Распознавание лиц с помощью Python
Оглавление
- Что такое распознавание лиц?
- Как компьютеры "видят" изображения?
- Что такое характеристики?
- Подготовка
- Система обнаружения объектов Виолы-Джонса
- Дальнейшее чтение
- Заключение
Компьютерное зрение - это захватывающая и развивающаяся область. Здесь можно решить массу интересных задач! Одна из них - обнаружение лиц: способность компьютера распознать, что на фотографии есть человеческое лицо, и сказать, где оно находится. В этой статье вы узнаете об обнаружении лиц с помощью Python.
Чтобы обнаружить любой объект на изображении, необходимо понять, как изображения представляются в компьютере и как этот объект отличается визуально от любого другого объекта.
После этого необходимо автоматизировать и оптимизировать процесс сканирования изображения и поиска визуальных подсказок. Все эти этапы объединяются в быстрый и надежный алгоритм компьютерного зрения.
В этом уроке вы узнаете:
- Что такое распознавание лиц
- Как компьютеры понимают особенности изображений
- Как быстро проанализировать множество различных признаков для принятия решения
- Как использовать минимальное решение на Python для обнаружения человеческих лиц на изображениях
Что такое распознавание лиц?
Определение лиц - это разновидность технологии компьютерного зрения, которая позволяет идентифицировать лица людей на цифровых изображениях. Для человека это очень просто, но компьютеру нужны точные инструкции. Изображения могут содержать множество объектов, которые не являются человеческими лицами, например здания, автомобили, животные и т. д.
Отличается от других технологий компьютерного зрения, связанных с человеческими лицами, таких как распознавание, анализ и отслеживание лиц.
Распознавание лица предполагает идентификацию лица на изображении как принадлежащего человеку X, а не человеку Y. Она часто используется для биометрических целей, например для разблокировки смартфона.
Анализ лица пытается понять что-то о людях по их чертам лица, например, определить их возраст, пол или эмоции, которые они демонстрируют.
Отслеживание лица в основном присутствует в анализе видео и пытается проследить за лицом и его чертами (глаза, нос, губы) от кадра к кадру. Наиболее популярными приложениями являются различные фильтры, доступные в мобильных приложениях, таких как Snapchat.
Все эти проблемы имеют различные технологические решения. В этом учебнике мы рассмотрим традиционное решение первой задачи: распознавание лиц.
Как компьютеры "видят" изображения?
Наименьший элемент изображения называется пикселем, или элементом картинки. По сути, это точка на изображении. Изображение содержит множество пикселей, расположенных в строках и столбцах.
Часто можно увидеть количество строк и столбцов, выраженное как разрешение изображения . Например, разрешение телевизора Ultra HD составляет 3840x2160, то есть 3840 пикселей в ширину и 2160 пикселей в высоту.
Но компьютер не понимает пиксели как точки цвета. Он понимает только числа. Чтобы преобразовать цвета в числа, компьютер использует различные цветовые модели.
В цветных изображениях пиксели часто представляются в цветовой модели RGB. RGB расшифровывается как Red Green Blue. Каждый пиксель представляет собой смесь этих трех цветов. RGB отлично моделирует все цвета, воспринимаемые человеком, комбинируя различные количества красного, зеленого и синего.
Поскольку компьютер понимает только числа, каждый пиксель представлен тремя числами, соответствующими количеству красного, зеленого и синего цветов, присутствующих в этом пикселе. Подробнее о цветовых пространствах вы можете узнать в Image Segmentation Using Color Spaces in OpenCV + Python.
В полутоновых (черно-белых) изображениях каждый пиксель представляет собой одно число, отражающее количество света, или интенсивность, которое он несет. Во многих приложениях диапазон интенсивности составляет от 0 (черный) до 255 (белый). Все, что находится между 0 и 255, - это различные оттенки серого.
Если каждый пиксель шкалы серого - это число, то изображение - это не что иное, как матрица (или таблица) чисел:

Пример изображения 3x3 со значениями пикселей и цветами
В цветных изображениях есть три такие матрицы, представляющие красный, зеленый и синий каналы.
Что такое особенности?
А feature - это часть информации на изображении, которая имеет отношение к решению определенной задачи. Это может быть что-то простое, как значение одного пикселя, или более сложное, как края, углы и формы. Можно объединить несколько простых признаков в сложный признак.
Применяя определенные операции к изображению, можно получить информацию, которую также можно считать признаками. Компьютерное зрение и обработка изображений располагают большой коллекцией полезных признаков и операций извлечения признаков.
По сути, любое присущее или производное свойство изображения может быть использовано в качестве признака для решения задач.
Подготовка
Для запуска примеров кода необходимо установить окружение со всеми необходимыми библиотеками. Самый простой способ - использовать conda.
Вам понадобятся три библиотеки:
scikit-imagescikit-learnopencv
Чтобы создать окружение в conda, выполните в командной оболочке следующие команды:
$ conda create --name face-detection python=3.7
$ source activate face-detection
(face-detection)$ conda install scikit-learn
(face-detection)$ conda install -c conda-forge scikit-image
(face-detection)$ conda install -c menpo opencv3
Если у вас возникли проблемы с правильной установкой OpenCV и запуском примеров, попробуйте обратиться к их руководству по установке или к статье OpenCV Tutorials, Resources, and Guides.
Теперь у вас есть все пакеты, необходимые для практического применения знаний, полученных в этом учебнике.
Система обнаружения объектов Виолы-Джонса
Этот алгоритм назван в честь двух исследователей компьютерного зрения, предложивших этот метод в 2001 году: Пола Виолы и Майкла Джонса.
Они разработали фреймворк общего обнаружения объектов, способный обеспечить конкурентоспособную скорость обнаружения объектов в реальном времени. Его можно использовать для решения различных задач обнаружения, но основная мотивация связана с обнаружением лиц.
Алгоритм Виолы-Джонса состоит из 4 основных шагов, о каждом из которых вы узнаете в следующих разделах:
- Выделение хаар-подобных признаков
- Создание интегрального изображения
- Выполнение обучения AdaBoost
- Создание каскадов классификаторов
Получив изображение, алгоритм просматривает множество мелких субрегионов и пытается найти лицо, ища специфические черты в каждом субрегионе. При этом необходимо проверять множество различных положений и масштабов, поскольку изображение может содержать множество лиц разного размера. Виола и Джонс использовали Хаар-подобные признаки для обнаружения лиц.
Хаар-подобные особенности
Все человеческие лица имеют некоторые общие черты. Если вы посмотрите на фотографию с изображением лица человека, то увидите, например, что область глаз темнее, чем переносица. Щеки также светлее, чем область глаз. Мы можем использовать эти свойства, чтобы понять, есть ли на изображении человеческое лицо.
Простой способ определить, какой регион светлее или темнее, - это просуммировать значения пикселей обоих регионов и сравнить их. Сумма значений пикселей в более темном регионе будет меньше, чем сумма пикселей в более светлом регионе. Этого можно добиться с помощью Haar-подобных функций.
Хаар-подобный признак представляется путем взятия прямоугольной части изображения и деления этого прямоугольника на несколько частей. Часто они визуализируются как черно-белые смежные прямоугольники:
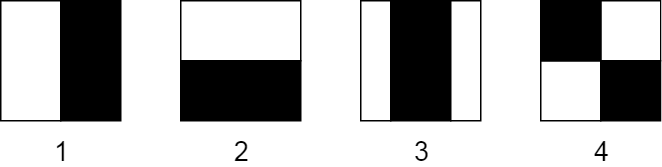
Основные характеристики прямоугольника, подобные Хаару
На этом изображении вы можете увидеть 4 основных типа Хаар-подобных функций:
- Горизонтальная черта с двумя прямоугольниками
- Вертикальная черта с двумя прямоугольниками
- Вертикальная черта с тремя прямоугольниками
- Диагональная черта с четырьмя прямоугольниками
Первые два примера полезны для обнаружения краев. Третий обнаруживает линии, а четвертый хорош для поиска диагональных черт. Но как они работают?
Значение признака вычисляется как одно число: сумма значений пикселей в черной области минус сумма значений пикселей в белой области. Для однородных областей, таких как стена, это число будет близко к нулю и не даст вам никакой значимой информации.
Чтобы быть полезной, функция, подобная Хаару, должна давать большое число, то есть области в черном и белом прямоугольниках сильно отличаются. Известны признаки, которые очень хорошо работают для обнаружения человеческих лиц:

Функция Хаара, примененная к области глаз. (Изображение: Википедия )
В данном примере область глаз темнее, чем область под ними. Вы можете использовать это свойство, чтобы определить, какие области изображения дают сильный отклик (большое число) для определенного признака:

Хаар-функция, нанесенная на переносицу. (Изображение: Википедия )
Этот пример дает сильный отклик, когда применяется к переносице. Вы можете комбинировать многие из этих признаков, чтобы понять, содержит ли область изображения человеческое лицо.
Как уже упоминалось, алгоритм Виолы-Джонса вычисляет множество этих признаков во многих подобластях изображения. Это быстро становится вычислительно дорогостоящим: требуется много времени, чтобы использовать ограниченные ресурсы компьютера.
Для решения этой проблемы Виола и Джонс использовали интегральные изображения.
Интегральные изображения
Интегральное изображение (также известное как таблица суммированных площадей) - это название как структуры данных, так и алгоритма, используемого для получения этой структуры данных. Она используется как быстрый и эффективный способ вычисления суммы значений пикселей в изображении или прямоугольной части изображения.
В интегральном изображении значение каждой точки равно сумме всех пикселей выше и левее, включая целевой пиксель:
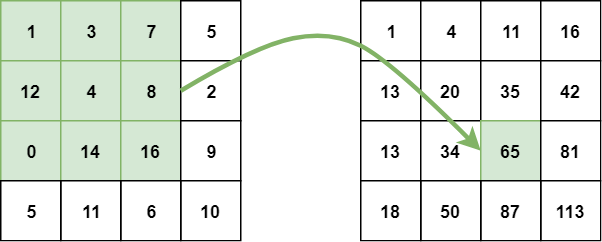
Вычисление интегрального изображения по значениям пикселей
Интегральное изображение может быть вычислено за один проход по исходному изображению. Это сводит суммирование интенсивностей пикселей в пределах прямоугольника всего к трем операциям с четырьмя числами, независимо от размера прямоугольника:
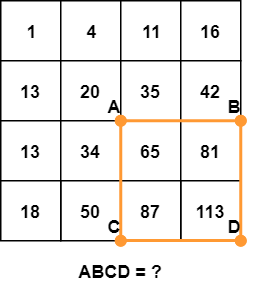
Вычислите сумму пикселей в оранжевом прямоугольнике.
Сумму пикселей в прямоугольнике ABCD можно получить из значений точек A, B, C и D по формуле D - B - C + A. Проще понять эту формулу визуально:
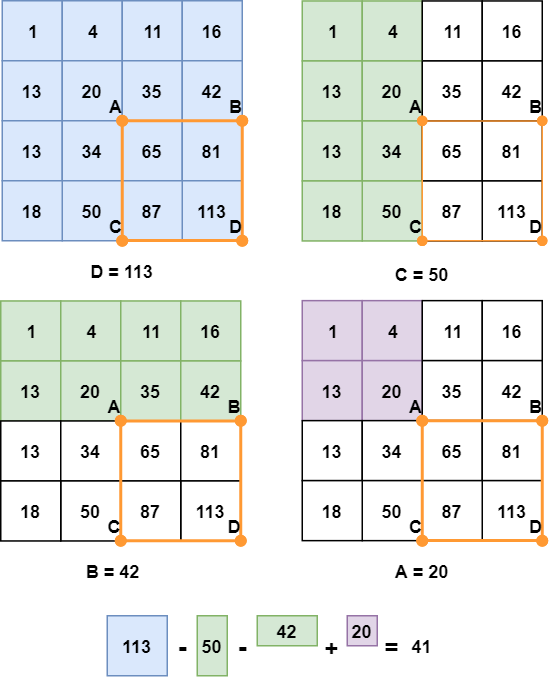
Пошаговое вычисление суммы пикселей
Вы заметите, что вычитание как B, так и C означает, что область, определенная с помощью A, была вычтена дважды, поэтому нам нужно прибавить ее снова.
Теперь у вас есть простой способ вычислить разницу между суммами значений пикселей двух прямоугольников. Это идеально подходит для Хаар-подобных функций!
Но как решить, какие из этих признаков и в каких размерах использовать для поиска лиц на изображениях? Это решается с помощью алгоритма машинного обучения, который называется boosting. В частности, вы узнаете об AdaBoost, сокращенном от Adaptive Boosting.
AdaBoost
В основе Boosting лежит следующий вопрос: "Может ли набор слабых обучаемых создать одного сильного обучаемого?". Слабый обучаемый (или слабый классификатор) определяется как классификатор, который лишь немного лучше, чем случайное угадывание.
При распознавании лиц это означает, что слабый обучаемый может классифицировать субрегион изображения как лицо или не-лицо лишь немного лучше, чем случайное угадывание. Сильный обучаемый значительно лучше отбирает лица от не-лиц.
Сила boosting заключается в объединении многих (тысяч) слабых классификаторов в один сильный классификатор. В алгоритме Виолы-Джонса каждая хаар-подобная характеристика представляет собой слабый классификатор. Чтобы выбрать тип и размер признака, который войдет в окончательный классификатор, AdaBoost проверяет производительность всех классификаторов, которые вы ему предоставите.
Чтобы рассчитать производительность классификатора, вы оцениваете его на всех подобластях всех изображений, использованных для обучения. Некоторые субрегионы вызовут сильный отклик у классификатора. Они будут классифицированы как положительные, то есть классификатор считает, что в них содержится человеческое лицо.
Подрегионы, не дающие сильного отклика, по мнению классификатора, не содержат человеческого лица. Они будут классифицированы как отрицательные.
Классификаторам, показавшим хорошие результаты, придается большее значение или вес. В итоге получается сильный классификатор, также называемый boosted classifier, который содержит наиболее эффективные слабые классификаторы.
Алгоритм называется адаптивным, поскольку по мере обучения он уделяет больше внимания тем изображениям, которые были классифицированы неверно. Слабые классификаторы, которые лучше справляются с этими трудными примерами, получают больший вес, чем другие.
Давайте рассмотрим пример:
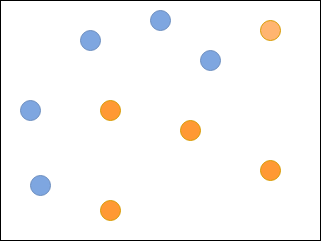
Синие и оранжевые круги - образцы, относящиеся к разным категориям.
Представьте, что вы должны классифицировать синие и оранжевые круги на следующем изображении, используя набор слабых классификаторов:
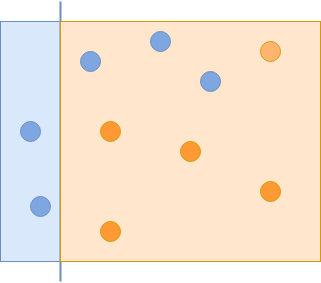
Первый слабый классификатор правильно классифицирует некоторые синие круги.
Первый классификатор, который вы используете, захватывает некоторые синие круги, но пропускает другие. На следующей итерации вы придаете большее значение пропущенным примерам:
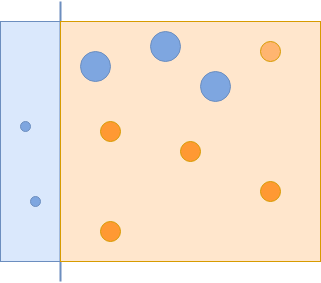
Пропущенным синим образцам придается большее значение, на что указывает их размер.
Второй классификатор, которому удалось правильно классифицировать эти примеры, получит больший вес. Помните, что если слабый классификатор работает лучше, он получит больший вес и, следовательно, больше шансов попасть в финальные, сильные классификаторы:
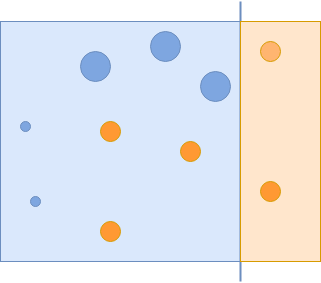
Второй классификатор фиксирует более крупные синие круги.
Теперь вам удалось захватить все синие круги, но ошибочно захватить некоторые оранжевые круги. Этим неправильно классифицированным оранжевым кругам придается большее значение в следующей итерации:
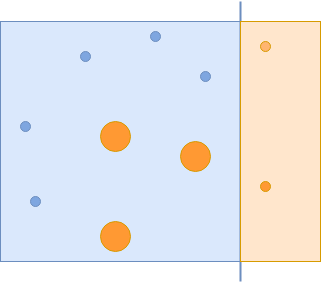
Оранжевым кружкам с неправильной классификацией придается большее значение, а остальным - меньшее.
Окончательный классификатор правильно распознает эти оранжевые круги:
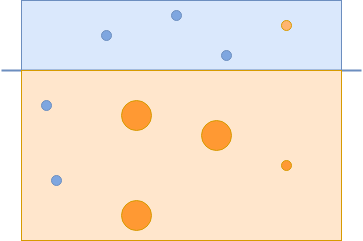
Третий классификатор фиксирует оставшиеся оранжевые круги.
Чтобы создать сильный классификатор, объедините все три классификатора, чтобы правильно классифицировать все примеры:
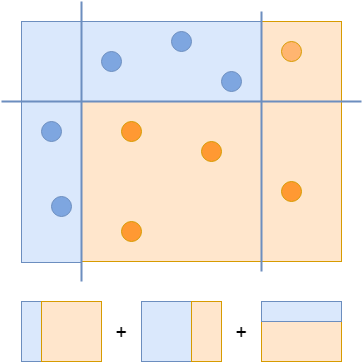
Последний, сильный классификатор объединяет все три слабых классификатора.
Используя разновидность этого процесса, Виола и Джонс проанализировали сотни тысяч классификаторов, специализирующихся на поиске лиц на изображениях. Но запуск всех этих классификаторов для каждой области на каждом изображении потребовал бы больших вычислительных затрат, поэтому они создали так называемый каскад классификаторов.
Каскадные классификаторы
Определение каскада - это серия водопадов, низвергающихся один за другим. Подобная концепция используется в информатике для решения сложной задачи с помощью простых блоков. Здесь проблема заключается в сокращении количества вычислений для каждого изображения.
Чтобы решить эту проблему, Виола и Джонс превратили свой сильный классификатор (состоящий из тысяч слабых классификаторов) в каскад, где каждый слабый классификатор представляет собой одну ступень. Задача каскада - быстро отбрасывать нелицеприятные объекты и не тратить драгоценное время и вычисления.
Когда в каскад попадает подрегион изображения, он оценивается первым этапом. Если этот этап оценивает подобласть положительно, то есть считает ее лицом, то на выходе получается maybe.
Если субрегион получает оценку maybe, он отправляется на следующий этап каскада. Если тот дает положительную оценку, то это еще один maybe, и изображение отправляется на третий этап:
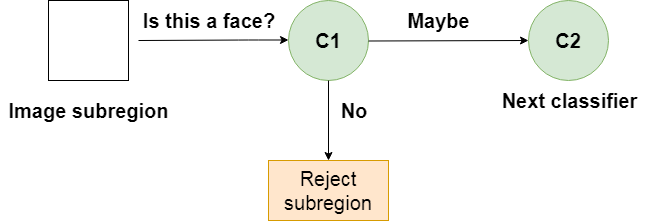
Слабый классификатор в каскаде
Этот процесс повторяется до тех пор, пока изображение не пройдет все стадии каскада. Если все классификаторы одобряют изображение, оно окончательно классифицируется как человеческое лицо и представляется пользователю в виде обнаружения.
Если же первый этап дает отрицательную оценку, то изображение сразу же отбрасывается как не содержащее человеческого лица. Если изображение проходит первый этап, но не проходит второй этап, оно также отбрасывается. В принципе, изображение может быть отброшено на любом этапе работы классификатора:
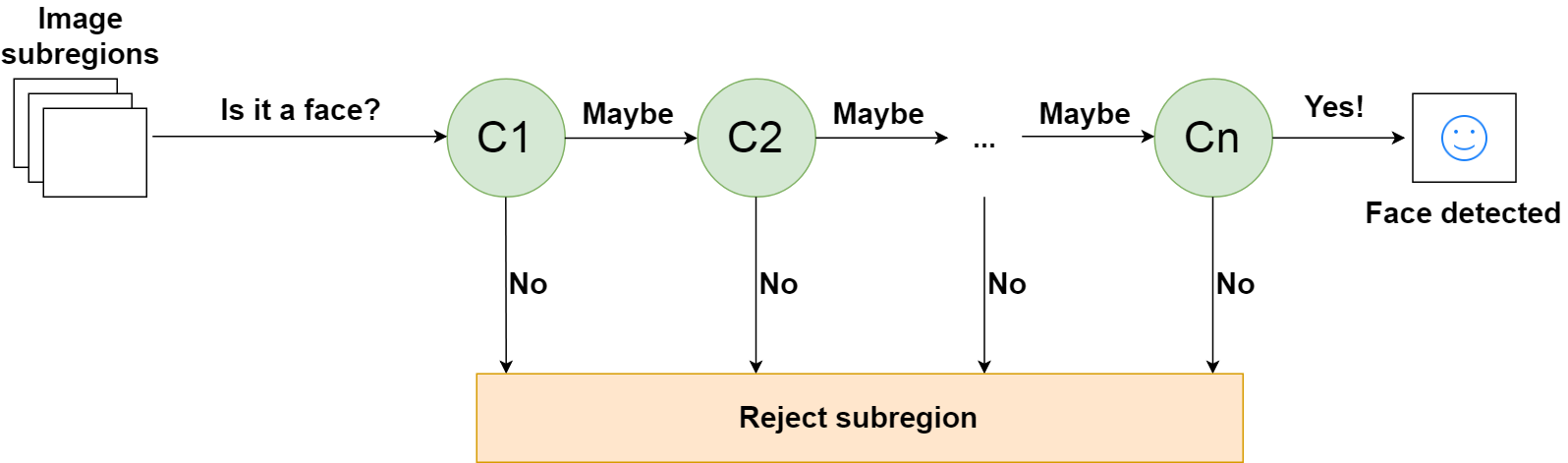
Каскад из _n_ классификаторов для распознавания лиц
Это сделано для того, чтобы нелица отбрасывались очень быстро, что экономит много времени и вычислительных ресурсов. Поскольку каждый классификатор представляет один из признаков человеческого лица, положительное обнаружение, по сути, говорит: "Да, эта подобласть содержит все признаки человеческого лица". Но как только один признак отсутствует, он отвергает всю подобласть.
Для эффективного решения этой задачи важно поместить наиболее эффективные классификаторы в начало каскада. В алгоритме Виолы-Джонса классификаторы глаз и переносицы являются примерами наиболее эффективных слабых классификаторов.
Теперь, когда вы поняли, как работает алгоритм, пришло время использовать его для обнаружения лиц с помощью Python.
Использование классификатора Виолы-Джонса
Обучение классификатора Виолы-Джонса с нуля может занять много времени. К счастью, в OpenCV уже есть готовый классификатор Виолы-Джонса! С его помощью вы увидите алгоритм в действии.
Сначала найдите и загрузите изображение, которое вы хотели бы просканировать на наличие человеческих лиц. Вот пример:

Пример стоковой фотографии для определения лица ( Источник изображения )
Импортируйте OpenCV и загрузите изображение в память:
import cv2 as cv
# Read image from your local file system
original_image = cv.imread('path/to/your-image.jpg')
# Convert color image to grayscale for Viola-Jones
grayscale_image = cv.cvtColor(original_image, cv.COLOR_BGR2GRAY)
Далее необходимо загрузить классификатор Виолы-Джонса. Если вы установили OpenCV из исходников, он будет находиться в папке, куда вы установили библиотеку OpenCV.
В зависимости от версии, точный путь может отличаться, но имя папки будет haarcascades, и она будет содержать несколько файлов. Тот, который вам нужен, называется haarcascade_frontalface_alt.xml.
Если по какой-то причине ваша установка OpenCV не получила предварительно обученный классификатор, вы можете получить его из OpenCV GitHub repo:
# Load the classifier and create a cascade object for face detection
face_cascade = cv.CascadeClassifier('path/to/haarcascade_frontalface_alt.xml')
У объекта face_cascade есть метод detectMultiScale(), который получает изображение в качестве аргумента и запускает каскад классификаторов над изображением. Термин MultiScale указывает на то, что алгоритм рассматривает подобласти изображения в нескольких масштабах, чтобы обнаружить лица разного размера:
detected_faces = face_cascade.detectMultiScale(grayscale_image)
Переменная detected_faces теперь содержит все обнаружения для целевого изображения. Чтобы визуализировать обнаружения, необходимо выполнить итерацию по всем обнаружениям и нарисовать прямоугольники над обнаруженными гранями.
Программа OpenCV rectangle() рисует прямоугольники на изображениях, и ей необходимо знать пиксельные координаты левого верхнего и правого нижнего угла. Эти координаты указывают на строку и столбец пикселей в изображении.
К счастью, обнаружения сохраняются в виде пиксельных координат. Каждое обнаружение определяется координатами левого верхнего угла, а также шириной и высотой прямоугольника, в котором находится обнаруженное лицо.
Добавив ширину к строке и высоту к столбцу, вы получите правый нижний угол изображения:
for (column, row, width, height) in detected_faces:
cv.rectangle(
original_image,
(column, row),
(column + width, row + height),
(0, 255, 0),
2
)
rectangle() принимает следующие аргументы:
- Оригинальное изображение
- Координаты левой верхней точки обнаружения
- Координаты правой нижней точки обнаружения
- Цвет прямоугольника (кортеж, определяющий количество красного, зеленого и синего цветов (
0-255)) - Толщина линий прямоугольника
Наконец, нужно вывести изображение на экран:
cv.imshow('Image', original_image)
cv.waitKey(0)
cv.destroyAllWindows()
imshow() выводит изображение. waitKey() ожидает нажатия клавиши. В противном случае imshow() выведет изображение и сразу же закроет окно. Передача 0 в качестве аргумента заставляет его ждать бесконечно. Наконец, destroyAllWindows() закрывает окно при нажатии клавиши.
Вот результат:

Исходное изображение с обнаруженными объектами
Вот и все! Теперь у вас есть готовый к использованию детектор лиц в Python.
Если вы действительно хотите обучить классификатор самостоятельно, scikit-image предлагает учебник с сопутствующим кодом на своем сайте.
Дальнейшее чтение
Алгоритм Виолы-Джонса был удивительным достижением. Несмотря на то что он по-прежнему отлично работает во многих случаях, ему уже почти 20 лет. Существуют и другие алгоритмы, использующие различные возможности
В одном из примеров используются машины опорных векторов (SVM) и признаки, называемые гистограммами ориентированных градиентов (HOG). Пример можно найти в Python Data Science Handbook.
Большинство современных методов обнаружения и распознавания лиц используют глубокое обучение, о котором мы расскажем в следующей статье.
Для ознакомления с новейшими исследованиями в области компьютерного зрения посмотрите последние научные статьи на сайте arXiv Computer Vision and Pattern Recognition.
Если вы интересуетесь машинным обучением, но хотите перейти к чему-то другому, нежели компьютерное зрение, обратите внимание на Practical Text Classification With Python and Keras.
Заключение
Отличная работа! Теперь вы можете находить лица на изображениях.
В этом уроке вы узнали, как представлять регионы на изображении с помощью Хаар-подобных признаков. Эти признаки можно очень быстро вычислить, используя интегральные изображения.
Вы узнали, как AdaBoost находит наиболее эффективные Хаар-подобные признаки из тысяч доступных признаков и превращает их в серию слабых классификаторов.
Наконец, вы узнали, как создать каскад слабых классификаторов, которые могут быстро и надежно отличать лица от нелиц.
Эти шаги иллюстрируют многие важные элементы компьютерного зрения:
- Поиск полезных функций
- Комбинирование их для решения сложных задач
- Балансировка между производительностью и управлением вычислительными ресурсами
Эти идеи применимы к обнаружению объектов в целом и помогут вам решить множество реальных задач. Удачи!
Вернуться на верх