Асинхронный ввод-вывод в Python
Оглавление
- Настройка среды
- Взгляд на Async IO с высоты 10 000 футов
- Пакет asyncio и async/await
- Паттерны проектирования Async IO
- Асинхронный ввод-вывод уходит корнями в генераторы
- Полная программа: Асинхронные запросы
- Асинхронный ввод-вывод в контексте
- Доводы и выводы
- Заключение
- Ресурсы
Async IO - это дизайн параллельного программирования, который получил специализированную поддержку в Python, быстро развиваясь с Python 3.4.
Возможно, вы с ужасом думаете: "Конкурентность, параллелизм, потоки, многопроцессорность. Это уже слишком много для понимания. А где же здесь async IO?"
Этот учебник призван помочь вам ответить на этот вопрос и дать более глубокое понимание подхода Python к асинхронному вводу-выводу данных.
Вот что вам предстоит узнать:
-
Асинхронный ввод-вывод (async IO): парадигма (модель), не зависящая от языка, которая имеет реализацию во множестве языков программирования
-
async/await: два новых ключевых слова в Python, которые используются для определения короутинов -
asyncio: пакет Python, обеспечивающий основу и API для запуска и управления короутинами
Корутины (специализированные функции-генераторы) являются сердцем асинхронного ввода-вывода в Python, и мы погрузимся в них позже.
Примечание: В этой статье я использую термин async IO для обозначения языкового дизайна асинхронного ввода-вывода, а asyncio относится к пакету Python.
Прежде чем приступить к работе, вам нужно убедиться, что вы настроены на использование asyncio и других библиотек, найденных в этом учебнике.
Настройка окружения
Чтобы полностью прочесть эту статью, вам понадобится Python 3.7 или выше, а также пакеты aiohttp и aiofiles:
$ python3.7 -m venv ./py37async
$ source ./py37async/bin/activate # Windows: .\py37async\Scripts\activate.bat
$ pip install --upgrade pip aiohttp aiofiles # Optional: aiodns
За помощью в установке Python 3.7 и настройке виртуальной среды обратитесь к Python 3 Installation & Setup Guide или Virtual Environments Primer.
С этим давайте перейдем к делу.
Взгляд на Async IO с высоты 10 000 футов
Асинхронный ввод-вывод немного менее известен, чем его проверенные временем кузены, многопроцессорность и поточность. Этот раздел даст вам более полное представление о том, что такое async IO и как он вписывается в окружающий ландшафт.
Где используется Async IO?
Конкурентность и параллелизм - это обширные темы, в которые не так-то просто погрузиться. Хотя эта статья посвящена async IO и его реализации в Python, стоит потратить минуту на сравнение async IO с его аналогами, чтобы иметь представление о том, как async IO вписывается в большую, иногда головокружительную головоломку.
Параллелизм заключается в одновременном выполнении нескольких операций. Мультипроцессинг - это средство для осуществления параллелизма, которое подразумевает распределение задач по центральным процессорам (CPU, или ядрам) компьютера. Мультипроцессинг хорошо подходит для задач, требующих большого количества процессоров: жестко привязанные for циклы и математические вычисления обычно попадают в эту категорию.
Конкурентность - это несколько более широкий термин, чем параллелизм. Он подразумевает, что несколько задач могут выполняться параллельно. (Существует поговорка, что параллелизм не подразумевает параллельности.)
Threading - это модель одновременного выполнения, при которой несколько потоков поочередно выполняют задачи. Один процесс может содержать несколько потоков. У Python сложные отношения с потоками благодаря его GIL, но это выходит за рамки данной статьи.
Важно знать, что потоковая обработка лучше подходит для задач, связанных с вводом-выводом. В то время как для задач с привязкой к процессору характерна постоянная напряженная работа ядер компьютера от начала до конца, для задач с привязкой к IO характерно длительное ожидание завершения ввода/вывода данных.
Кроме того, параллелизм включает в себя как многопроцессорность (идеально подходящую для задач, связанных с процессором), так и многопоточность (подходящую для задач, связанных с вводом-выводом). Мультипроцессинг - это форма параллелизма, а параллелизм - это особый тип (подмножество) параллелизма. Стандартная библиотека Python уже давно поддерживает оба этих вида с помощью своих пакетов multiprocessing, threading и concurrent.futures.
Теперь пришло время добавить нового участника. За последние несколько лет в CPython более полно вошла отдельная конструкция: асинхронный ввод-вывод, реализованный с помощью пакета asyncio стандартной библиотеки и новых ключевых слов языка async и await. Для ясности, асинхронный ввод-вывод не является недавно изобретенной концепцией, и он уже существовал или встраивается в другие языки и среды выполнения, такие как Go, C# или Scala.
В документации к Python пакет asyncio описывается как библиотека для написания параллельного кода. Однако async IO не является ни потоковым, ни многопроцессорным. Он не построен на основе ни того, ни другого.
На самом деле, async IO - это однопоточный, однопроцессный дизайн: он использует кооперативную многозадачность, термин, который вы узнаете к концу этого руководства. Другими словами, async IO дает ощущение параллелизма, несмотря на использование одного потока в одном процессе. Корутины (центральная особенность async IO) можно планировать параллельно, но они не являются параллельными по своей сути.
Повторимся, что async IO - это стиль параллельного программирования, но не параллелизм. Он более близок к потоковому программированию, чем к многопроцессорному, но в значительной степени отличается от них и является самостоятельным членом в мешке трюков параллелизма.
Остается еще один термин. Что значит для чего-то быть асинхронным? Это не строгое определение, но для наших целей я могу назвать два свойства:
- Асинхронные процедуры могут "приостанавливать" выполнение в ожидании конечного результата и позволять другим процедурам работать в это время.
- Асинхронный код, благодаря вышеописанному механизму, облегчает одновременное выполнение. Говоря иначе, асинхронный код придает вид и ощущение параллельности.
Вот диаграмма, позволяющая представить все это вместе. Белые термины обозначают понятия, а зеленые - способы их реализации или действия:
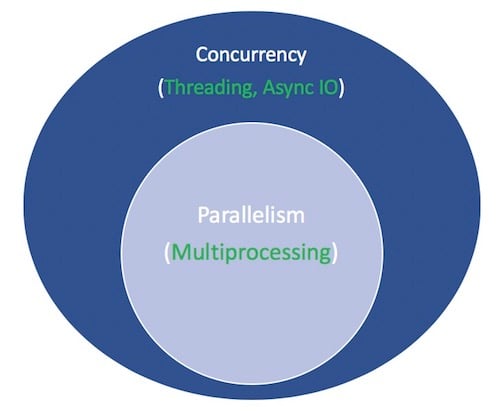
На этом я остановлюсь на сравнениях между моделями параллельного программирования. Этот учебник посвящен такому компоненту, как асинхронный ввод-вывод, его использованию и API, которые возникли вокруг него. Для подробного изучения многопоточности в сравнении с многопроцессорностью в сравнении с async IO, остановитесь здесь и ознакомьтесь с обзором параллелизма в Python Джима Андерсона. Джим намного смешнее меня и, кроме того, он участвовал в большем количестве совещаний, чем я.
Async IO Explained
Синхронный ввод-вывод поначалу может показаться нелогичным и парадоксальным. Как то, что облегчает выполнение параллельного кода, может использовать один поток и одно ядро процессора? У меня никогда не получалось придумывать примеры, поэтому я хотел бы перефразировать один из них из доклада Мигеля Гринберга на 2017 год PyCon, который объясняет все довольно красиво:
Шахматный мастер Юдит Полгар устраивает шахматную выставку, в которой играет с несколькими любителями. У нее есть два способа проведения выставки: синхронный и асинхронный.
Допущения:
- 24 соперника
- Жюдит делает каждый шахматный ход за 5 секунд
- Противники делают ход за 55 секунд
- В среднем в партиях 30 парных ходов (всего 60 ходов)
Синхронная версия: Юдит играет одну партию за раз, никогда две одновременно, пока партия не будет завершена. Каждая игра занимает (55 + 5) * 30 == 1800 секунд, или 30 минут. Вся выставка занимает 24 * 30 == 720 минут, или 12 часов.
Асинхронная версия: Юдит переходит от стола к столу, делая по одному ходу за каждым столом. Во время ожидания она покидает стол и позволяет сопернику сделать следующий ход. На один ход во всех 24 играх у Юдит уходит 24 * 5 == 120 секунд, или 2 минуты. Теперь вся выставка сократилась до 120 * 30 == 3600 секунд, или всего 1 час. (Источник)
Существует только одна Юдит Польгар, у которой всего две руки и которая сама делает только один ход за раз. Но асинхронная игра сокращает время выставки с 12 часов до одного. Итак, кооперативная многозадачность - это модный способ сказать, что цикл событий программы (подробнее об этом позже) взаимодействует с несколькими задачами, позволяя каждой из них по очереди выполняться в оптимальное время.
Асинхронный ввод-вывод занимает длительные периоды ожидания, в течение которых функции в противном случае блокировались бы, и позволяет другим функциям работать во время этого простоя. (Блокирующая функция фактически запрещает другим функциям работать с момента ее запуска до момента ее возвращения.)
Async IO Is Not Easy
Я слышал, как говорят: "Используйте асинхронный ввод-вывод, когда можете; используйте многопоточность, когда должны". Правда в том, что создание долговечного многопоточного кода может быть трудным и чреватым ошибками. Асинхронный ввод-вывод позволяет избежать некоторых потенциальных проблем, с которыми вы могли бы столкнуться при многопоточном проектировании.
Но это не значит, что асинхронный ввод-вывод в Python - это просто. Имейте в виду: если заглянуть немного ниже уровня поверхности, асинхронное программирование тоже может оказаться сложным! Модель async в Python построена на таких понятиях, как обратные вызовы, события, транспорты, протоколы и будущее - одна только терминология может пугать. А тот факт, что его API постоянно меняется, ничуть не облегчает задачу.
К счастью, asyncio созрел до того момента, когда большинство его функций перестали быть предварительными, а документация получила огромную переработку, и начали появляться качественные ресурсы по этой теме.
Пакет asyncio и async/await
Теперь, когда вы имеете некоторое представление об асинхронном вводе-выводе, давайте изучим его реализацию в Python. Пакет Python asyncio (появился в Python 3.4) и два его ключевых слова, async и await, служат разным целям, но объединяются, чтобы помочь вам объявлять, создавать, выполнять и управлять асинхронным кодом.
Синтаксис async/await и нативные корутины
Слово предостережения: Будьте внимательны к тому, что вы читаете в Интернете. API асинхронного ввода-вывода Python быстро эволюционировал с Python 3.4 до Python 3.7. Некоторые старые шаблоны больше не используются, а некоторые вещи, которые сначала были запрещены, теперь разрешены благодаря новым введениям.
В основе асинхронного ввода-вывода лежат корутины. Корутины - это специализированная версия функции-генератора Python. Давайте начнем с базового определения, а затем будем отталкиваться от него по мере продвижения: coroutine - это функция, которая может приостановить свое выполнение до достижения return, и она может косвенно передать управление другой coroutine на некоторое время.
Позже вы гораздо глубже изучите, как именно традиционный генератор перепрофилируется в корутину. Пока же самый простой способ понять, как работают корутины, - это начать создавать некоторые из них.
Давайте воспользуемся иммерсивным подходом и напишем немного кода async IO. Эта короткая программа является Hello World асинхронного ввода-вывода, но в значительной степени иллюстрирует его основную функциональность:
#!/usr/bin/env python3
# countasync.py
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
import time
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")
При выполнении этого файла обратите внимание на то, что выглядит иначе, чем если бы вы определили функции только с помощью def и time.sleep():
$ python3 countasync.py
One
One
One
Two
Two
Two
countasync.py executed in 1.01 seconds.
Порядок этого вывода - сердце асинхронного ввода-вывода. С каждым из вызовов count() связан один цикл событий, или координатор. Когда каждая задача достигает await asyncio.sleep(1), функция кричит в цикл событий и возвращает ему управление, говоря: "Я буду спать 1 секунду. Иди вперед и позволь за это время сделать еще что-нибудь значимое."
Контраст с синхронной версией:
#!/usr/bin/env python3
# countsync.py
import time
def count():
print("One")
time.sleep(1)
print("Two")
def main():
for _ in range(3):
count()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")
При выполнении происходит небольшое, но критическое изменение порядка и времени выполнения:
$ python3 countsync.py
One
Two
One
Two
One
Two
countsync.py executed in 3.01 seconds.
Хотя использование time.sleep() и asyncio.sleep() может показаться банальным, они используются в качестве заменителей для любых процессов, требующих много времени на ожидание. (Самая обыденная вещь, которую вы можете ждать, - это вызов sleep(), который, по сути, ничего не делает). То есть time.sleep() может представлять любой блокирующий вызов функции, требующий много времени, а asyncio.sleep() используется для обозначения неблокирующего вызова (но который также требует некоторого времени для завершения).
Как вы увидите в следующем разделе, польза от ожидания, включая asyncio.sleep(), заключается в том, что окружающая функция может временно передать управление другой функции, которой проще сделать что-то немедленно. Напротив, time.sleep() или любой другой блокирующий вызов несовместим с асинхронным кодом Python, потому что он остановит все на своем пути на время сна.
Правила Async IO
На данном этапе необходимо дать более формальное определение async, await и создаваемых ими корутинных функций. Этот раздел немного плотный, но освоение async/await имеет большое значение, так что возвращайтесь к нему, если понадобится:
-
Синтаксис
async defвводит либо нативный корутин, либо асинхронный генератор. Выраженияasync withиasync forтакже допустимы, и вы увидите их позже. -
Ключевое слово
awaitпередает управление функцией обратно в цикл событий. (Если Python встречает выражениеawait f()в области видимостиg(), то таким образомawaitговорит циклу событий: "Приостановите выполнениеg(), пока не вернется то, чего я жду - результатf(). А пока займитесь чем-нибудь другим."
В коде этот второй пункт выглядит примерно так:
async def g():
# Pause here and come back to g() when f() is ready
r = await f()
return r
Также существует строгий набор правил о том, когда и как можно и нельзя использовать async/await. Они могут быть полезны, если вы только начинаете осваивать синтаксис или уже знакомы с использованием async/await:
-
Функция, которую вы вводите с помощью
async def, является корутиной. Она может использоватьawait,returnилиyield, но все они необязательны. Объявлениеasync def noop(): passявляется допустимым:-
Использование
awaitи/илиreturnсоздает коретиновую функцию. Для вызова коревой функции необходимоawaitее вызвать, чтобы получить ее результаты. -
Реже (и только недавно в Python) используется
yieldв блокеasync def. Это создает асинхронный генератор, который вы итерируете с помощьюasync for. Забудьте на время об асинхронных генераторах и сосредоточьтесь на изучении синтаксиса для функций-коротин, которые используютawaitи/илиreturn. -
Все, что определено с помощью
async def, не может использоватьyield from, что приведет к возникновениюSyntaxError.
-
-
Точно так же, как
SyntaxErrorиспользоватьyieldвнеdefфункции, так жеSyntaxErrorиспользоватьawaitвнеasync defкорутины. Вы можете использоватьawaitтолько в теле коретинов.
Вот несколько кратких примеров, призванных обобщить несколько вышеупомянутых правил:
async def f(x):
y = await z(x) # OK - `await` and `return` allowed in coroutines
return y
async def g(x):
yield x # OK - this is an async generator
async def m(x):
yield from gen(x) # No - SyntaxError
def m(x):
y = await z(x) # Still no - SyntaxError (no `async def` here)
return y
Наконец, когда вы используете await f(), требуется, чтобы f() был объектом, который является ожидаемым. Ну, это не очень полезно, не так ли? Пока просто знайте, что ожидаемый объект - это либо (1) другой корутин, либо (2) объект, определяющий метод .__await__(), который возвращает итератор. Если вы пишете программу, то в большинстве случаев вам нужно беспокоиться только о случае №1.
Это подводит нас к еще одному техническому различию, которое вы можете увидеть: старый способ обозначить функцию как корутину заключается в том, чтобы украсить обычную функцию def функцией @asyncio.coroutine. В результате получается генераторная корутина. Эта конструкция устарела с тех пор, как в Python 3.5 был введен синтаксис async/await.
Эти две корутины по сути эквивалентны (обе ожидаемы), но первая основана на генераторе, а вторая является нативной корутиной:
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine, older syntax"""
yield from stuff()
async def py35_coro():
"""Native coroutine, modern syntax"""
await stuff()
Если вы пишете код самостоятельно, отдайте предпочтение нативным корутинам, чтобы быть явным, а не неявным. Корутины на основе генераторов будут удалены в Python 3.10.
Во второй половине этого урока мы коснемся корутинов на основе генераторов только для пояснения. Причина, по которой были введены async/await, заключается в том, чтобы сделать coroutines отдельной особенностью Python, которую можно легко отличить от обычной функции-генератора, что уменьшает двусмысленность.
Не увязайте в генераторных корутинах, которые были намеренно устаревшими в async/await. У них есть свой небольшой набор правил (например, await не может быть использован в генераторной корутине), которые в основном не имеют значения, если вы придерживаетесь синтаксиса async/await.
Без лишних слов, давайте рассмотрим несколько более сложных примеров.
Вот один из примеров того, как асинхронный ввод-вывод сокращает время ожидания: дана коротина makerandom(), которая продолжает выдавать случайные целые числа в диапазоне [0, 10], пока одно из них не превысит порог, и вы хотите, чтобы несколько последовательных вызовов этой коротины не ждали завершения друг друга. Вы можете в основном следовать шаблонам двух приведенных выше сценариев с небольшими изменениями:
#!/usr/bin/env python3
# rand.py
import asyncio
import random
# ANSI colors
c = (
"\033[0m", # End of color
"\033[36m", # Cyan
"\033[91m", # Red
"\033[35m", # Magenta
)
async def makerandom(idx: int, threshold: int = 6) -> int:
print(c[idx + 1] + f"Initiated makerandom({idx}).")
i = random.randint(0, 10)
while i <= threshold:
print(c[idx + 1] + f"makerandom({idx}) == {i} too low; retrying.")
await asyncio.sleep(idx + 1)
i = random.randint(0, 10)
print(c[idx + 1] + f"---> Finished: makerandom({idx}) == {i}" + c[0])
return i
async def main():
res = await asyncio.gather(*(makerandom(i, 10 - i - 1) for i in range(3)))
return res
if __name__ == "__main__":
random.seed(444)
r1, r2, r3 = asyncio.run(main())
print()
print(f"r1: {r1}, r2: {r2}, r3: {r3}")
Цветной вывод говорит гораздо больше, чем я могу, и дает вам представление о том, как выполняется этот сценарий:

Выполнение rand.py
Эта программа использует одну главную корутину, makerandom(), и запускает ее одновременно на 3 разных входа. Большинство программ содержат небольшие модульные корутины и одну функцию-обертку, которая служит для объединения в цепочку всех небольших корутин. main() затем используется для сбора задач (фьючерсов) путем отображения центральной коретины на некоторую итерируемую переменную или пул.
В этом миниатюрном примере пул - это range(3). В более полном примере, представленном позже, это набор URL, которые нужно запрашивать, разбирать и обрабатывать одновременно, и main() инкапсулирует всю эту рутину для каждого URL.
Хотя "создание случайных целых чисел" (которое больше всего привязано к процессору), возможно, не самый лучший выбор в качестве кандидата для asyncio, присутствие asyncio.sleep() в примере призвано имитировать процесс, связанный с IO, где есть неопределенное время ожидания. Например, вызов asyncio.sleep() может представлять собой отправку и получение не совсем случайных целых чисел между двумя клиентами в приложении для работы с сообщениями.
Паттерны проектирования асинхронного ввода-вывода
Async IO имеет свой собственный набор возможных конструкций сценариев, с которыми вы познакомитесь в этом разделе.
Цепочки корутинов
Ключевой особенностью coroutines является то, что их можно объединять в цепочки. (Помните, что объект coroutine является ожидаемым, поэтому другая coroutine может await его выполнить). Это позволяет разбивать программы на более мелкие, управляемые, перерабатываемые корутины:
#!/usr/bin/env python3
# chained.py
import asyncio
import random
import time
async def part1(n: int) -> str:
i = random.randint(0, 10)
print(f"part1({n}) sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-1"
print(f"Returning part1({n}) == {result}.")
return result
async def part2(n: int, arg: str) -> str:
i = random.randint(0, 10)
print(f"part2{n, arg} sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-2 derived from {arg}"
print(f"Returning part2{n, arg} == {result}.")
return result
async def chain(n: int) -> None:
start = time.perf_counter()
p1 = await part1(n)
p2 = await part2(n, p1)
end = time.perf_counter() - start
print(f"-->Chained result{n} => {p2} (took {end:0.2f} seconds).")
async def main(*args):
await asyncio.gather(*(chain(n) for n in args))
if __name__ == "__main__":
import sys
random.seed(444)
args = [1, 2, 3] if len(sys.argv) == 1 else map(int, sys.argv[1:])
start = time.perf_counter()
asyncio.run(main(*args))
end = time.perf_counter() - start
print(f"Program finished in {end:0.2f} seconds.")
Обратите внимание на вывод, где part1() спит в течение переменного количества времени, а part2() начинает работать с результатами по мере их поступления:
$ python3 chained.py 9 6 3
part1(9) sleeping for 4 seconds.
part1(6) sleeping for 4 seconds.
part1(3) sleeping for 0 seconds.
Returning part1(3) == result3-1.
part2(3, 'result3-1') sleeping for 4 seconds.
Returning part1(9) == result9-1.
part2(9, 'result9-1') sleeping for 7 seconds.
Returning part1(6) == result6-1.
part2(6, 'result6-1') sleeping for 4 seconds.
Returning part2(3, 'result3-1') == result3-2 derived from result3-1.
-->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds).
Returning part2(6, 'result6-1') == result6-2 derived from result6-1.
-->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds).
Returning part2(9, 'result9-1') == result9-2 derived from result9-1.
-->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds).
Program finished in 11.01 seconds.
При такой настройке время выполнения main() будет равно максимальному времени выполнения задач, которые он собирает вместе и планирует.
Использование очереди
Пакет asyncio предоставляет классы queue, которые разработаны так, чтобы быть похожими на классы модуля queue. В наших примерах до сих пор у нас не было необходимости в структуре очереди. В chained.py каждая задача (будущее) состоит из набора короутинов, которые явно ожидают друг друга и передают один вход на цепочку.
Существует альтернативная структура, которая также может работать с async IO: несколько производителей, которые не связаны друг с другом, добавляют элементы в очередь. Каждый производитель может добавлять в очередь несколько элементов в разное, случайное, необъявленное время. Группа потребителей извлекает элементы из очереди по мере их появления, жадно и не дожидаясь никаких других сигналов.
В этом проекте нет никакой цепочки между отдельным потребителем и производителем. Потребители не знают заранее ни количества производителей, ни даже суммарного количества элементов, которые будут добавлены в очередь.
Одному производителю или потребителю требуется переменное количество времени, чтобы поместить и извлечь элементы из очереди, соответственно. Очередь служит в качестве пропускной способности, которая может взаимодействовать с производителями и потребителями без их непосредственного общения друг с другом.
Примечание: Хотя очереди часто используются в многопоточных программах из-за потокобезопасности queue.Queue(), вы не должны беспокоиться о потокобезопасности, когда речь идет об асинхронном вводе-выводе. (Исключение составляют случаи, когда вы совмещаете эти два вида операций, но в данном учебнике это не делается)
Одним из вариантов использования очередей (как в данном случае) является то, что очередь выступает в качестве передатчика для производителей и потребителей, которые в противном случае не связаны друг с другом напрямую.
Синхронная версия этой программы выглядела бы довольно удручающе: группа блокирующих производителей последовательно добавляет элементы в очередь, по одному производителю за раз. Только после того, как все производители закончили, очередь может быть обработана одним потребителем, обрабатывающим элемент за элементом. При таком дизайне существует огромное количество задержек. Предметы могут простаивать в очереди, а не быть немедленно взятыми и обработанными.
Асинхронная версия, приведена asyncq.py ниже. Сложность этого рабочего процесса заключается в том, что необходимо подать сигнал потребителям о том, что производство завершено. В противном случае await q.get() будет висеть бесконечно долго, потому что очередь будет полностью обработана, но потребители не будут иметь представления о том, что производство завершено.
(Большое спасибо за помощь от пользователя StackOverflow, который помог разобраться с main(): ключевым моментом является await q.join(), который блокирует выполнение, пока все элементы в очереди не будут получены и обработаны, а затем отменяет задачи-потребители, которые в противном случае будут висеть и бесконечно ждать появления дополнительных элементов очереди)
Вот полный текст скрипта:
#!/usr/bin/env python3
# asyncq.py
import asyncio
import itertools as it
import os
import random
import time
async def makeitem(size: int = 5) -> str:
return os.urandom(size).hex()
async def randsleep(caller=None) -> None:
i = random.randint(0, 10)
if caller:
print(f"{caller} sleeping for {i} seconds.")
await asyncio.sleep(i)
async def produce(name: int, q: asyncio.Queue) -> None:
n = random.randint(0, 10)
for _ in it.repeat(None, n): # Synchronous loop for each single producer
await randsleep(caller=f"Producer {name}")
i = await makeitem()
t = time.perf_counter()
await q.put((i, t))
print(f"Producer {name} added <{i}> to queue.")
async def consume(name: int, q: asyncio.Queue) -> None:
while True:
await randsleep(caller=f"Consumer {name}")
i, t = await q.get()
now = time.perf_counter()
print(f"Consumer {name} got element <{i}>"
f" in {now-t:0.5f} seconds.")
q.task_done()
async def main(nprod: int, ncon: int):
q = asyncio.Queue()
producers = [asyncio.create_task(produce(n, q)) for n in range(nprod)]
consumers = [asyncio.create_task(consume(n, q)) for n in range(ncon)]
await asyncio.gather(*producers)
await q.join() # Implicitly awaits consumers, too
for c in consumers:
c.cancel()
if __name__ == "__main__":
import argparse
random.seed(444)
parser = argparse.ArgumentParser()
parser.add_argument("-p", "--nprod", type=int, default=5)
parser.add_argument("-c", "--ncon", type=int, default=10)
ns = parser.parse_args()
start = time.perf_counter()
asyncio.run(main(**ns.__dict__))
elapsed = time.perf_counter() - start
print(f"Program completed in {elapsed:0.5f} seconds.")
Первые несколько корутинов - это вспомогательные функции, которые возвращают случайную строку, счетчик производительности за доли секунды и случайное целое число. Производитель помещает в очередь от 1 до 5 элементов. Каждый элемент представляет собой кортеж (i, t), где i - случайная строка, а t - время, в которое производитель пытается поместить кортеж в очередь.
Когда потребитель извлекает элемент, он просто вычисляет прошедшее время, в течение которого элемент находился в очереди, используя временную метку, с которой элемент был помещен в очередь.
Помните, что asyncio.sleep() используется для имитации другой, более сложной корутины, которая бы съедала время и блокировала все остальные выполнения, если бы это была обычная блокирующая функция.
Вот тестовый вариант с двумя производителями и пятью потребителями:
$ python3 asyncq.py -p 2 -c 5
Producer 0 sleeping for 3 seconds.
Producer 1 sleeping for 3 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 sleeping for 3 seconds.
Consumer 3 sleeping for 5 seconds.
Consumer 4 sleeping for 4 seconds.
Producer 0 added <377b1e8f82> to queue.
Producer 0 sleeping for 5 seconds.
Producer 1 added <413b8802f8> to queue.
Consumer 1 got element <377b1e8f82> in 0.00013 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 got element <413b8802f8> in 0.00009 seconds.
Consumer 2 sleeping for 4 seconds.
Producer 0 added <06c055b3ab> to queue.
Producer 0 sleeping for 1 seconds.
Consumer 0 got element <06c055b3ab> in 0.00021 seconds.
Consumer 0 sleeping for 4 seconds.
Producer 0 added <17a8613276> to queue.
Consumer 4 got element <17a8613276> in 0.00022 seconds.
Consumer 4 sleeping for 5 seconds.
Program completed in 9.00954 seconds.
В этом случае элементы обрабатываются за доли секунды. Задержка может быть вызвана двумя причинами:
- Стандартные, в основном неизбежные накладные расходы
- Ситуации, когда все потребители спят, когда элемент появляется в очереди
Что касается второй причины, то, к счастью, масштабирование до сотен или тысяч потребителей - совершенно нормальное явление. У вас не должно быть проблем с python3 asyncq.py -p 5 -c 100. Дело в том, что теоретически вы можете иметь разных пользователей на разных системах, контролирующих управление производителями и потребителями, а очередь будет служить центральным пропускным устройством.
До сих пор вы были брошены прямо в огонь и видели три связанных примера asyncio, вызывающих корутины, определенные с помощью async и await. Если вы не совсем понимаете или просто хотите глубже разобраться в том, как появились современные корутины в Python, начните с самого начала в следующем разделе.
Корни асинхронного ввода-вывода в генераторах
Ранее вы видели пример корутинов старого типа, основанных на генераторах, которые были вытеснены более явными нативными корутинами. Этот пример стоит показать заново с небольшими изменениями:
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine"""
# No need to build these yourself, but be aware of what they are
s = yield from stuff()
return s
async def py35_coro():
"""Native coroutine, modern syntax"""
s = await stuff()
return s
async def stuff():
return 0x10, 0x20, 0x30
В качестве эксперимента, что произойдет, если вызвать py34_coro() или py35_coro() самостоятельно, без await, или без каких-либо вызовов asyncio.run() или других asyncio "фарфоровых" функций? Вызов корутины в изоляции возвращает объект корутины:
>>> py35_coro()
<coroutine object py35_coro at 0x10126dcc8>
На первый взгляд это не очень интересно. Результатом самостоятельного вызова корутины является ожидаемый объект корутины.
Пришло время викторины: какая еще функция Python выглядит так? (Какая функция Python на самом деле не "делает много", когда вызывается сама по себе?)
Надеемся, что в качестве ответа на этот вопрос вы думаете о генераторах, потому что coroutines - это усовершенствованные генераторы под капотом. Их поведение схоже в этом отношении:
>>> def gen():
... yield 0x10, 0x20, 0x30
...
>>> g = gen()
>>> g # Nothing much happens - need to iterate with `.__next__()`
<generator object gen at 0x1012705e8>
>>> next(g)
(16, 32, 48)
Так получилось, что функции-генераторы являются основой асинхронного ввода-вывода (независимо от того, объявляете ли вы короутины с помощью async def, а не с помощью более старой обертки @asyncio.coroutine). Технически await является более близким аналогом yield from, чем yield. (Но помните, что yield from x() - это просто синтаксический сахар для замены for i in x(): yield i.)
Одной из важнейших особенностей генераторов, относящихся к асинхронному вводу-выводу, является то, что их можно останавливать и запускать по своему усмотрению. Например, вы можете break прекратить итерацию над объектом генератора, а затем возобновить итерацию над оставшимися значениями позже. Когда функция генератора достигает yield, она выдает это значение, но затем сидит без дела, пока ей не прикажут выдать следующее значение.
Это можно пояснить на примере:
>>> from itertools import cycle
>>> def endless():
... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever"""
... yield from cycle((9, 8, 7, 6))
>>> e = endless()
>>> total = 0
>>> for i in e:
... if total < 30:
... print(i, end=" ")
... total += i
... else:
... print()
... # Pause execution. We can resume later.
... break
9 8 7 6 9 8 7 6 9 8 7 6 9 8
>>> # Resume
>>> next(e), next(e), next(e)
(6, 9, 8)
Ключевое слово await ведет себя аналогично, отмечая точку прерывания, в которой корутина приостанавливает свою работу и позволяет работать другим корутинам. "Приостановлена" в данном случае означает, что корутина временно передала управление, но не полностью вышла или завершила работу. Помните, что yield и, соответственно, yield from и await отмечают точку прерывания в выполнении генератора.
В этом заключается фундаментальное различие между функциями и генераторами. Функция работает по принципу "все или ничего". Начав работу, она не остановится, пока не достигнет значения return, а затем передаст это значение вызывающей функции (функции, которая ее вызывает). Генератор, с другой стороны, приостанавливается каждый раз при попадании на yield и не идет дальше. Он не только может переместить это значение в стек вызова, но и сохранить свои локальные переменные, когда вы возобновите его, вызвав next().
Есть и вторая, менее известная особенность генераторов, которая также имеет значение. Вы можете отправить значение в генератор также через его метод .send(). Это позволяет генераторам (и корутинам) вызывать (await) друг друга без блокировки. Я не буду углубляться в детали этой функции, потому что она важна в основном для кулуарной реализации коротинов, но вам вряд ли когда-нибудь понадобится использовать ее напрямую.
Если вам интересно узнать больше, вы можете начать с PEP 342, где были официально представлены корутины. Также стоит прочитать статью Бретта Кэннона How the Heck Does Async-Await Work in Python, а также PYMOTW writingup on asyncio. И наконец, есть книга Дэвида Бизли "Любопытный курс по короутинам и параллелизму", в которой подробно рассматривается механизм работы короутинов.
Попробуем сжать все вышесказанное в несколько предложений: существует особенно нетрадиционный механизм, с помощью которого эти coroutines действительно запускаются. Их результат - это атрибут объекта исключения, который выбрасывается при вызове их метода .send(). Есть еще несколько странных деталей, но они, вероятно, не помогут вам использовать эту часть языка на практике, так что давайте пока продолжим.
Чтобы связать все воедино, вот несколько ключевых моментов по теме coroutines как генераторов:
-
Корутины - это переработанные генераторы, использующие особенности методов генератора.
-
Старые генераторные корутины используют
yield fromдля ожидания результата корутины. Современный синтаксис Python в собственных корутинах просто заменяетyield fromнаawaitв качестве средства ожидания результата корутины.awaitаналогиченyield from, и это часто помогает думать о нем именно так. -
Использование
await- это сигнал, отмечающий точку прерывания. Он позволяет корутине временно приостановить выполнение и разрешает программе вернуться к ней позже.
Другие возможности: async for и Async-генераторы + понимания
Наряду с обычными async/await, Python также позволяет async for выполнять итерацию по асинхронному итератору. Назначение асинхронного итератора заключается в том, что он может вызывать асинхронный код на каждом этапе итерации.
Естественным расширением этой концепции является асинхронный генератор. Вспомните, что вы можете использовать await, return или yield в нативной коретине. Использование yield внутри корутины стало возможным в Python 3.6 (через PEP 525), в котором появились асинхронные генераторы, позволяющие использовать await и yield в одном теле корутинной функции:
>>> async def mygen(u: int = 10):
... """Yield powers of 2."""
... i = 0
... while i < u:
... yield 2 ** i
... i += 1
... await asyncio.sleep(0.1)
И наконец, Python позволяет асинхронное понимание с помощью async for. Как и его синхронный собрат, это в основном синтаксический сахар:
>>> async def main():
... # This does *not* introduce concurrent execution
... # It is meant to show syntax only
... g = [i async for i in mygen()]
... f = [j async for j in mygen() if not (j // 3 % 5)]
... return g, f
...
>>> g, f = asyncio.run(main())
>>> g
[1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
>>> f
[1, 2, 16, 32, 256, 512]
Это очень важное различие: ни асинхронные генераторы, ни осмысления не делают итерацию одновременной. Все, что они делают, - это обеспечивают внешний вид и ощущение своих синхронных аналогов, но с возможностью для рассматриваемого цикла передать управление событийному циклу для выполнения какой-либо другой корутины.
Другими словами, асинхронные итераторы и асинхронные генераторы не предназначены для одновременного отображения некоторой функции на последовательность или итератор. Они просто предназначены для того, чтобы вложенный корутин позволил другим задачам занять свою очередь. Утверждения async for и async with нужны только в той степени, в какой использование обычных for или with "нарушит" природу await в корутине. Это различие между асинхронностью и параллелизмом является ключевым для понимания.
Петля событий и asyncio.run()
Вы можете думать о цикле событий как о чем-то вроде цикла while True, который следит за корутинами, получая информацию о том, что простаивает, и ищет, что можно выполнить в это время. Он способен разбудить простаивающую корутину, когда становится доступным то, чего эта корутина ожидает.
До сих пор все управление циклом событий неявно осуществлялось одним вызовом функции:
asyncio.run(main()) # Python 3.7+
asyncio.run(), появившийся в Python 3.7, отвечает за получение цикла событий, выполнение задач до тех пор, пока они не будут помечены как завершенные, а затем закрытие цикла событий.
Существует более долгий способ управления циклом событий asyncio с помощью get_event_loop(). Типичная схема выглядит следующим образом:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.close()
Вы, вероятно, увидите loop.get_event_loop() в старых примерах, но если у вас нет особой необходимости в тонкой настройке управления циклом событий, asyncio.run() должно быть достаточно для большинства программ.
Если вам нужно взаимодействовать с циклом событий в программе на Python - это loop старый добрый объект Python, который поддерживает интроспекцию с помощью loop.is_running() и loop.is_closed(). Вы можете манипулировать им, если вам нужно получить более тонкий контроль, например, при планировании обратного вызова, передав цикл в качестве аргумента.
Более важным является понимание механики цикла событий. Вот несколько моментов, которые стоит подчеркнуть в связи с петлей событий.
#1: Корутины сами по себе мало что делают, пока их не привяжут к циклу событий.
Вы уже видели этот момент в объяснении по генераторам, но его стоит повторить. Если у вас есть главная корутина, которая ожидает других, простой вызов ее в изоляции мало что даст:
>>> import asyncio
>>> async def main():
... print("Hello ...")
... await asyncio.sleep(1)
... print("World!")
>>> routine = main()
>>> routine
<coroutine object main at 0x1027a6150>
Не забудьте использовать asyncio.run() для принудительного выполнения, запланировав main() coroutine (объект будущего) для выполнения в цикле событий:
>>> asyncio.run(routine)
Hello ...
World!
(С помощью await можно выполнять другие корутины. Типично обернуть только main() в asyncio.run(), и оттуда будут вызываться цепочки коротин с await.)
#2: По умолчанию цикл событий async IO выполняется в одном потоке и на одном ядре процессора. Обычно одного однопоточного цикла событий на одном ядре процессора более чем достаточно. Также можно запускать циклы событий на нескольких ядрах. Посмотрите эту беседу Джона Риза, чтобы узнать больше, и будьте предупреждены, что ваш ноутбук может самопроизвольно сгореть.
#3. Циклы событий являются подключаемыми. То есть при желании вы можете написать свою собственную реализацию цикла событий, и она будет выполнять задания точно так же. Это прекрасно продемонстрировано в пакете uvloop, который представляет собой реализацию цикла событий на языке Cython.
Вот что подразумевается под термином "подключаемый цикл событий": вы можете использовать любую рабочую реализацию цикла событий, не связанную со структурой самих короутинов. Сам пакет asyncio поставляется с двумя различными реализациями цикла событий, причем по умолчанию он основан на модуле selectors. (Вторая реализация создана только для Windows.)
Полная программа: Асинхронные запросы
Вы прошли этот путь, и теперь настало время для самой веселой и безболезненной части. В этом разделе вы создадите сборщик URL-адресов для веб-скрейпинга areq.py, используя aiohttp, потрясающе быстрый асинхронный фреймворк HTTP-клиента/сервера. (Нам нужна только клиентская часть). Такой инструмент можно использовать для отображения связей между кластером сайтов, при этом ссылки образуют направленный граф.
Примечание: Вам может быть интересно, почему пакет Python requests не совместим с async IO. Пакет requests построен поверх пакета urllib3, который, в свою очередь, использует модули Python http и socket.
По умолчанию операции с сокетами блокируются. Это означает, что Python не понравится await requests.get(url), потому что .get() не является ожидаемым. В отличие от этого, почти все в aiohttp является ожидаемым корутином, например session.request() и response.text(). В остальном это отличный пакет, но вы окажете себе плохую услугу, если будете использовать requests в асинхронном коде.
Структура программы высокого уровня будет выглядеть следующим образом:
-
Считывание последовательности URL-адресов из локального файла,
urls.txt. -
Отправьте GET-запросы к URL и декодируйте полученное содержимое. Если это не удается, остановитесь на URL.
-
Найдите URL в тегах
hrefв HTML ответов. -
Запишите результаты в
foundurls.txt. -
Выполняйте все вышеперечисленные действия как можно более асинхронно и одновременно. (Используйте
aiohttpдля запросов иaiofilesдля добавления файлов. Это два основных примера ввода-вывода, которые хорошо подходят для модели асинхронного ввода-вывода.)
Вот содержимое urls.txt. Он не очень большой и содержит в основном сайты с высоким трафиком:
$ cat urls.txt
https://regex101.com/
https://docs.python.org/3/this-url-will-404.html
https://www.nytimes.com/guides/
https://www.mediamatters.org/
https://1.1.1.1/
https://www.politico.com/tipsheets/morning-money
https://www.bloomberg.com/markets/economics
https://www.ietf.org/rfc/rfc2616.txt
Второй URL в списке должен вернуть ответ 404, с которым вам нужно будет справиться изящно. Если вы используете расширенную версию этой программы, вам, вероятно, придется решать проблемы гораздо более серьезные, чем эта, такие как отключение сервера и бесконечные перенаправления.
Сами запросы должны выполняться с помощью одной сессии, чтобы использовать преимущества повторного использования внутреннего пула соединений сессии.
Давайте посмотрим на полную программу. Далее мы будем действовать шаг за шагом:
#!/usr/bin/env python3
# areq.py
"""Asynchronously get links embedded in multiple pages' HMTL."""
import asyncio
import logging
import re
import sys
from typing import IO
import urllib.error
import urllib.parse
import aiofiles
import aiohttp
from aiohttp import ClientSession
logging.basicConfig(
format="%(asctime)s %(levelname)s:%(name)s: %(message)s",
level=logging.DEBUG,
datefmt="%H:%M:%S",
stream=sys.stderr,
)
logger = logging.getLogger("areq")
logging.getLogger("chardet.charsetprober").disabled = True
HREF_RE = re.compile(r'href="(.*?)"')
async def fetch_html(url: str, session: ClientSession, **kwargs) -> str:
"""GET request wrapper to fetch page HTML.
kwargs are passed to `session.request()`.
"""
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()
logger.info("Got response [%s] for URL: %s", resp.status, url)
html = await resp.text()
return html
async def parse(url: str, session: ClientSession, **kwargs) -> set:
"""Find HREFs in the HTML of `url`."""
found = set()
try:
html = await fetch_html(url=url, session=session, **kwargs)
except (
aiohttp.ClientError,
aiohttp.http_exceptions.HttpProcessingError,
) as e:
logger.error(
"aiohttp exception for %s [%s]: %s",
url,
getattr(e, "status", None),
getattr(e, "message", None),
)
return found
except Exception as e:
logger.exception(
"Non-aiohttp exception occured: %s", getattr(e, "__dict__", {})
)
return found
else:
for link in HREF_RE.findall(html):
try:
abslink = urllib.parse.urljoin(url, link)
except (urllib.error.URLError, ValueError):
logger.exception("Error parsing URL: %s", link)
pass
else:
found.add(abslink)
logger.info("Found %d links for %s", len(found), url)
return found
async def write_one(file: IO, url: str, **kwargs) -> None:
"""Write the found HREFs from `url` to `file`."""
res = await parse(url=url, **kwargs)
if not res:
return None
async with aiofiles.open(file, "a") as f:
for p in res:
await f.write(f"{url}\t{p}\n")
logger.info("Wrote results for source URL: %s", url)
async def bulk_crawl_and_write(file: IO, urls: set, **kwargs) -> None:
"""Crawl & write concurrently to `file` for multiple `urls`."""
async with ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
write_one(file=file, url=url, session=session, **kwargs)
)
await asyncio.gather(*tasks)
if __name__ == "__main__":
import pathlib
import sys
assert sys.version_info >= (3, 7), "Script requires Python 3.7+."
here = pathlib.Path(__file__).parent
with open(here.joinpath("urls.txt")) as infile:
urls = set(map(str.strip, infile))
outpath = here.joinpath("foundurls.txt")
with open(outpath, "w") as outfile:
outfile.write("source_url\tparsed_url\n")
asyncio.run(bulk_crawl_and_write(file=outpath, urls=urls))
Этот сценарий длиннее, чем наши начальные программы-игрушки, так что давайте разобьем его на части.
Константа HREF_RE - это регулярное выражение для извлечения того, что мы ищем, href тегов в HTML:
>>> HREF_RE.search('Go to <a href="https://realpython.com/">Real Python</a>')
<re.Match object; span=(15, 45), match='href="https://realpython.com/"'>
Корутин fetch_html() представляет собой обертку вокруг GET-запроса для выполнения запроса и декодирования полученной страницы HTML. Она выполняет запрос, ожидает ответа и сразу же поднимает его в случае статуса не-200:
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()
Если статус в порядке, fetch_html() возвращает HTML страницы (символ str). Примечательно, что в этой функции не происходит обработки исключений. Логика заключается в том, чтобы передать исключение вызывающей стороне и позволить ей обработать его там:
html = await resp.text()
Мы await session.request() и resp.text(), потому что это ожидаемые корутины. Цикл запроса/ответа в противном случае был бы длинной, отнимающей время частью приложения, но с асинхронным IO fetch_html() позволяет циклу событий работать над другими легкодоступными заданиями, такими как разбор и запись URL, которые уже были получены.
Далее в цепочке корутинов идет parse(), которая ждет от fetch_html() заданного URL, а затем извлекает все теги href из HTML этой страницы, убеждаясь, что каждый из них валиден, и форматируя их как абсолютный путь.
Признаться, вторая часть parse() является блокирующей, но она состоит из быстрого сопоставления regex и обеспечения того, чтобы обнаруженные ссылки превратились в абсолютные пути.
В данном конкретном случае этот синхронный код должен быть быстрым и незаметным. Но помните, что любая строка внутри данной корутины будет блокировать другие корутины, если только в этой строке не используется yield, await или return. Если парсинг был более интенсивным процессом, вы можете рассмотреть возможность запуска этой части в отдельном процессе с loop.run_in_executor().
Далее корутина write() принимает объект файла и один URL и ждет, пока parse() вернет set разобранных URL, записывая каждый из них в файл асинхронно вместе с исходным URL с помощью aiofiles, пакета для асинхронного файлового ввода-вывода.
Наконец, bulk_crawl_and_write() служит главной точкой входа в цепочку корутинов скрипта. Он использует одну сессию, и для каждого URL, который в конечном итоге считывается из urls.txt, создается задача.
Вот несколько дополнительных моментов, которые заслуживают упоминания:
-
По умолчанию
ClientSessionимеет адаптер с максимальным количеством открытых соединений 100. Чтобы изменить это, передайте экземплярasyncio.connector.TCPConnectorвClientSession. Вы также можете задать ограничения для каждого хоста. -
Вы можете указать максимальный тайм-аут как для сессии в целом, так и для отдельных запросов.
-
В этом скрипте также используется
async with, который работает с асинхронным менеджером контекста. Я не стал посвящать этому понятию целый раздел, потому что переход от синхронных к асинхронным менеджерам контекста довольно прост. Последний должен определять.__aenter__()и.__aexit__(), а не.__exit__()и.__enter__(). Как и следовало ожидать,async withможно использовать только внутри корутинной функции, объявленной с помощьюasync def.
Если вы хотите узнать больше, сопутствующие файлы для этого руководства, размещенные на GitHub, содержат комментарии и документацию.
Вот выполнение во всей красе: areq.py получает, разбирает и сохраняет результаты для 9 URL менее чем за секунду:
$ python3 areq.py
21:33:22 DEBUG:asyncio: Using selector: KqueueSelector
21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/
21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt
21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found
21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/
21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/
21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics
21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/
21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/
21:33:23 INFO:areq: Found 23 links for https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/
Это не так уж плохо! В качестве проверки на вменяемость можно проверить количество строк на выходе. В моем случае оно составляет 626, хотя имейте в виду, что оно может колебаться:
$ wc -l foundurls.txt
626 foundurls.txt
$ head -n 3 foundurls.txt
source_url parsed_url
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/feedback
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/notices/tos
Следующие шаги: Если вы хотите расширить возможности, сделайте этот веб-краулер рекурсивным. Вы можете использовать aio-redis для отслеживания того, какие URL были просмотрены в дереве, чтобы не запрашивать их дважды, и соединять ссылки с помощью библиотеки Python networkx.
Помните, что нужно быть вежливым. Посылать 1000 одновременных запросов на маленький, ничего не подозревающий сайт - это плохо, плохо, плохо. Существуют способы ограничить количество одновременных запросов в одной партии, например, использование sempahore объектов asyncio или использование шаблона , подобного этому. Если вы не прислушаетесь к этому предупреждению, вы можете получить огромную порцию TimeoutError исключений и в итоге только навредите своей программе.
Async IO in Context
Теперь, когда вы познакомились со здоровой порцией кода, давайте отступим на минуту и рассмотрим, когда асинхронный ввод-вывод является идеальным вариантом и как вы можете провести сравнение, чтобы прийти к такому выводу, или выбрать другую модель параллелизма.
Когда и почему Async IO - правильный выбор?
В этом руководстве не место для развернутого трактата об асинхронном вводе-выводе, потоковой обработке и многопроцессорной обработке. Однако полезно иметь представление о том, в каких случаях async IO, вероятно, является лучшим кандидатом из трех.
Битва за асинхронный ввод-вывод и многопроцессорную обработку на самом деле вовсе не битва. На самом деле они могут использоваться совместно. Если у вас есть несколько достаточно однородных задач, связанных с процессором (отличный пример - сетевой поиск в таких библиотеках, как scikit-learn или keras), многопроцессорность должна быть очевидным выбором.
Просто ставить async перед каждой функцией - плохая идея, если все функции используют блокирующие вызовы. (Но, как уже говорилось, есть места, где асинхронный ввод-вывод и многопроцессорная обработка могут жить в гармонии.
Соревнование между асинхронным вводом-выводом и потоковой передачей немного более прямолинейно. Во введении я упомянул, что "потоковая обработка - это сложно". Полная история заключается в том, что даже в тех случаях, когда потоковая обработка кажется простой в реализации, она все равно может привести к печально известным ошибкам, которые невозможно отследить, в том числе из-за условий гонки и использования памяти.
Потоки также имеют тенденцию масштабироваться менее элегантно, чем асинхронный ввод-вывод, потому что потоки - это системный ресурс с ограниченным доступом. Создание тысяч потоков будет неудачным на многих машинах, и я не рекомендую пытаться это делать. Создание тысяч задач асинхронного ввода-вывода вполне осуществимо.
Асинхронный ввод-вывод дает преимущества, когда у вас есть несколько задач, связанных с вводом-выводом, в которых иначе доминировало бы блокирующее время ожидания, связанное с вводом-выводом, например:
-
Сетевой ввод-вывод, независимо от того, является ли ваша программа сервером или клиентом
-
Бессерверные проекты, например одноранговые многопользовательские сети, такие как групповой чат
-
Операции чтения/записи, когда необходимо имитировать стиль "выкинуть и забыть", но при этом не беспокоиться об удержании блокировки на том, что вы читаете и записываете
Самая большая причина не использовать его заключается в том, что await поддерживает только определенный набор объектов, определяющих определенный набор методов. Если вы хотите выполнять операции асинхронного чтения с определенной СУБД, вам придется найти не просто Python-обертку для этой СУБД, а такую, которая поддерживает синтаксис async/await. Корутины, содержащие синхронные вызовы, блокируют выполнение других корутин и задач.
Список библиотек, которые работают с async/await, приведен в списке в конце этого руководства.
Async IO есть, но какой?
Этот учебник посвящен асинхронному IO, синтаксису async/await, а также использованию asyncio для управления циклами событий и задания задач. asyncio, конечно, не единственная библиотека асинхронного ввода-вывода. Это замечание Натаниэля Дж. Смита говорит о многом:
[Через несколько лет
asyncioможет оказаться, что она станет одной из тех библиотек stdlib, которых избегают опытные разработчики, напримерurllib2....
По сути, я утверждаю, что
asyncioявляется жертвой собственного успеха: когда она была разработана, в ней использовался лучший из возможных подходов; но с тех пор работа, вдохновленнаяasyncio- например, добавлениеasync/await- изменила ландшафт так, что мы можем сделать еще лучше, и теперьasyncioсдерживается своими прежними обязательствами. (Источник)
В связи с этим несколько известных альтернатив, которые делают то же самое, что и asyncio, хотя и с разными API и разными подходами, - это curio и trio. Лично я считаю, что если вы создаете умеренную по размеру, простую программу, то использование asyncio вполне достаточно и понятно, и позволяет избежать добавления еще одной большой зависимости за пределами стандартной библиотеки Python.
Но, конечно, ознакомьтесь с curio и trio, и вы можете обнаружить, что они делают то же самое более интуитивно понятным для вас способом. Многие из представленных здесь концепций, не зависящих от пакетов, должны распространяться и на альтернативные пакеты асинхронного ввода-вывода.
Достижения и результаты
В следующих нескольких разделах вы рассмотрите некоторые различные части asyncio и async/await, которые до сих пор не вписывались в рамки учебника, но все же важны для построения и понимания полноценной программы.
Другие функции верхнего уровня asyncio
Помимо asyncio.run(), вы видели несколько других функций пакетного уровня, таких как asyncio.create_task() и asyncio.gather().
Для планирования выполнения объекта coroutine можно использовать create_task(), а затем asyncio.run():
>>> import asyncio
>>> async def coro(seq) -> list:
... """'IO' wait time is proportional to the max element."""
... await asyncio.sleep(max(seq))
... return list(reversed(seq))
...
>>> async def main():
... # This is a bit redundant in the case of one task
... # We could use `await coro([3, 2, 1])` on its own
... t = asyncio.create_task(coro([3, 2, 1])) # Python 3.7+
... await t
... print(f't: type {type(t)}')
... print(f't done: {t.done()}')
...
>>> t = asyncio.run(main())
t: type <class '_asyncio.Task'>
t done: True
В этом шаблоне есть одна тонкость: если не выполнять await t внутри main(), он может завершиться раньше, чем main() сам подаст сигнал о завершении. Поскольку asyncio.run(main()) вызывает loop.run_until_complete(main()), цикл событий (без присутствия await t) заинтересован только в том, чтобы main() был выполнен, а не в том, чтобы были выполнены задачи, которые создаются внутри main(). Без await t другие задачи цикла будут отменены , возможно, до того, как они будут выполнены. Если вам нужно получить список текущих задач, вы можете использовать asyncio.Task.all_tasks().
Примечание: asyncio.create_task() был введен в Python 3.7. В Python 3.6 и ниже используйте asyncio.ensure_future() вместо create_task().
Отдельно есть asyncio.gather(). Хотя он не делает ничего особенного, gather() предназначен для аккуратного размещения коллекции coroutines (фьючерсов) в одном будущем. В результате она возвращает один объект future, и, если вы выполните await asyncio.gather() и укажете несколько задач или coroutines, вы будете ожидать завершения всех из них. (Это в некоторой степени напоминает queue.join() из нашего предыдущего примера.) Результатом работы gather() будет список результатов по всем входам:
>>> import time
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0])) # Python 3.7+
... print('Start:', time.strftime('%X'))
... a = await asyncio.gather(t, t2)
... print('End:', time.strftime('%X')) # Should be 10 seconds
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
... return a
...
>>> a = asyncio.run(main())
Start: 16:20:11
End: 16:20:21
Both tasks done: True
>>> a
[[1, 2, 3], [0, 5, 10]]
Вы, вероятно, заметили, что gather() ожидает весь набор результатов переданных ему Futures или coroutines. В качестве альтернативы можно выполнить цикл asyncio.as_completed(), чтобы получать задания по мере их выполнения в порядке завершения. Функция возвращает итератор, который выдает задания по мере их завершения. Ниже результат coro([3, 2, 1]) будет доступен до завершения coro([10, 5, 0]), чего нельзя сказать о gather():
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0]))
... print('Start:', time.strftime('%X'))
... for res in asyncio.as_completed((t, t2)):
... compl = await res
... print(f'res: {compl} completed at {time.strftime("%X")}')
... print('End:', time.strftime('%X'))
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
...
>>> a = asyncio.run(main())
Start: 09:49:07
res: [1, 2, 3] completed at 09:49:10
res: [0, 5, 10] completed at 09:49:17
End: 09:49:17
Both tasks done: True
Наконец, вы также можете увидеть asyncio.ensure_future(). Он редко вам понадобится, потому что это API низшего уровня и в значительной степени заменен create_task(), который был представлен позже.
Предшествие await
Хотя они ведут себя примерно одинаково, ключевое слово await имеет значительно более высокий приоритет, чем yield. Это означает, что, поскольку оно более жестко привязано, существует ряд случаев, когда в выражении yield from нужны круглые скобки, которые не требуются в аналогичном выражении await. Для получения дополнительной информации смотрите примеры await выражений из PEP 492.
Заключение
Теперь вы умеете пользоваться async/await и библиотеками, созданными на его основе. Вот краткий обзор того, что вы изучили:
-
Асинхронный ввод-вывод как модель, не зависящая от языка, и способ реализовать параллелизм, позволяя короутинам косвенно взаимодействовать друг с другом
-
Особенности новых ключевых слов Питона
asyncиawait, используемых для обозначения и определения короутинов -
asyncio, пакет Python, предоставляющий API для запуска и управления короутинами
Ресурсы
Особенности версии Python
Асинхронный ввод-вывод в Python развивается стремительно, и бывает трудно уследить за тем, что и когда появилось. Вот список изменений и внедрений в минорные версии Python, связанных с asyncio:
-
3.3: Выражение
yield fromпозволяет делегировать генератор. -
3.4:
asyncioбыл введен в стандартную библиотеку Python с предварительным статусом API. -
3.5:
asyncиawaitстали частью грамматики Python и использовались для обозначения и ожидания на короутинах. Они еще не были зарезервированными ключевыми словами. (Вы все еще могли определять функции или переменные с именамиasyncиawait.) -
3.6: Введены асинхронные генераторы и асинхронные постижения. API
asyncioбыл объявлен стабильным, а не временным. -
3.7:
asyncиawaitстали зарезервированными ключевыми словами. (Их нельзя использовать в качестве идентификаторов.) Они предназначены для замены декоратораasyncio.coroutine().asyncio.run()был введен в пакетasyncio, среди множества других возможностей.
Если вы хотите быть в безопасности (и иметь возможность использовать asyncio.run()), перейдите на Python 3.7 или выше, чтобы получить полный набор возможностей.
Статьи
Вот список дополнительных ресурсов:
- Реальный Python: Ускорьте свою программу на Python с помощью параллелизма
- Real Python: Что такое глобальная блокировка интерпретатора Python?
- CPython:
asyncioпакет source - Python docs: Data model > Coroutines
- TalkPython: Async Techniques and Examples in Python
- Бретт Кэннон: Как работает Async-Await в Python 3.5?
- PYMOTW:
asyncio - A. Джесси Джириу Дэвис и Гвидо ван Россум: A Web Crawler With asyncio Coroutines
- Энди Пирс: The State of Python Coroutines:
yield from - Nathaniel J. Smith: Some Thoughts on Asynchronous API Design in a Post-
async/awaitWorld - Армин Ронахер: Я не понимаю Python's Asyncio
- Энди Балаам: серия о
asyncio(4 поста) - Stack Overflow: Python
asyncio.semaphoreвasync-awaitфункции - Йерай Диас:
В нескольких разделах Python What's New более подробно объясняется мотивация языковых изменений:
- Что нового в Python 3.3 (
yield fromи PEP 380) - Что нового в Python 3.6 (PEP 525 & 530)
От Дэвида Бизли:
- Генератор: Трюки для системных программистов
- Любопытный курс по корутинам и параллелизму
- Генераторы: The Final Frontier
Разговоры на YouTube:
- John Reese - Thinking Outside the GIL with AsyncIO and Multiprocessing - PyCon 2018
- Keynote David Beazley - Topics of Interest (Python Asyncio)
- Дэвид Бизли - Python Concurrency From the Ground Up: LIVE! - PyCon 2015
- Раймонд Хеттингер, ключевой доклад по Concurrency, PyBay 2017
- Размышления о параллелизме, Раймонд Хеттингер, разработчик ядра Python
- Мигель Гринберг Асинхронный Python для начинающих PyCon 2017
- Юрий Селиванов asyncawait и asyncio в Python 3 6 и далее PyCon 2017
- Страх и ожидание в Async: A Savage Journey to the Heart of the Coroutine Dream
- Что такое Async, как он работает и когда его использовать? (PyCon APAC 2014)
Связанные ПЭПы
| PEP | Date Created |
|---|---|
| PEP 342 – Coroutines via Enhanced Generators | 2005-05 |
| PEP 380 – Syntax for Delegating to a Subgenerator | 2009-02 |
| PEP 3153 – Asynchronous IO support | 2011-05 |
| PEP 3156 – Asynchronous IO Support Rebooted: the “asyncio” Module | 2012-12 |
| PEP 492 – Coroutines with async and await syntax | 2015-04 |
| PEP 525 – Asynchronous Generators | 2016-07 |
| PEP 530 – Asynchronous Comprehensions | 2016-09 |
Библиотеки, работающие с async/await
От aio-libs:
aiohttp: Асинхронный HTTP клиент/серверный фреймворкaioredis: Поддержка асинхронного ввода-вывода Redisaiopg: Поддержка Async IO PostgreSQLaiomcache: Async IO memcached clientaiokafka: Async IO Kafka clientaiozmq: Поддержка Async IO ZeroMQaiojobs: Планировщик заданий для управления фоновыми задачамиasync_lru: Простой LRU кэш для асинхронного ввода-вывода
uvloop: Сверхбыстрый асинхронный цикл событий ввода-выводаasyncpg: (Также очень быстрая) поддержка асинхронного ввода-вывода PostgreSQL
От других хозяев:
trio: Более дружелюбныйasyncio, призванный продемонстрировать радикально более простой дизайнaiofiles: Async file IOasks: Async requests-like http libraryasyncio-redis: Поддержка Async IO Redisaioprocessing: Интегрирует модульmultiprocessingсasyncioumongo: Клиент Async IO MongoDBunsync: Unsynchronizeasyncioaiostream: Какitertools, но асинхронный