got Result: {result}')
except TimeoutError:
print('Gave up waiting for a result')
Выполнение примера показывает, что мы отказались от ожидания результата через полсекунды.
Gave up waiting for a result
Как отменить фьючерсы
Мы также можем отменить задачу, которая еще не начала выполняться.
Напомните, что когда мы помещаем задачи в пул с помощью submit() или map() , то задачи добавляются во внутреннюю очередь работы, из которой рабочие потоки могут извлекать задачи и выполнять их.
Пока задача находится в очереди и еще не запущена, мы можем отменить ее, вызвав cancel() на объекте Future, связанном с этой задачей. Функция cancel() вернет True, если задача была отменена, False в противном случае.
Давайте продемонстрируем это на рабочем примере.
Мы можем создать пул потоков с одним потоком, затем запустить долго выполняющуюся задачу, затем отправить вторую задачу, запросить ее отмену, а затем подтвердить, что она действительно была отменена.
# SuperFastPython.com
# example of cancelling a task via it's future
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# mock task that will sleep for a moment
def work(sleep_time):
sleep(sleep_time)
# create a thread pool
with ThreadPoolExecutor(1) as executor:
# start a long running task
future1 = executor.submit(work, 2)
running = future1.running()
print(f'First task running={running}')
# start a second
future2 = executor.submit(work, 0.1)
running = future2.running()
print(f'Second task running={running}')
# cancel the second task
was_cancelled = future2.cancel()
print(f'Second task was cancelled: {was_cancelled}')
# wait for the second task to finish, just in case
wait([future2])
# confirm it was cancelled
running = future2.running()
cancelled = future2.cancelled()
done = future2.done()
print(f'Second task running={running}, cancelled={cancelled}, done={done}')
# wait for the long running task to finish
wait([future1])
Запустив пример, мы видим, что первая задача запущена и работает нормально.
Вторая задача запланирована, но еще не запущена, потому что пул потоков занят первой задачей. Затем мы отменяем вторую задачу и подтверждаем, что она действительно не запущена; она была отменена и выполнена.
First task running=True
Second task running=False
Second task was cancelled: True
Second task running=False, cancelled=True, done=True
Отмена запущенного будущего
Теперь попробуем отменить задачу, которая уже завершила выполнение.
# SuperFastPython.com
# example of trying to cancel a running task via its future
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# mock task that will sleep for a moment
def work(sleep_time):
sleep(sleep_time)
# create a thread pool
with ThreadPoolExecutor(1) as executor:
# start a long running task
future = executor.submit(work, 2)
running = future.running()
print(f'Task running={running}')
# try to cancel the task
was_cancelled = future.cancel()
print(f'Task was cancelled: {was_cancelled}')
# wait for the task to finish
wait([future])
# check if it was cancelled
running = future.running()
cancelled = future.cancelled()
done = future.done()
print(f'Task running={running}, cancelled={cancelled}, done={done}')
Запустив пример, мы видим, что задача была запущена как обычно.
Затем мы попытались отменить задание, но, как мы и ожидали, это не удалось, поскольку задание уже было запущено.
Затем мы ждем завершения задания и проверяем его статус. Мы видим, что задача больше не выполняется и не была отменена, как мы ожидали, а помечена как невыполненная.
Это удивительно, потому что задание было выполнено успешно. Скорее всего, это указывает на ситуацию, когда запрос на отмену был получен, но не был принят во внимание.
Task running=True
Task was cancelled: False
Task running=False, cancelled=False, done=True
Отмена выполненного фьючера
Подумайте, что произойдет, если мы попытаемся отменить задание, которое уже выполнено.
Мы можем ожидать, что отмена уже выполненного задания не будет иметь никакого эффекта, и так оно и есть.
Это можно продемонстрировать на небольшом примере.
Мы запускаем и выполняем задачу, как обычно, затем ждем ее завершения и сообщаем о ее состоянии. Затем мы пытаемся отменить задачу.
# SuperFastPython.com
# example of trying to cancel a done task via its future
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# mock task that will sleep for a moment
def work(sleep_time):
sleep(sleep_time)
# create a thread pool
with ThreadPoolExecutor(1) as executor:
# start a long running task
future = executor.submit(work, 2)
running = future.running()
# wait for the task to finish
wait([future])
# check the status
running = future.running()
cancelled = future.cancelled()
done = future.done()
print(f'Task running={running}, cancelled={cancelled}, done={done}')
# try to cancel the task
was_cancelled = future.cancel()
print(f'Task was cancelled: {was_cancelled}')
# check if it was cancelled
running = future.running()
cancelled = future.cancelled()
done = future.done()
print(f'Task running={running}, cancelled={cancelled}, done={done}')
Запуск примера подтверждает, что задача выполняется и помечается как выполненная, как обычно.
Попытка отменить задание не удалась, и проверка статуса после попытки отмены подтверждает, что задание не было затронуто этой попыткой.
Task running=False, cancelled=False, done=True
Task was cancelled: False
Task running=False, cancelled=False, done=True
Как добавить обратный вызов к фьючерсам
Выше мы уже видели, как добавить обратный вызов в Future. Тем не менее, для полноты картины рассмотрим еще несколько примеров, включая некоторые крайние случаи.
Мы можем зарегистрировать одну или несколько функций обратного вызова на объекте Future, вызвав функцию add_done_callback() и указав имя функции для вызова.
Функции обратного вызова будут вызваны с объектом Future в качестве аргумента сразу после завершения задачи. Если зарегистрировано более одной функции обратного вызова, то они будут вызываться в порядке их регистрации, а любые исключения в каждой функции обратного вызова будут перехвачены, зарегистрированы и проигнорированы.
Обратный вызов будет вызван рабочим потоком, который выполнил задание.
В примере ниже показано, как добавить функцию обратного вызова к объекту Future.
# SuperFastPython.com
# add a callback option to a future object
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# callback function to call when a task is completed
def custom_callback(future):
print('Custom callback was called')
# mock task that will sleep for a moment
def work():
sleep(1)
print('Task is done')
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute the task
future = executor.submit(work)
# add the custom callback
future.add_done_callback(custom_callback)
# wait for the task to complete
wait([future])
Запустив пример, мы видим, что сначала выполняется задача, а затем, как мы и ожидали, обратный вызов.
Task is done
Custom callback was called
Общая ошибка при использовании будущих обратных вызовов
Частая ошибка - забыть добавить объект Future в качестве аргумента в пользовательский обратный вызов.
Например:
# callback function to call when a task is completed
def custom_callback():
print('Custom callback was called')
Если вы зарегистрируете эту функцию и попытаетесь выполнить код, то получите TypeError в следующем виде:
Task is done
exception calling callback for <Future at 0x104482b20 state=finished returned NoneType>
...
TypeError: custom_callback() takes 0 positional arguments but 1 was given
Сообщение в TypeError дает понять, как исправить проблему: добавьте единственный аргумент в функцию для будущего объекта, даже если вы не собираетесь использовать его в обратном вызове.
Выполнение обратных вызовов при отмене фьючера
Мы также можем увидеть эффект обратных вызовов на объектах Future для задач, которые отменяются.
Этот эффект не документирован в API, но мы могли бы ожидать, что обратный вызов будет выполняться всегда, независимо от того, выполняется ли задача нормально или отменяется. Так и происходит.
Нижеприведенный пример демонстрирует это.
Сначала создается пул потоков с одним потоком. Выпускается долго выполняющаяся задача, которая занимает весь пул, затем мы посылаем вторую задачу, добавляем обратный вызов ко второй задаче, отменяем ее и ждем, пока все задачи завершатся.
# SuperFastPython.com
# example of a callback for a cancelled task via the future object
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# callback function to call when a task is completed
def custom_callback(future):
print('Custom callback was called')
# mock task that will sleep for a moment
def work(sleep_time):
sleep(sleep_time)
# create a thread pool
with ThreadPoolExecutor(1) as executor:
# start a long running task
future1 = executor.submit(work, 2)
running = future1.running()
print(f'First task running={running}')
# start a second
future2 = executor.submit(work, 0.1)
running = future2.running()
print(f'Second task running={running}')
# add the custom callback
future2.add_done_callback(custom_callback)
# cancel the second task
was_cancelled = future2.cancel()
print(f'Second task was cancelled: {was_cancelled}')
# explicitly wait for all tasks to complete
wait([future1, future2])
Запустив пример, мы видим, что первая задача запускается, как мы и ожидали.
Вторая задача запланирована, но не успевает выполниться до того, как мы ее отменим. Обратный вызов выполняется сразу после отмены задачи, затем мы сообщаем в главном потоке, что задача действительно была отменена правильно.
First task running=True
Second task running=False
Custom callback was called
Second task was cancelled: True
Как получить исключения из фьючерсов
Задача может вызвать исключение во время выполнения.
Если мы можем предвидеть исключение, мы можем обернуть часть нашей функции задачи в блок try-except и обработать исключение внутри задачи.
Если в нашей задаче возникнет неожиданное исключение, задача прекратит выполнение.
Мы не можем узнать по статусу задачи, было ли поднято исключение, но мы можем проверить наличие исключения напрямую.
Затем мы можем получить доступ к исключению с помощью функции exception(). В качестве альтернативы исключение будет повторно поднято при вызове функции result() при попытке получить результат.
Мы можем продемонстрировать это на примере.
В приведенном ниже примере внутри задачи будет вызвана ошибка ValueError, которая не будет поймана, а вместо этого будет поймана пулом потоков, чтобы мы могли получить к ней доступ позже.
# SuperFastPython.com
# example of handling an exception raised within a task
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# mock task that will sleep for a moment
def work():
sleep(1)
raise Exception('This is Fake!')
return "never gets here"
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute our task
future = executor.submit(work)
# wait for the task to complete
wait([future])
# check the status of the task after it has completed
running = future.running()
cancelled = future.cancelled()
done = future.done()
print(f'Task running={running}, cancelled={cancelled}, done={done}')
# get the exception
exception = future.exception()
print(f'Exception={exception}')
# get the result from the task
try:
result = future.result()
except Exception:
print('Unable to get the result')
Запуск примера запускает задачу в обычном режиме, которая спит в течение одной секунды.
Затем задача вызывает исключение, которое перехватывается пулом потоков. Пул потоков сохраняет исключение, и задача завершается.
Мы видим, что после завершения задачи она помечается как не запущенная, не отмененная и выполненная.
Затем мы получаем доступ к исключению из задачи, которое соответствует исключению, которое мы намеренно поднимаем.
Попытка получить доступ к результату через функцию result() не удается, и мы ловим то же исключение, что и в задаче.
Task running=False, cancelled=False, done=True
Exception=This is Fake!
Unable to get the result
Обратные вызовы все еще вызываются, если задача поднимает исключение
Нам может быть интересно, если мы зарегистрируем функцию обратного вызова в Future, будет ли она по-прежнему выполняться, если задача вызовет исключение.
Как и следовало ожидать, обратный вызов будет выполнен, даже если задача вызовет исключение.
Мы можем проверить это, обновив предыдущий пример, чтобы зарегистрировать функцию обратного вызова до того, как задача завершится с исключением.
# SuperFastPython.com
# example of handling an exception raised within a task that has a callback
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# callback function to call when a task is completed
def custom_callback(future):
print('Custom callback was called')
# mock task that will sleep for a moment
def work():
sleep(1)
raise Exception('This is Fake!')
return "never gets here"
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute our task
future = executor.submit(work)
# add the custom callback
future.add_done_callback(custom_callback)
# wait for the task to complete
wait([future])
# check the status of the task after it has completed
running = future.running()
cancelled = future.cancelled()
done = future.done()
print(f'Task running={running}, cancelled={cancelled}, done={done}')
# get the exception
exception = future.exception()
print(f'Exception={exception}')
# get the result from the task
try:
result = future.result()
except Exception:
print('Unable to get the result')
Запуск примера запускает задачу, как и раньше, но на этот раз регистрирует функцию обратного вызова.
Когда задача завершается с исключением, обратный вызов вызывается немедленно. Затем главный поток сообщает о статусе неудавшейся задачи и деталях исключения.
Custom callback was called
Task running=False, cancelled=False, done=True
Exception=This is Fake!
Unable to get the result
Когда использовать ThreadPoolExecutor
Программа ThreadPoolExecutor является мощной и гибкой, хотя она не подходит для всех ситуаций, когда вам нужно запустить фоновую задачу.
В этом разделе мы рассмотрим некоторые общие случаи, когда он хорошо подходит, а когда нет, затем мы рассмотрим широкие классы задач и почему они подходят или не подходят для ThreadPoolExecutor.
Использовать ThreadPoolExecutor, когда...
- Ваши задачи могут быть определены чистой функцией, не имеющей состояния или побочных эффектов.
- Ваша задача может уместиться в одной функции Python, что делает ее простой и понятной.
- Вам нужно выполнять одну и ту же задачу много раз, например, однородные задачи.
- Вам нужно применить одну и ту же функцию к каждому объекту коллекции в цикле for.
Пулы потоков лучше всего работают при применении одной и той же чистой функции к набору различных данных (например, однородные задачи, разнородные данные). Это облегчает чтение и отладку кода. Это не правило, а просто мягкое предложение.
Использовать несколько ThreadPoolExecutor, когда...
- Вам необходимо выполнять группы различных типов задач; для каждого типа задач можно использовать один пул потоков.
- Вам необходимо выполнить конвейер задач или операций; один пул потоков может быть использован для каждого шага.
Пулы потоков могут работать с задачами разных типов (например, с разнородными задачами), хотя это может облегчить организацию вашей программы и отладку, если за каждый тип задачи будет отвечать отдельный пул потоков. Это не правило, а просто мягкое предложение.
Не используйте ThreadPoolExecutor, если...
- У вас одна задача; рассмотрите возможность использования класса Thread с аргументом target.
- У вас есть задачи с длительным периодом выполнения, такие как мониторинг или планирование; рассмотрите возможность расширения класса Thread.
- Ваши функции задач требуют состояния; рассмотрите возможность расширения класса Thread.
- Ваши задачи требуют координации; рассмотрите возможность использования Thread и паттернов, таких как Barrier или Semaphore.
- Ваши задачи требуют синхронизации; рассмотрите возможность использования Thread и Locks.
- Вам требуется триггер потока на событие; рассмотрите возможность использования класса Thread.
"Сладкое место" для пулов потоков - это диспетчеризация множества одинаковых задач, результаты которых могут быть использованы позже в программе. Задачи, которые не вписываются в это обобщение, вероятно, не подходят для пулов потоков. Это не правило, а просто мягкое предложение.
Знаете ли вы другие хорошие или плохие случаи использования ThreadPoolExecutor?
Дайте мне знать в комментариях ниже.
Использование потоков для задач, связанных с вводом-выводом
Вы должны использовать потоки для задач, связанных с IO.
Задача, связанная с IO, - это тип задачи, которая включает чтение с устройства, файла или сокетного соединения или запись на них.
Операции связаны с вводом и выводом (IO), и скорость этих операций зависит от устройства, жесткого диска или сетевого подключения. Поэтому такие задачи называются IO-bound.
Процессоры действительно быстрые. Современные процессоры, например 4 ГГц, могут выполнять 4 миллиарда инструкций в секунду, и, скорее всего, в вашей системе более одного процессора.
Выполнение операций ввода-вывода очень медленно по сравнению со скоростью процессоров.
Взаимодействие с устройствами, чтение и запись файлов и сокетные соединения предполагают вызов инструкций в вашей операционной системе (ядре), которая будет ждать завершения операции. Если эта операция является основной для вашего процессора, например, выполняется в главном потоке вашей программы Python, то ваш процессор будет ждать много миллисекунд или даже много секунд, ничего не делая.
Это потенциально миллиарды операций, которые не могут быть выполнены.
Мы можем освободить процессор от операций, связанных с IO, выполняя операции, связанные с IO, в другом потоке выполнения. Это позволяет процессору запустить процесс и передать его операционной системе (ядру) для выполнения ожидания, а самому освободиться для выполнения в другом потоке приложения.
Под обложкой есть еще кое-что, но суть такова.
Поэтому задачи, которые мы выполняем с помощью ThreadPoolExecutor, должны быть задачами, включающими операции ввода-вывода.
Примеры включают:
- Чтение или запись файла с жесткого диска.
- Чтение или запись в стандартный вывод, ввод или ошибку (stdin, stdout, stderr).
- Печать документа.
- Загрузка или выгрузка файла.
- Запрос к серверу.
- Запрос к базе данных.
- Съемка фото или запись видео.
- И многое другое.
Если ваша задача не связана с IO, возможно, потоки и использование пула потоков не подходят.
Не используйте потоки для задач, связанных с процессором
Вы, вероятно, не должны использовать потоки для задач, связанных с процессором.
Задача с привязкой к процессору - это тип задачи, которая предполагает выполнение вычислений и не связана с вводом-выводом данных.
Операции связаны только с данными в оперативной памяти (RAM) или кэше (CPU cache) и выполнением вычислений над этими данными или с ними. Ограничением для этих операций является скорость центрального процессора. Поэтому мы называем их задачами, привязанными к процессору.
Примеры включают:
- Вычисление точек фрактала.
- Вычисление числа Пи
- Вычисление простых чисел.
- Разбор HTML, JSON и др. документов.
- Обработка текста.
- Запуск симуляций.
Процессоры очень быстрые, и у нас часто бывает более одного процессора. Мы хотели бы выполнять наши задачи, полностью используя несколько ядер процессора в современном оборудовании.
Использование потоков и пулов потоков через класс ThreadPoolExecutor в Python, вероятно, не является способом достижения этой цели.
Это объясняется техническими причинами, связанными с тем, как был реализован интерпретатор Python. Реализация предотвращает одновременное выполнение двух операций Python внутри интерпретатора и делает это с помощью главной блокировки, которую может одновременно держать только один поток. Она называется глобальной блокировкой интерпретатора, или GIL.
GIL не является злом и не вызывает разочарования; это дизайнерское решение в интерпретаторе python, которое мы должны знать и учитывать при разработке наших приложений.
Я сказал, что вы " вероятно" не должны использовать потоки для задач, привязанных к процессору.
Вы можете и вольны так поступить, но ваш код не получит преимущества параллелизма из-за GIL. Скорее всего, он будет работать хуже из-за дополнительных накладных расходов на переключение контекста (переход процессора от одного потока выполнения к другому), вызванных использованием потоков.
Кроме того, GIL - это проектное решение, которое влияет на эталонную реализацию Python, которую вы загружаете с сайта Python.org. Если вы используете другую реализацию интерпретатора Python (например, PyPy, IronPython, Jython и, возможно, другие), то на вас не распространяется действие GIL и вы можете использовать потоки для задач, связанных с процессором, напрямую.
Python предоставляет модуль multiprocessing для выполнения многоядерных задач, а также родной брат ThreadPoolExecutor, использующий процессы, называемый ProcessPoolExecutor, который можно использовать для параллелизма задач, связанных с процессором.
Обработка исключений ThreadPoolExecutor
Обработка исключений является важным моментом при использовании потоков.
Код будет поднимать исключение, когда происходит что-то неожиданное, и это исключение должно быть обработано вашим приложением в явном виде, даже если это означает запись его в журнал и дальнейшие действия.
Потоки Python хорошо подходят для использования с задачами, связанными с вводом-выводом, а операции внутри этих задач часто вызывают исключения, например, если сервер не может быть достигнут, если сеть падает, если файл не может быть найден и так далее.
При использовании ThreadPoolExecutor вам может понадобиться рассмотреть три момента обработки исключений, а именно:
- Обработка исключений при инициализации потока
- Обработка исключений во время выполнения задачи
- Обработка исключений во время обратных вызовов завершения задачи
Давайте рассмотрим каждый пункт по очереди.
Обработка исключений при инициализации потоков
Вы можете указать пользовательскую функцию инициализации при настройке вашего ThreadPoolExecutor.
Это можно задать с помощью аргумента "initializer" для указания имени функции и "initargs" для указания кортежа аргументов функции.
Каждый поток, запущенный пулом потоков, будет вызывать вашу функцию инициализации перед запуском потока.
Если ваша функция инициализации вызовет исключение, это приведет к разрушению пула потоков.
Все текущие задачи и любые будущие задачи, выполняемые пулом потоков, не будут запущены и вызовут исключение BrokenThreadPool.
Мы можем продемонстрировать это на примере надуманной функции инициализатора, которая вызывает исключение.
# SuperFastPython.com
# example of an exception in a thread pool initializer function
from time import sleep
from random import random
from threading import current_thread
from concurrent.futures import ThreadPoolExecutor
# function for initializing the worker thread
def initializer_worker():
# raise an exception
raise Exception('Something bad happened!')
# a mock task that sleeps for a random amount of time less than one second
def task(identifier):
sleep(random())
# get the unique name
return identifier
# create a thread pool
with ThreadPoolExecutor(max_workers=2, initializer=initializer_worker) as executor:
# execute tasks
for result in executor.map(task, range(10)):
print(result)
Запуск примера завершился с исключением, как мы и ожидали.
Пул потоков создается как обычно, но как только мы пытаемся выполнить задания, создаются новые рабочие потоки, вызывается пользовательская функция инициализации рабочих потоков и возникает исключение.
Множество потоков пытались запуститься, и, в свою очередь, несколько потоков потерпели неудачу с Исключением. Наконец, сам пул потоков выдал сообщение о том, что пул сломан и больше не может быть использован.
Exception in initializer:
Traceback (most recent call last):
...
raise Exception('Something bad happened!')
Exception: Something bad happened!
Exception in initializer:
Traceback (most recent call last):
...
raise Exception('Something bad happened!')
Exception: Something bad happened!
Traceback (most recent call last):
...
concurrent.futures.thread.BrokenThreadPool: A thread initializer failed, the thread pool is not usable anymore
Это подчеркивает, что если вы используете пользовательскую функцию инициализатора, вы должны тщательно продумать исключения, которые могут быть вызваны, и, возможно, обработать их, иначе рискуете всеми задачами, которые зависят от пула потоков.
Обработка исключений во время выполнения задачи
При выполнении вашего задания может возникнуть исключение.
Это приведет к прекращению выполнения задачи, но не нарушит пул потоков. Вместо этого исключение будет поймано пулом потоков и станет доступно через объект Future, связанный с задачей, посредством функции exception().
Альтернативно, исключение будет повторно поднято, если вы вызовете result() в Future, чтобы получить результат. Это повлияет на вызовы submit() и map() при добавлении задач в пул потоков.
Это означает, что у вас есть два варианта обработки исключений в задачах; они следующие:
- 1. Обработка исключений внутри функции задачи.
- 2. Обработка исключений при получении результатов из задач.
Обработка исключения внутри задачи
Обработка исключения внутри задачи означает, что вам нужен какой-то механизм, чтобы сообщить получателю результата о том, что произошло что-то неожиданное.
Это может быть через возвращаемое значение из функции, например None.
В качестве альтернативы можно повторно поднять исключение и попросить получателя обработать его напрямую. Третьим вариантом может быть использование некоторого более широкого состояния или глобального состояния, возможно, передаваемого по ссылке в вызове функции.
В приведенном ниже примере определена рабочая задача, которая будет вызывать исключение, но будет его перехватывать и возвращать результат, указывающий на случай неудачи.
# SuperFastPython.com
# example of handling an exception raise within a task
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# mock task that will sleep for a moment
def work():
sleep(1)
try:
raise Exception('Something bad happened!')
except Exception:
return 'Unable to get the result'
return "never gets here"
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute our task
future = executor.submit(work)
# get the result from the task
result = future.result()
print(result)
Запуск примера запускает пул потоков как обычно, выдает задание, затем блокирует ожидание результата.
Задача вызывает исключение, и результатом является сообщение об ошибке.
Такой подход достаточно чист для кода-получателя и подойдет для задач, выдаваемых как submit(), так и map(). Возможно, потребуется специальная обработка пользовательского возвращаемого значения для случая отказа.
Unable to get the result
Обработка исключения получателем результата задачи
Альтернативой обработке исключения в задаче является возложение ответственности на получателя результата.
Это может показаться более естественным решением, поскольку оно соответствует синхронной версии той же операции, например, если бы мы выполняли вызов функции в for-цикле.
Это означает, что получатель должен знать о типах ошибок, которые может вызвать задача, и явно их обрабатывать.
В примере ниже определена простая задача, которая вызывает Exception, который затем обрабатывается получателем при попытке получить результат от вызова функции.
# SuperFastPython.com
# example of handling an exception raised within a task
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# mock task that will sleep for a moment
def work():
sleep(1)
raise Exception('Something bad happened!')
return "never gets here"
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute our task
future = executor.submit(work)
# get the result from the task
try:
result = future.result()
except Exception:
print('Unable to get the result')
Запуск примера создает пул потоков и отправляет работу в обычном режиме. Задача завершается с ошибкой, пул потоков перехватывает исключение, сохраняет его, а затем снова поднимает, когда мы вызываем функцию result() в Future.
Получатель результата принимает исключение и перехватывает его, сообщая о случае отказа.
Unable to get the result
Мы также можем проверить наличие исключения напрямую с помощью вызова функции exception() на объекте Future. Эта функция блокирует выполнение исключения и берет таймаут, как и вызов result().
Если исключение никогда не возникает и задача отменяется или завершается успешно, то exception() вернет значение None.
Мы можем продемонстрировать явную проверку исключительного случая в задаче в примере ниже.
# SuperFastPython.com
# example of handling an exception raised within a task
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# mock task that will sleep for a moment
def work():
sleep(1)
raise Exception('Something bad happened!')
return "never gets here"
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute our task
future = executor.submit(work)
# get the result from the task
exception = future.exception()
# handle exceptional case
if exception:
print(exception)
else:
result = future.result()
print(result)
Запуск примера создает и отправляет работу в обычном режиме.
Получатель проверяет наличие исключительного случая, который блокируется до тех пор, пока не возникнет исключение или задача не будет выполнена. Исключение получено и обрабатывается путем сообщения о нем.
Something bad happened!
Мы не можем проверить функцию exception() объекта Future для каждой задачи, так как map() не предоставляет доступ к объектам Future.
Еще хуже то, что подход к обработке исключения в получателе нельзя использовать при использовании map() для отправки задач, если только вы не обернете всю итерацию.
Мы можем продемонстрировать это, представив одну задачу с помощью map(), которая случайно поднимает исключение.
Полный пример приведен ниже.
# SuperFastPython.com
# example of handling an exception raised within a task
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# mock task that will sleep for a moment
def work(value):
sleep(1)
raise Exception('Something bad happened!')
return f'Never gets here {value}'
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute our task
for result in executor.map(work, [1]):
print(result)
Запуск примера приводит к отправке единственной задачи (плохое использование map()) и ожиданию первого результата.
Задача вызывает исключение, и главный поток завершается, как мы и ожидали.
Traceback (most recent call last):
...
raise Exception('Something bad happened!')
Exception: Something bad happened!
Это подчеркивает, что если map() используется для отправки задач в пул потоков, то задачи должны обрабатывать собственные исключения или быть достаточно простыми, чтобы исключения не ожидались.
Обработка исключений в обратных вызовах
Последний случай, который мы должны рассмотреть для обработки исключений при использовании ThreadPoolExecutor - это функции обратного вызова.
При выдаче заданий пулу потоков вызовом submit() мы получаем в ответ объект Future, на котором можно зарегистрировать функции обратного вызова для вызова при завершении задачи с помощью функции add_done_callback().
Это позволяет зарегистрировать одну или несколько функций обратного вызова, которые будут выполняться в том порядке, в котором они зарегистрированы.
Эти обратные вызовы вызываются всегда, даже если задача отменена или завершилась с исключением.
Обратный вызов может завершиться с исключением, и это не повлияет на другие зарегистрированные функции обратного вызова или задачу.
Исключение перехватывается пулом потоков, регистрируется в виде сообщения типа exception, и процедура переходит к выполнению. В некотором смысле, обратные вызовы могут быть бесшумными.
Мы можем продемонстрировать это на примере с несколькими функциями обратного вызова, первая из которых вызовет исключение.
# SuperFastPython.com
# add callbacks to a future, one of which raises an exception
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# callback function to call when a task is completed
def custom_callback1(future):
raise Exception('Something bad happened!')
# never gets here
print('Callback 1 called.')
# callback function to call when a task is completed
def custom_callback2(future):
print('Callback 2 called.')
# mock task that will sleep for a moment
def work():
sleep(1)
return 'Task is done'
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute the task
future = executor.submit(work)
# add the custom callbacks
future.add_done_callback(custom_callback1)
future.add_done_callback(custom_callback2)
# wait for the task to complete and get the result
result = future.result()
# wait for callbacks to finish
sleep(0.1)
print(result)
Запуск примера запускает пул потоков в обычном режиме и выполняет задачу.
После завершения задачи вызывается первый обратный вызов, который завершается с исключением. Исключение записывается в журнал и выводится на консоль (поведение по умолчанию для протоколирования).
Пул потоков не нарушен и продолжает работать.
Второй обратный вызов выполняется успешно, и, наконец, главный поток получает результат выполнения задачи.
exception calling callback for <Future at 0x101d76730 state=finished returned str>
Traceback (most recent call last):
...
raise Exception('Something bad happened!')
Exception: Something bad happened!
Callback 2 called.
Task is done
Это подчеркивает, что если ожидается, что обратный вызов вызовет исключение, то оно должно быть обработано явно и проверено, если вы хотите, чтобы сбой повлиял на саму задачу.
Как работает ThreadPoolExecutor внутри
Важно сделать небольшую паузу и посмотреть на то, как ThreadPoolExecutor работает внутри .
Внутренняя работа класса влияет на то, как мы используем пул потоков и на поведение, которого мы можем ожидать, в частности, на отмену задач.
Без этих знаний некоторые действия пула потоков могут показаться непонятными со стороны.
Исходный код ThreadPoolExecutor и базового класса можно посмотреть здесь:
Многое можно было бы узнать о том, как работает пул потоков изнутри, но мы ограничимся самыми важными аспектами.
Внутренняя работа класса ThreadPoolExecutor включает в себя два аспекта: как задания отправляются в пул и как создаются рабочие потоки.
Задачи добавляются во внутреннюю очередь
Задачи отправляются в пул потоков путем добавления их во внутреннюю очередь.
Напомните, что очередь - это структура данных, в которой элементы добавляются в один конец и извлекаются из другого в порядке поступления и выбытия (FIFO) по умолчанию.
Очередь представляет собой SimpleQueue объект, который является потокобезопасной Queue реализацией. Это означает, что мы можем добавлять работы в пул из любого потока и Queue работы не будут повреждены в результате одновременных put() и get() операций.
Использование очереди задач объясняет различие между задачами, которые были добавлены или запланированы, но еще не запущены, и что эти задачи могут быть отменены.
Напомните, что пул потоков имеет фиксированное количество рабочих потоков. Количество задач в очереди может превышать текущее количество потоков или текущее количество доступных потоков. В этом случае задачи могут некоторое время находиться в запланированном состоянии, что позволит отменить их либо напрямую, либо массово при завершении работы пула.
Задача обернута во внутренний объект, называемый _WorkItem. В нем фиксируются такие детали, как функция для вызова, аргументы, связанный объект Future и обработка исключений, если они возникают во время выполнения задачи.
Это объясняет, как исключение в задаче не приводит к остановке всего пула потоков, а может быть проверено и доступно после завершения задачи.
Когда рабочий поток извлекает объект _WorkItem из очереди, он проверяет, не было ли задание отменено перед его выполнением. Если да, то он немедленно вернется и не будет выполнять содержимое задачи.
Это объясняет, как пул потоков реализует отмену и почему мы не можем отменить запущенную задачу.
Рабочие потоки создаются по мере необходимости
Рабочие потоки не создаются при создании пула потоков.
Вместо этого рабочие потоки создаются по требованию или точно в срок.
Каждый раз, когда задача добавляется во внутреннюю очередь, пул потоков проверяет, не меньше ли количество активных потоков, чем верхний предел потоков, поддерживаемых пулом потоков. Если да, то создается дополнительный поток для обработки новой работы.
После того как поток выполнит задание, он будет ждать в очереди поступления новых работ. По мере поступления новой работы все потоки, ожидающие в очереди, будут оповещены, и один из них возьмет единицу работы и начнет ее выполнять.
Эти две точки показывают, как пул будет создавать новые потоки только до тех пор, пока не будет достигнут лимит, и как потоки будут повторно использоваться, ожидая новых задач, не расходуя вычислительные ресурсы.
Это также показывает, что пул потоков не будет освобождать потоки после фиксированного количества единиц работы. Возможно, это будет хорошим дополнением к API в будущем.
Теперь, когда мы поняли, как работа вводится в пул потоков и как пул управляет потоками, давайте рассмотрим некоторые лучшие практики, которые следует учитывать при использовании ThreadPoolExecutor.
Лучшие практики использования пула потоков (ThreadPoolExecutor)
Теперь, когда мы знаем, как работает ThreadPoolExecutor и как его использовать, давайте рассмотрим некоторые лучшие практики, которые следует учитывать при внедрении пулов потоков в наши программы на Python.
Чтобы упростить ситуацию, существует пять лучших практик; они следующие:
- 1. Используйте менеджер контекста
- 2. Используйте map() для асинхронных циклов For-Loops
- 3. Используйте submit() с as_completed()
- 4. Используйте независимые функции в качестве задач
- 5. Использовать для задач, связанных с IO (возможно)
Используйте диспетчер контекстов
Используйте менеджер контекста при использовании пулов потоков и обрабатывайте всю диспетчеризацию задач к пулу потоков и результаты обработки внутри менеджера.
Например:
# create a thread pool via the context manager
with ThreadPoolExecutor(10) as executor:
# ...
Не забудьте настроить пул потоков при его создании в менеджере контекста, в частности, задав количество потоков, которые будут использоваться в пуле.
Использование менеджера контекста позволяет избежать ситуации, когда вы явно инстанцировали пул потоков и забыли выключить его вручную, вызвав shutdown().
Кроме того, это меньше кода и лучше сгруппировано, чем управление инстанцированием и выключением вручную; например:
# create a thread pool manually
executor = ThreadPoolExecutor(10)
# ...
executor.shutdown()
Не используйте менеджер контекста, когда вам нужно отправлять задачи и получать результаты в более широком контексте (например, в нескольких функциях) и/или когда у вас есть больше контроля над выключением пула.
Используйте map() для асинхронных циклов For-Loops
Если у вас есть цикл for, который применяет функцию к каждому элементу списка, то используйте функцию map() для асинхронной диспетчеризации задач.
Например, у вас может быть цикл for по списку, который вызывает myfunc() для каждого элемента:
# apply a function to each item in an iterable
for item in mylist:
result = myfunc(item)
# do something...
Или, возможно, вы уже используете встроенную функцию map:
# apply a function to each item in an iterable
for result in map(myfinc, mylist):
# do something...
Оба этих случая можно сделать асинхронными с помощью функции map() на пуле потоков.
# apply a function to each item in a iterable asynchronously
for result in executor.map(myfunc, mylist):
# do something...
Не используйте функцию map(), если ваша целевая функция задачи имеет побочные эффекты.
Не используйте функцию map(), если ваша целевая функция задачи не имеет аргументов или имеет более одного аргумента.
Не используйте функцию map(), если вам нужен контроль над обработкой исключений для каждой задачи, или если вы хотите получать результаты для задач в порядке их выполнения.
Используйте submit() с as_completed()
Если вы хотите обрабатывать результаты в порядке выполнения заданий, а не в порядке их подачи, то используйте submit() и as_completed().
Функция submit() находится в пуле потоков и используется для передачи задач в пул для выполнения и возвращается сразу с объектом Future для задачи. Функция as_completed() - это метод модуля, который принимает итерацию объектов Future, подобно списку, и возвращает объекты Future по мере выполнения задач.
Например:
# submit all tasks and get future objects
futures = [executor.submit(myfunc, item) for item in mylist]
# process results from tasks in order of task completion
for future in as_completed(futures):
# get the result
result = future.result()
# do something...
Не используйте комбинацию submit() и as_completed(), если вам нужно обрабатывать результаты в том порядке, в котором задания были отправлены в пул потоков.
Не используйте комбинацию submit() и as_completed(), если вам нужны результаты всех задач для продолжения; возможно, вам лучше использовать функцию модуля wait().
Не используйте комбинацию submit() и as_completed() для простого асинхронного цикла for; лучше использовать map().
Использование независимых функций в качестве задач
Используйте ThreadPoolExecutor, если ваши задачи независимы.
Это означает, что каждая задача не зависит от других задач, которые могут выполняться в одно и то же время. Это также может означать, что задачи не зависят ни от каких данных, кроме тех, которые предоставляются через аргументы функции для задачи.
Исполнитель ThreadPoolExecutor идеально подходит для задач, которые не изменяют никаких данных, например, не имеют побочных эффектов, так называемых чистых функций.
Пулы потоков могут быть организованы в потоки данных и конвейеры для линейной зависимости между задачами, возможно, с одним пулом потоков на тип задачи.
Пул потоков не предназначен для задач, требующих координации; вам следует рассмотреть возможность использования класса Thread и таких шаблонов координации, как Barrier и Semaphore.
Пулы потоков не предназначены для задач, требующих синхронизации; вам следует рассмотреть возможность использования класса Thread и таких шаблонов блокировки, как Lock и RLock.
Используется для задач, связанных с IO (возможно)
Используйте ThreadPoolExecutor только для задач, связанных с IO.
Это задачи, которые могут включать в себя взаимодействие с внешним устройством, таким как периферийное устройство (например, камера или принтер), устройство хранения данных (например, запоминающее устройство или жесткий диск) или другой компьютер (например, связь через сокет).
Потоки и пулы потоков, такие как ThreadPoolExecutor, вероятно, не подходят для задач, привязанных к процессору, таких как вычисления с данными в памяти.
Это связано с конструктивными решениями в интерпретаторе Python, который использует главную блокировку, называемую Global Interpreter Lock (GIL), которая предотвращает одновременное выполнение более чем одной инструкции Python.
Это решение было принято в рамках эталонной реализации интерпретатора Python (с сайта Python.org), но может не повлиять на другие интерпретаторы (такие как PyPy, Iron Python и Jython).
Общие ошибки при использовании ThreadPoolExecutor
Существует ряд типичных ошибок при использовании ThreadPoolExecutor.
Обычно такие ошибки возникают из-за ошибок, возникающих при копировании и вставке кода, или из-за небольшого непонимания того, как работает ThreadPoolExecutor.
Мы рассмотрим некоторые из наиболее распространенных ошибок, допускаемых при использовании ThreadPoolExecutor.
У вас возникла ошибка при использовании ThreadPoolExecutor?
Дайте мне знать в комментариях, чтобы я мог порекомендовать исправление и добавить случай в этот раздел.
Использование вызова функции в submit()
Частой ошибкой является вызов вашей функции при использовании функции submit().
Например:
# submit the task
future = executor.submit(task())
Ниже приведен полный пример с этой ошибкой.
# SuperFastPython.com
# example of calling submit with a function call
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task():
# sleep for less than a second
sleep(random())
return 'all done'
# start the thread pool
with ThreadPoolExecutor() as executor:
# submit the task
future = executor.submit(task())
# get the result
result = future.result()
print(result)
Выполнение этого примера приведет к ошибке.
Traceback (most recent call last):
...
result = self.fn(*self.args, **self.kwargs)
TypeError: 'str' object is not callable
Вы можете исправить ошибку, изменив вызов submit() так, чтобы он принимал имя вашей функции и любые аргументы, вместо того чтобы вызывать функцию в вызове submit.
Например:
# submit the task
future = executor.submit(task)
Использование вызова функции в map()
Частой ошибкой является вызов своей функции при использовании функции map().
Например:
# submit all tasks
for result in executor.map(task(), range(5)):
print(result)
Ниже приведен полный пример с этой ошибкой.
# SuperFastPython.com
# example of calling map with a function call
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(value):
# sleep for less than a second
sleep(random())
return value
# start the thread pool
with ThreadPoolExecutor() as executor:
# submit all tasks
for result in executor.map(task(), range(5)):
print(result)
В результате выполнения примера возникает ошибка TypeError
Traceback (most recent call last):
...
TypeError: task() missing 1 required positional argument: 'value'
Эту ошибку можно исправить, изменив вызов map() на передачу имени функции целевой задачи вместо вызова функции.
# submit all tasks
for result in executor.map(task, range(5)):
print(result)
Неправильная сигнатура функции map()
Еще одна распространенная ошибка при использовании map() - это отсутствие второго аргумента функции, например, итерируемой переменной.
Например:
# submit all tasks
for result in executor.map(task):
print(result)
Ниже приведен полный пример с этой ошибкой.
# SuperFastPython.com
# example of calling map without an iterable
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
# custom task that will sleep for a variable amount of time
def task(value):
# sleep for less than a second
sleep(random())
return value
# start the thread pool
with ThreadPoolExecutor() as executor:
# submit all tasks
for result in executor.map(task):
print(result)
При выполнении примера пулу потоков не выдается никаких заданий, поскольку для функции map() не было итерабельных переменных.
В этом случае вывод не отображается.
Исправление заключается в предоставлении итерабельной переменной в вызове map() вместе с именем вашей функции.
# submit all tasks
for result in executor.map(task, range(5)):
print(result)
Неправильная подпись функции для будущих обратных вызовов
Еще одна распространенная ошибка - забыть включить Future в сигнатуру для функции обратного вызова, зарегистрированной с объектом Future.
Например:
# callback function to call when a task is completed
def custom_callback():
print('Custom callback was called')
Ниже приведен полный пример с этой ошибкой.
# SuperFastPython.com
# example of the wrong signature on the callback function
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# callback function to call when a task is completed
def custom_callback():
print('Custom callback was called')
# mock task that will sleep for a moment
def work():
sleep(1)
return 'Task is done'
# create a thread pool
with ThreadPoolExecutor() as executor:
# execute the task
future = executor.submit(work)
# add the custom callback
future.add_done_callback(custom_callback)
# get the result
result = future.result()
print(result)
Запуск этого примера приведет к ошибке, когда обратный вызов будет вызван пулом потоков.
Task is done
exception calling callback for <Future at 0x10a05f190 state=finished returned str>
Traceback (most recent call last):
TypeError: custom_callback() takes 0 positional arguments but 1 was given
Исправление этой ошибки заключается в обновлении сигнатуры вашей функции обратного вызова, чтобы она включала объект Future.
# callback function to call when a task is completed
def custom_callback(future):
print('Custom callback was called')
Общие вопросы при использовании ThreadPoolExecutor
В этом разделе содержатся ответы на распространенные вопросы, задаваемые разработчиками при использовании ThreadPoolExecutor.
У вас есть вопрос по ThreadPoolExecutor?
Задайте свой вопрос в комментариях ниже, и я постараюсь ответить на него и, возможно, добавить его в этот список вопросов.
Как остановить запущенную задачу?
Задача в ThreadPoolExecutor может быть отменена до начала ее выполнения.
В этом случае задача должна была быть отправлена в пул вызовом submit(), который возвращает объект Future. Затем можно вызвать функцию cancel() в будущем.
Если задача уже запущена, она не может быть отменена, остановлена или завершена пулом потоков.
Вместо этого вы должны добавить эту функциональность в свою задачу.
Одним из подходов может быть использование флага потокобезопасности, например threading.Event, который, если установлен, будет указывать, что все задачи должны прекратить выполнение, как только смогут. Вы можете обновить функцию или функции целевой задачи, чтобы часто проверять состояние этого флага.
Возможно, вам придется изменить структуру задания.
Например, если ваша задача считывает данные из файла или сокета, вам может понадобиться изменить операцию чтения, чтобы она выполнялась блоками данных в цикле, чтобы на каждой итерации цикла можно было проверять состояние флага.
В примере ниже приведен шаблон, который можно использовать для добавления флага события в функцию целевой задачи, чтобы проверить наличие условия остановки для закрытия всех текущих задач.
Ниже приведен пример, демонстрирующий это на примере работы.
# SuperFastPython.com
# example of stopping running tasks using an event
from time import sleep
from threading import Event
from concurrent.futures import ThreadPoolExecutor
# mock target task function
def work(event):
# pretend read data for a long time
for _ in range(100):
# pretend to read some data
sleep(1)
# check the status of the flag
if event.is_set():
# shut down this task now
print("Not done, asked to stop")
return
return "All done!"
# create an event to shut down all running tasks
event = Event()
# create a thread pool
executor = ThreadPoolExecutor(5)
# execute all of our tasks
futures = [executor.submit(work, event) for _ in range(50)]
# wait a moment
print('Tasks are running...')
sleep(2)
# cancel all scheduled tasks
print('Cancelling all scheduled tasks...')
for future in futures:
future.cancel()
# stop all currently running tasks
print('Trigger all running tasks to stop...')
event.set()
# shutdown the thread pool and wait for all tasks to complete
print('Shutting down...')
executor.shutdown()
При первом запуске примера создается пул потоков с 5 рабочими потоками и планируется выполнение 50 задач.
Создается объект события и передается в каждую задачу, где он проверяется каждую итерацию, чтобы увидеть, был ли он установлен, и если да, то выйти из задачи.
Первые 5 задач начинают выполняться в течение нескольких секунд, затем мы решаем все выключить.
Сначала мы отменяем все запланированные задачи, которые еще не запущены, чтобы, если они попадут из очереди в рабочий поток, они не начали выполняться.
Затем мы помечаем событие, чтобы вызвать остановку всех запущенных задач.
Затем пул потоков закрывается, и мы ждем, пока все запущенные потоки завершат свое выполнение.
Пять запущенных потоков проверяют статус события в своей следующей итерации цикла и выходят из него, печатая сообщение.
Tasks are running...
Cancelling all scheduled tasks...
Trigger all running tasks to stop...
Shutting down...
Not done, asked to stop
Not done, asked to stop
Not done, asked to stop
Not done, asked to stop
Not done, asked to stop
Как дождаться завершения всех заданий?
Существует несколько способов дождаться завершения всех задач в ThreadPoolExecutor.
Во-первых, если у вас есть объект Future для всех задач в пуле потоков, поскольку вы вызвали submit(), то вы можете предоставить коллекцию задач функции модуля wait(). По умолчанию эта функция вернется, когда все предоставленные объекты Future завершатся.
# wait for all tasks to complete
wait(futures)
Альтернативно можно перечислить список объектов Future и попытаться получить результат из каждого. Эта итерация завершится, когда все результаты будут доступны, что означает, что все задачи были выполнены.
# wait for all tasks to complete by getting all results
for future in futures:
result = future.result()
# all tasks are complete
Другой подход заключается в отключении пула потоков. Мы можем установить значение "cancel_futures" в True, что приведет к отмене всех запланированных задач и ожиданию завершения всех текущих задач.
# shutdown the pool, cancels scheduled tasks, returns when running tasks complete
executor.shutdown(wait=True, cancel_futures=True)
Вы также можете выключить пул и не отменять запланированные задачи, но при этом дождаться завершения всех задач. В этом случае все запущенные и запланированные задачи будут завершены до возвращения функции. Это поведение функции shutdown() по умолчанию, но нелишним будет указать его явно.
# shutdown the pool, returns after all scheduled and running tasks complete
executor.shutdown(wait=True, cancel_futures=False)
Как динамически изменить количество потоков?
Вы не можете динамически увеличивать или уменьшать количество потоков в ThreadPoolExecutor.
Количество потоков фиксировано, если в вызове конструктора объекта настроен ThreadPoolExecutor. Например:
# configure a thread pool
executor = ThreadPoolExecutor(20)
Как выйти из задачи?
Ваши целевые функции задач выполняются рабочими потоками в пуле потоков, и вас может беспокоить, является ли ведение журнала из этих функций задач безопасным для потоков.
То есть, будет ли журнал поврежден, если два потока попытаются сделать это одновременно. Ответ - нет, журнал не будет поврежден.
Функциональность протоколирования в Python по умолчанию является потокобезопасной.
Например, смотрите эту цитату из документации API модуля протоколирования:
Модуль протоколирования предназначен для обеспечения потокобезопасности без какой-либо специальной работы со стороны клиентов. Это достигается за счет использования потокобезопасных блокировок; существует одна блокировка для сериализации доступа к общим данным модуля, и каждый обработчик также создает блокировку для сериализации доступа к своему базовому вводу/выводу.
— LOGGING FACILITY FOR PYTHON, THREAD SAFETY.
Таким образом, вы можете вести журнал из функций целевой задачи напрямую.
Как объединить задачи и пулы потоков?
Вы можете напрямую тестировать функции целевой задачи, возможно, подражая любым необходимым внешним ресурсам.
Вы можете протестировать использование пула потоков с помощью имитационных задач, которые не взаимодействуют с внешними ресурсами.
Единичное тестирование задач и самого пула потоков должно быть рассмотрено как часть вашего проекта и может потребовать, чтобы соединение с ресурсом ввода-вывода было настроено так, чтобы его можно было имитировать, и чтобы целевая функция задачи, вызываемая вашим пулом потоков, была настроена так, чтобы ее можно было имитировать.
Как сравнить последовательную и параллельную производительность?
Вы можете сравнить производительность вашей программы с пулом потоков и без него.
Это может быть полезным упражнением для подтверждения того, что использование ThreadPoolExecutor в вашей программе привело к увеличению скорости.
Пожалуй, самый простой подход - вручную записывать время начала и окончания выполнения кода и вычитать время окончания из времени начала, чтобы сообщить общее время выполнения. Затем запишите время с использованием и без использования пула потоков.
# SuperFastPython.com
# example of recording the execution time of a program
import time
# record the start time
start_time = time.time()
# do work with or without a thread pool
# ....
time.sleep(3)
# record the end time
end_time = time.time()
# report execution time
total_time = end_time - start_time
print(f'Execution time: {total_time:.1f} seconds.')
Использование среднего времени выполнения программы может дать более стабильное время выполнения программы, чем однократный прогон.
Вы можете записать время выполнения 3 или более раз для вашей программы без пула потоков, а затем вычислить среднее значение как сумму времен, деленную на общее количество запусков. Затем повторите это упражнение, чтобы вычислить среднее время с пулом потоков.
Это, вероятно, будет уместно, только если время работы вашей программы исчисляется минутами, а не часами.
Затем вы можете сравнить последовательную и параллельную версии, вычислив кратное увеличение скорости следующим образом:
- Кратное ускорение = Последовательное время / Параллельное время
Например, если последовательный запуск программы занял 15 минут (900 секунд), а параллельная версия с ThreadPoolExecutor - 5 минут (300 секунд), то кратное увеличение в процентах будет вычислено так:
- Кратное ускорение = Последовательное время / Параллельное время
- Множитель скорости = 900 / 300
- Множитель скорости = 3
То есть параллельная версия программы с ThreadPoolExecutor работает в 3 раза быстрее или в 3 раза быстрее.
Вы можете умножить значение ускорения на 100, чтобы получить процент
- Процент ускорения = Кратность ускорения * 100
В этом примере параллельная версия на 300% быстрее последовательной.
Как установить chunksize в map()?
Функция map() на ThreadPoolExecutor принимает параметр "chunksize", который по умолчанию равен 1.
Параметр chunksize не используется ThreadPoolExecutor; он используется только ProcessPoolExecutor, поэтому его можно смело игнорировать.
Установка этого параметра ничего не дает при использовании ThreadPoolExecutor.
Как отправить задание на выполнение?
Некоторые задачи требуют выполнения второй задачи, которая каким-то образом использует результат первой задачи.
Мы можем назвать это необходимостью выполнять последующее задание для каждого отправленного задания, которое может быть каким-то образом обусловлено результатом.
Существует несколько способов отправки последующего задания.
Один из подходов заключается в том, чтобы отправлять последующее задание по мере обработки результатов первого задания.
Например, мы можем обрабатывать результаты каждой из первых задач по мере их выполнения, затем вручную вызывать submit() для каждой последующей задачи, когда это необходимо, и сохранять новый объект future во втором списке для последующего использования.
Мы можем конкретизировать этот пример подачи последующих заданий с помощью полного примера.
# SuperFastPython.com
# example of submitting follow-up tasks
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
# mock test that works for moment
def task1():
value = random()
sleep(value)
print(f'Task 1: {value}')
return value
# mock test that works for moment
def task2(value1):
value2 = random()
sleep(value2)
print(f'Task 2: value1={value1}, value2={value2}')
return value2
# start the thread pool
with ThreadPoolExecutor(5) as executor:
# send in the first tasks
futures1 = [executor.submit(task1) for _ in range(10)]
# process results in the order they are completed
futures2 = list()
for future1 in as_completed(futures1):
# get the result
result = future1.result()
# check if we should trigger a follow-up task
if result > 0.5:
future2 = executor.submit(task2, result)
futures2.append(future2)
# wait for all follow-up tasks to complete
Запуск примера запускает пул потоков с 5 рабочими потоками и отправляет 10 заданий.
Затем мы обрабатываем результаты по заданиям по мере их выполнения. Если результат, полученный в ходе первого раунда заданий, требует последующего задания, мы отправляем последующее задание и отслеживаем объект Future во втором списке.
Эти последующие задачи отправляются по мере необходимости, а не дожидаются завершения всех задач первого раунда, что является приятным преимуществом использования функции as_completed() со списком объектов Future.
Мы видим, что в данном случае пять заданий первого тура привели к выполнению последующих заданий.
Task 1: 0.021868594663798424
Task 1: 0.07220684891621587
Task 1: 0.1889059597524675
Task 1: 0.4044025009726221
Task 1: 0.5377728619737125
Task 1: 0.5627604576510364
Task 1: 0.19590409149609522
Task 1: 0.8350495785309672
Task 2: value1=0.8350495785309672, value2=0.21472292885893007
Task 2: value1=0.5377728619737125, value2=0.6180101068687799
Task 1: 0.9916368220002719
Task 1: 0.6688307514083958
Task 2: value1=0.6688307514083958, value2=0.2691774622597396
Task 2: value1=0.5627604576510364, value2=0.859736361909423
Task 2: value1=0.9916368220002719, value2=0.642060404763057
Возможно, вам захочется использовать отдельный пул потоков для последующих задач, чтобы все было разделено.
Я бы не рекомендовал отправлять новые задачи изнутри задачи.
Это потребовало бы доступа к пулу потоков либо как к глобальной переменной, либо путем передачи, и нарушило бы идею о том, что задачи являются чистыми функциями, не имеющими побочных эффектов, что является хорошей практикой при использовании пулов потоков.
Как хранить локальное состояние для каждого потока?
Вы можете использовать локальные переменные потоков для рабочих потоков в ThreadPoolExecutor.
Обычной схемой является использование пользовательской функции инициализатора для каждого рабочего потока, чтобы установить локальную переменную потока, специфичную для каждого рабочего потока.
Затем эти локальные переменные могут использоваться каждым потоком внутри каждой задачи, при этом задача должна быть осведомлена о механизме локализации потоков.
Мы можем продемонстрировать это на рабочем примере.
Во-первых, мы можем определить пользовательскую функцию инициализатора, которая принимает локальный контекст потока и устанавливает пользовательскую переменную с именем "key" с уникальным значением между 0.0 и 1.0 для каждого рабочего потока.
# function for initializing the worker thread
def initializer_worker(local):
# generate a unique value for the worker thread
local.key = random()
# store the unique worker key in a thread local variable
print(f'Initializing worker thread {local.key}')
Затем мы можем определить нашу целевую функцию задачи, чтобы взять тот же самый локальный контекст потока и получить доступ к локальной переменной потока для рабочего потока и использовать ее.
# a mock task that sleeps for a random amount of time less than one second
def task(local):
# access the unique key for the worker thread
mykey = local.key
# make use of it
sleep(mykey)
return f'Worker using {mykey}'
Затем мы можем настроить наш новый экземпляр ThreadPoolExecutor на использование инициализатора с требуемым локальным аргументом.
# get the local context
local = threading.local()
# create a thread pool
executor = ThreadPoolExecutor(max_workers=2, initializer=initializer_worker, initargs=(local,))
Затем отправьте задачи в пул потоков с локальным контекстом того же потока.
# dispatch asks
futures = [executor.submit(task, local) for _ in range(10)]
Ниже приведен полный пример использования ThreadPoolExecutor с локальным хранилищем потоков.
# SuperFastPython.com
# example of thread local storage for worker threads
from time import sleep
from random import random
import threading
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# function for initializing the worker thread
def initializer_worker(local):
# generate a unique value for the worker thread
local.key = random()
# store the unique worker key in a thread local variable
print(f'Initializing worker thread {local.key}')
# a mock task that sleeps for a random amount of time less than one second
def task(local):
# access the unique key for the worker thread
mykey = local.key
# make use of it
sleep(mykey)
return f'Worker using {mykey}'
# get the local context
local = threading.local()
# create a thread pool
executor = ThreadPoolExecutor(max_workers=2, initializer=initializer_worker, initargs=(local,))
# dispatch asks
futures = [executor.submit(task, local) for _ in range(10)]
# wait for all threads to complete
for future in futures:
result = future.result()
print(result)
# shutdown the thread pool
executor.shutdown()
print('done')
Сначала запуск примера настраивает пул потоков на использование нашей пользовательской функции инициализатора, которая устанавливает локальную переменную потока для каждого рабочего потока с уникальным значением, в данном случае два потока со значением между 0 и 1.
Затем каждый рабочий поток работает над заданиями в очереди, все десять, каждый из которых использует конкретное значение локальной переменной thread, заданной для потока в функции инициализации.
Initializing worker thread 0.9360961457279074
Initializing worker thread 0.9075641843481475
Worker using 0.9360961457279074
Worker using 0.9075641843481475
Worker using 0.9075641843481475
Worker using 0.9360961457279074
Worker using 0.9075641843481475
Worker using 0.9360961457279074
Worker using 0.9075641843481475
Worker using 0.9360961457279074
Worker using 0.9075641843481475
Worker using 0.9360961457279074
done
Как показать прогресс выполнения всех заданий?
Существует множество способов показать прогресс для задач, выполняемых ThreadPoolExecutor.
Пожалуй, самое простое - использовать функцию обратного вызова, которая обновляет индикатор выполнения. Этого можно добиться, определив функцию индикатора выполнения и зарегистрировав ее в объекте Future для каждой задачи с помощью функции add_done_callback().
Простейший индикатор выполнения - это печать точки на экране для каждого выполненного задания.
Ниже приведен пример, демонстрирующий этот простой индикатор прогресса.
# SuperFastPython.com
# example of a simple progress indicator
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import wait
# simple progress indicator callback function
def progress_indicator(future):
print('.', end='', flush=True)
# mock test that works for moment
def task(name):
sleep(random())
# start the thread pool
with ThreadPoolExecutor(2) as executor:
# send in the tasks
futures = [executor.submit(task, i) for i in range(20)]
# register the progress indicator callback
for future in futures:
future.add_done_callback(progress_indicator)
# wait for all tasks to complete
print('\nDone!')
Запуск примера запускает пул потоков с двумя рабочими потоками и отправляет 20 заданий.
В каждом объекте Future регистрируется функция обратного вызова индикатора выполнения, которая печатает одну точку по мере завершения каждой задачи, обеспечивая промывку стандартного вывода при каждом вызове print() и отсутствие печати новой строки.
Это гарантирует, что каждый из нас увидит точку сразу, независимо от потока, который печатает, и что все точки появятся на одной строке.
Каждое задание будет выполняться в течение переменного времени, не превышающего одной секунды, и по его завершении будет напечатана точка.
....................
Done!
Более сложный индикатор прогресса должен знать общее количество задач и будет использовать потокобезопасный счетчик для обновления статуса количества выполненных задач из всех задач, которые должны быть выполнены.
Нужна ли проверка __main__?
При использовании ThreadPoolExecutor проверка на __main__ не требуется.
При использовании Process версии пула необходима проверка ProcessPoolExecutor на __main__. Это может быть источником путаницы.
Как получить объект будущего для задач, добавленных с помощью map()?
Когда вы вызываете map(), он действительно создает объект Future для каждой задачи.
Внутри submit() вызывается для каждого элемента в итерабле, предоставленном для вызова map().
Тем не менее, не существует чистого способа доступа к объекту Future для задач, отправленных в пул потоков через map().
Каждая задача во внутренней рабочей очереди объекта ThreadPoolExecutor является экземпляром _WorkItem, который содержит ссылку на объект Future для этой задачи. Вы можете получить доступ к внутренней очереди объекта ThreadPoolExecutor, но у вас нет безопасного способа перечислить элементы в очереди, не удаляя их.
Если вам нужен объект Future для задачи, вызовите submit().
Можно ли вызвать shutdown() из контекстного менеджера?
Вы можете вызвать shutdown() внутри context manager, но таких случаев не так много.
Это не приводит к ошибке, которую я вижу.
Вы можете захотеть вызвать shutdown() явно, если вы хотите отменить все запланированные задачи и у вас нет доступа к объектам Future, и вы хотите сделать другую очистку, прежде чем ждать, пока все запущенные задачи остановятся.
Было бы странно, если бы вы оказались в такой ситуации.
Тем не менее, вот пример вызова shutdown() из контекстного менеджера.
# SuperFastPython.com
# example of shutting down within a context manager
from time import sleep
from concurrent.futures import ThreadPoolExecutor
# mock test that works for moment
def task(name):
sleep(2)
print(f'Done: {name}')
# start the thread pool
with ThreadPoolExecutor(1) as executor:
# send some tasks into the thread pool
print('Sending in tasks...')
futures = [executor.submit(task, i) for i in range(10)]
# explicitly shutdown within the context manager
print('Shutting down...')
executor.shutdown(wait=False, cancel_futures=True)
# shutdown called again here when context manager exited
print('Waiting...')
print('Doing other things...')
Запуск примера запускает пул потоков с одним рабочим потоком, а затем отправляет на выполнение десять заданий.
Затем мы явно вызываем shutdown на пуле потоков и отменяем все запланированные задачи без ожидания.
Затем мы выходим из контекстного менеджера и ждем завершения всех задач. Это второе выключение работает, как и ожидалось, ожидая завершения одной запущенной задачи перед возвращением.
Sending in tasks...
Shutting down...
Waiting...
Done: 0
Doing other things...
Общие возражения против использования ThreadPoolExecutor
Исполнитель ThreadPoolExecutor может быть не лучшим решением для всех проблем многопоточности в вашей программе.
При этом, возможно, существуют некоторые недоразумения, которые мешают вам в полной мере и наилучшим образом использовать возможности ThreadPoolExecutor в вашей программе.
В этом разделе мы рассмотрим некоторые из распространенных возражений, с которыми сталкиваются разработчики при рассмотрении возможности использования ThreadPoolExecutor в своем коде.
Что касается глобальной блокировки интерпретатора (GIL)?
Глобальная блокировка интерпретатора, или сокращенно GIL, - это конструктивное решение, принятое в эталонном интерпретаторе Python.
Это связано с тем, что в реализации интерпретатора Python используется мастер-блокировка, которая предотвращает одновременное выполнение более одной инструкции Python.
Это предотвращает более одного потока выполнения в программах Python, а именно в каждом процессе Python, то есть в каждом экземпляре интерпретатора Python.
Реализация GIL означает, что потоки Python могут быть параллельными, но не могут работать параллельно. Напомним, что параллельное выполнение означает, что более одной задачи может выполняться одновременно; параллельное выполнение означает, что более одной задачи фактически выполняется одновременно. Параллельные задачи являются параллельными, параллельные задачи могут выполняться параллельно, а могут и не выполняться.
Это причина эвристики, согласно которой потоки Python должны использоваться только для задач, связанных с IO, а не с CPU, поскольку задачи, связанные с IO, будут ждать в ядре операционной системы ответа от удаленных ресурсов (не выполняя инструкции Python), позволяя другим потокам Python запускаться и выполнять инструкции Python.
С другой стороны, GIL не означает, что мы не можем использовать потоки в Python, только то, что некоторые случаи использования потоков в Python являются жизнеспособными или подходящими.
Это решение было принято в рамках эталонной реализации интерпретатора Python (с сайта Python.org), но может не повлиять на другие интерпретаторы (такие как PyPy, Iron Python и Jython), которые позволяют выполнять несколько инструкций Python одновременно и параллельно.
Подробнее об этой теме вы можете узнать здесь:
Являются ли потоки Python "настоящими потоками"?
Да.
Python использует реальные потоки системного уровня, также называемые потоками уровня ядра, - возможность, предоставляемая современными операционными системами, такими как Windows, Linux и MacOS.
Потоки в Python не являются потоками программного уровня, иногда их называют потоками пользовательского уровня или зелеными потоками.
Разве нити Python не багги?
Нет.
Потоки Python не имеют ошибок.
Потоковая обработка в Python - это первоклассная возможность платформы Python, которая существует уже очень долгое время.
Разве Python не является плохим выбором для параллелизма?
Разработчики любят python по многим причинам, чаще всего за то, что он прост в использовании и быстр в разработке.
Python обычно используется для создания "клеящегося" кода, одноразовых скриптов, но все больше и больше - для масштабных программных систем.
Если вы используете Python и вам нужен параллелизм, то вы работаете с тем, что у вас есть. Вопрос спорный.
Если вам нужен параллелизм, а вы не выбрали язык, возможно, другой язык будет более подходящим, а возможно, и нет. Рассмотрите весь объем функциональных и нефункциональных требований (или потребностей, желаний и запросов пользователей) для вашего проекта и возможности различных платформ разработки.
Почему бы не использовать ProcessPoolExecutor вместо этого?
Исполнитель ProcessPoolExecutor поддерживает пулы процессов, в отличие от ThreadPoolExecutor, который поддерживает пулы потоков.
"Нити" и "Процессы" совершенно разные, и выбор одного из них является преднамеренным.
Программа на Python - это процесс, имеющий главный поток. Вы можете создать множество дополнительных потоков в процессе Python. Вы также можете создать или породить множество процессов Python, каждый из которых будет иметь один поток и может порождать дополнительные потоки.
В более широком смысле, потоки являются легкими и могут совместно использовать память (данные и переменные) внутри процесса, в то время как процессы являются тяжелыми, требуют больше накладных расходов и накладывают больше ограничений на совместное использование памяти (данных и переменных).
Обычно процессы используются для задач, связанных с процессором, а потоки - для задач, связанных с вводом-выводом, и это хорошая эвристика, но это не обязательно так.
Возможно, ProcessPoolExecutor лучше подходит для решения вашей конкретной задачи. Попробуйте и посмотрите.
Подробнее об этой теме вы можете узнать здесь:
Почему бы не использовать threading.Thread вместо этого?
Исполнитель ThreadPoolExecutor - это как "автоматический режим" для потоковой обработки в Python.
Если у вас более сложный случай использования, вам может понадобиться использовать класс threading.Thread напрямую.
Это может быть связано с тем, что вам требуется больше синхронизации между потоками с помощью механизмов блокировки и/или больше координации между потоками с помощью барьеров и семафоров.
Возможно, у вас более простой случай использования, например, одна задача, и в этом случае, возможно, пул потоков будет слишком тяжелым решением.
При этом, если вы используете класс Thread с ключевым словом target для чистых функций (функций, не имеющих побочных эффектов), возможно, вам лучше использовать ThreadPoolExecutor.
Подробнее об этой теме вы можете узнать здесь:
Почему не использовать AsyncIO?
AsyncIO может быть альтернативой использованию ThreadPoolExecutor.
AsyncIO предназначен для поддержки большого количества операций ввода-вывода, возможно, от тысяч до десятков тысяч, и все это в рамках одного потока.
Это требует альтернативной парадигмы программирования, называемой реактивным программированием, которая может быть сложной для новичков.
Тем не менее, это может быть лучшей альтернативой использованию пула потоков для многих приложений.
Подробнее об этой теме вы можете узнать здесь:
Вернуться на верх