Моделирование деревьев с помощью SQLAlchemy ORM и Postgres Ltree
Оглавление
- Основа
- Установка
- Определение нашей модели
- Пользование
- Индексация
- Добавить отношения
- Генерирование идентификаторов
- Примеры дальнейшего использования
- Заключение
- Дополнительные ресурсы
Основа
При написании программ вы часто будете сталкиваться с ситуациями, когда дерево является наиболее подходящей структурой данных для работы с иерархическими данными. Хотя в Python отсутствует встроенная реализация деревьев, ее относительно просто реализовать самостоятельно, особенно с помощью сторонних библиотек. В этой заметке я рассмотрю один из подходов к представлению деревьев в Python с использованием SQLAlchemy и типа данных PostgreSQL Ltree.
Напомним, что дерево состоит из узлов, соединенных краями, причем каждый узел имеет один или ноль (узлы корень) родительских узлов и ноль (узлы листья) или более дочерних узлов. В качестве примера, вот дерево, показывающее отношения между различными категориями кошек:
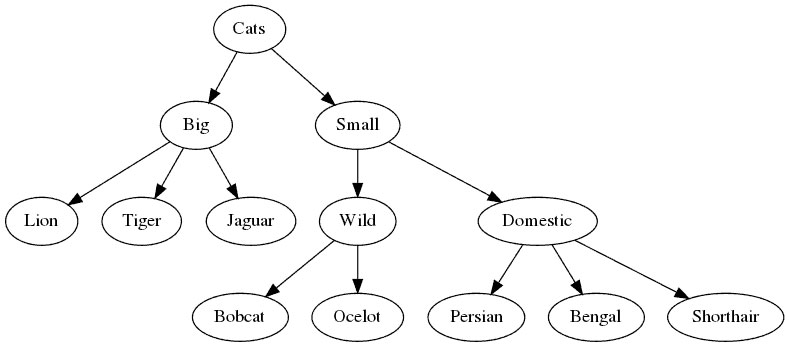
К сожалению, деревья могут быть неудобны для большинства традиционных баз данных SQL. Хотя реляционные базы данных хорошо справляются с выражением связей между различными типами объектов через внешние ключи к другим таблицам, представление вложенных иерархий подобных сущностей обычно требует дополнительной работы и принятия некоторых компромиссов.
Существует множество известных подходов для хранения деревьев в реляционной базе данных. Возможно, наиболее простым является шаблон adjacency list, где каждая строка записывает одно ребро, представленное ссылками на родительский и дочерний узлы. Документация SQLAlchemy содержит пример реализации этого шаблона с помощью объектно-реляционной модели (ORM). Этот метод прост и подходит как для вставки новых узлов, так и для обновления, которое переставляет узлы и их поддеревья. Компромисс заключается в том, что извлечение всего поддерева может быть неэффективным, требующим дорогостоящих рекурсивных запросов.
Другой распространенной техникой является использование шаблона пути materialized, в котором каждый узел хранит запись о пути к нему от корня дерева. Этот подход обеспечивает быструю вставку и быстрые запросы, но перемещение существующего узла в другое дерево может быть медленным и дорогостоящим, поскольку вам придется переписать пути для всех потомков этого узла. К счастью, существует множество рабочих процессов, в которых перемещение узлов редко или невозможно, в то время как добавление новых узлов и получение целых поддеревьев - обычные операции. Представьте себе программное обеспечение для форума, которое отслеживает вложенные деревья комментариев. Пользователи могут добавлять новые комментарии и удалять старые, но приложению никогда не понадобится перемещать или переставлять комментарии.
Если вы используете Postgres в качестве базы данных - вам повезло! Postgres предлагает пользовательский тип данных LTree, специально разработанный для записи материализованных путей для представления деревьев. Ltree - это мощная, гибкая утилита, которая позволяет вашей базе данных эффективно отвечать на такие вопросы, как "Каковы все потомки этого узла?", "Каковы все братья и сестры?", "Каков корень дерева, содержащего этот узел?" и многие другие.
Настройка
Для этого учебника вам потребуется установить следующие библиотеки Python: SQLAlchemy, SQLAlchemy-Utils и привязку psycopg2 Postgres. Ваша индивидуальная ситуация с Python будет отличаться, но я бы предложил создать virtualenv и установить библиотеки туда.
virtualenv .env --python=python3
source .env/bin/activate
pip install sqlalchemy sqlalchemy-utils psycopg2
Вам также понадобится работающий экземпляр PostgreSQL. Этот учебник был написан с использованием Postgres 10, но он также должен работать и на Postgres 9. Если у вас нет Postgres, вы можете обратиться к их документации для получения инструкций по установке, специфичных для вашей операционной системы. Или, если вы предпочитаете, вы можете взять образ docker, Vagrant box или просто подключиться к удаленной установке, запущенной на сервере. Kite также добавил код из этого поста, включая настройку Docker, в свой репозиторий github.
В любом случае, как только Postgres будет запущен, вы можете создать базу данных и роль суперпользователя, подключиться к ней и выполнить CREATE EXTENSION, чтобы убедиться, что расширение Ltree включено:
CREATE EXTENSION IF NOT EXISTS ltree;
Если вы получаете ошибку отказа в разрешении, вашему пользователю базы данных необходимо предоставить права суперпользователя .
Определение нашей модели
После того, как эти предварительные сведения убраны, давайте перейдем к определению базовой модели. Это должно выглядеть довольно знакомо, если вы уже использовали SQLAlchemy ORM:
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
В приведенном выше фрагменте мы объявили, что у нас есть сущность - Node, которая имеет первичный ключ id и обязательное поле name. В реальной жизни у вас может быть любое количество других интересных атрибутов в ваших моделях.
Далее нам нужно добавить способ отслеживания пути между узлами. Для этого мы будем использовать тип столбца Ltree, который доступен как часть библиотеки SQLAlchemy-Utils:
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
Usage
Технически это все, что вам нужно для начала работы. Теперь мы можем создавать узлы, хранить их в базе данных и запрашивать их относительно друг друга. Например:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy_utils import Ltree
engine = create_engine('postgresql://USERNAME:PASSWORD@localhost/MYDATABASE')
# https://docs.sqlalchemy.org/en/latest/core/metadata.html#creating-and-dropping-database-tables
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
cats = Node(name='cats', id=1, path=Ltree('1'))
lions = Node(name='lions', id=2, path=Ltree('1.2'))
tigers = Node(name='tigers', id=3, path=Ltree('1.3'))
bengal_tigers = Node(name='bengal_tigers', id=4, path=Ltree('1.3.4'))
session.add_all([cats, lions, tigers, bengal_tigers])
session.flush()
entire_tree = session.query(Node).filter(Node.path.descendant_of(cats.path)).all()
# [cats, tigers, lions, bengal_tigers]
ancestors = session.query(Node).filter(Node.path.ancestor_of(bengal_tigers.path)).all()
# [cats, tigers, bengal_tigers]
# Let's not persist this yet:
session.rollback()
Хотя это хорошее начало, работать с ним может быть немного неприятно. Нам приходится вручную отслеживать все идентификаторы и пути, нет очевидного способа перехода от одного узла к другому без возвращения к сессии SQLAlchemy и выполнения другого запроса, и на практике эти запросы работают медленно в большой таблице, потому что мы не установили индекс на колонке path Ltree.
Индексация
Отсутствующий индекс легко исправить. Postgres поддерживает несколько типов индексов на столбцах ltree. Если вы просто передадите index=True при определении SQLAlchemy Column(), вы получите индекс B-дерева, который может ускорить простые операции сравнения.
Однако, чтобы в полной мере использовать возможности Ltree, лучше создать индекс GiST. Это может повысить производительность при выполнении более широкого спектра операций запроса, основанных на иерархических отношениях между узлами. Чтобы добавить GiST-индекс в SQLAlchemy, мы можем передать пользовательский Index() в атрибуте __table_args__ нашей модели. Мы добавляем параметр postgres_using='gist' для того, чтобы указать тип индекса
from sqlalchemy import Column, Integer, String
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using="gist"),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
Добавить отношения
Во многих случаях удобно иметь возможность легко получить родительские или дочерние узлы от узла, с которым вы работаете. ORM SQLAlchemy предлагает гибкую конструкцию relationship(), которую можно комбинировать с функцией Ltree subpath() для обеспечения нужного интерфейса.
from sqlalchemy.orm import relationship, remote, foreign
from sqlalchemy import func
from sqlalchemy import Column, Integer, String
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
parent = relationship(
'Node',
primaryjoin=remote(path) == foreign(func.subpath(path, 0, -1)),
backref='children',
viewonly=True,
)
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using="gist"),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
Основная часть этих отношений находится в строке:
primaryjoin=remote(path) == foreign(func.subpath(path, 0, -1)),
Здесь мы говорим SQLAlchemy выдать JOIN для поиска строки, в которой столбец path совпадает с результатом функции Postgres subpath() на столбце path этого узла, который мы рассматриваем как внешний ключ. Вызов subpath(path, 0, -1) запрашивает все метки в пути, кроме последней. Если представить path = Ltree('grandparent.parent.child'), то subpath(path, 0, -1) дает нам Ltree('grandparent.parent'), что как раз то, что нам нужно, если мы ищем путь родительского узла.
Обратная ссылка помогает нам получить Node.children, чтобы идти вместе с Node.parent, а параметр viewonly просто на всякий случай. Как упоминалось выше, манипулирование иерархиями, выраженными в виде материализованных путей, требует перестройки всего дерева, поэтому вы не захотите случайно изменить путь одного узла, используя это отношение.
Генерирование идентификаторов
Вместо того чтобы самим присваивать идентификаторы узлам, гораздо удобнее генерировать их автоматически из автоинкрементной последовательности. Когда вы определяете целочисленный первичный столбец ID в SQLAlchemy, это поведение по умолчанию. К сожалению, этот ID недоступен до тех пор, пока вы не отправите ваш "ожидающий" объект в базу данных. Это создает проблему для нас, поскольку мы также хотели бы включить этот ID в колонку ltree path.
Одним из способов обойти эту проблему является создание метода __init__() для нашего узла, который будет предварительно получать следующее значение ID из последовательности, чтобы его можно было использовать в столбцах id и path. Для этого мы явно определим Sequence(), который будет связан с id. В SQLAlchemy вызов execute() на объекте последовательности приведет к получению следующего значения для последовательности.
from sqlalchemy.orm import relationship, remote, foreign
from sqlalchemy import func
from sqlalchemy import Sequence, create_engine
from sqlalchemy import Column, Integer, String
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
engine = create_engine('postgresql://USER:PASSWORD@localhost/MYDATABASE')
Base = declarative_base()
id_seq = Sequence('nodes_id_seq')
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
id = Column(Integer, id_seq, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
parent = relationship(
'Node',
primaryjoin=remote(path) == foreign(func.subpath(path, 0, -1)),
backref='children',
viewonly=True,
)
def __init__(self, name, parent=None):
_id = engine.execute(id_seq)
self.id = _id
self.name = name
ltree_id = Ltree(str(_id))
self.path = ltree_id if parent is None else parent.path + ltree_id
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using="gist"),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
Обратите внимание, что для того, чтобы это работало, необходимо, чтобы экземпляр движка был подключен к вашей базе данных. К счастью, вызов для получения следующего ID не обязательно должен происходить в контексте сессии SQLAlchemy.
В качестве варианта, другой подход, позволяющий избежать этой упреждающей выборки, заключается в использовании другого типа идентификатора. Например, ключи UUID могут генерироваться вашим приложением - независимо от последовательности базы данных. В качестве альтернативы, если ваши данные имеют хорошие естественные ключи, вы можете использовать их в качестве первичных ключей и в пути Ltree.
Рецепт
Объединив все, что мы обсуждали, и консолидировав некоторые импорты, полный рецепт в итоге выглядит примерно так, как показано ниже. Вы также можете найти полный код, связанный с этим постом (включая инструкции по запуску этого кода в образе Docker!) в репозитории github компании Kite.
from sqlalchemy import Column, Integer, String, Sequence, Index
from sqlalchemy import func, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, remote, foreign
from sqlalchemy_utils import LtreeType, Ltree
Base = declarative_base()
engine = create_engine('postgresql://USER:PASSWORD@localhost/MYDATABASE')
id_seq = Sequence('nodes_id_seq')
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, id_seq, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
parent = relationship(
'Node',
primaryjoin=(remote(path) == foreign(func.subpath(path, 0, -1))),
backref='children',
viewonly=True
)
def __init__(self, name, parent=None):
_id = engine.execute(id_seq)
self.id = _id
self.name = name
ltree_id = Ltree(str(_id))
self.path = ltree_id if parent is None else parent.path + ltree_id
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using='gist'),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
Base.metadata.create_all(engine)
Другие примеры использования
from sqlalchemy import func
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import expression
from sqlalchemy_utils.types.ltree import LQUERY
Session = sessionmaker(bind=engine)
session = Session()
# To create a tree like the example shown
# at the top of this post:
cats = Node('cats')
big = Node('big', parent=cats)
small = Node('small', parent=cats)
wild = Node('wild', parent=small)
domestic = Node('domestic', parent=small)
session.add_all((cats, big, small, wild, domestic))
for big_cat in ('lion', 'tiger', 'jaguar'):
session.add(Node(big_cat, parent=big))
for small_wildcat in ('ocelot', 'bobcat'):
session.add(Node(small_wildcat, parent=wild))
for domestic_cat in ('persian', 'bengal', 'shorthair'):
session.add(Node(domestic_cat, parent=domestic))
session.flush()
# To retrieve a whole subtree:
whole_subtree = session.query(Node).filter(Node.path.descendant_of(domestic.path)).all()
print('Whole subtree:', whole_subtree)
# [domestic, persian, bengal, shorthair]
# Get only the third layer of nodes:
third_layer = session.query(Node).filter(func.nlevel(Node.path) == 3).all()
print('Third layer:', third_layer)
# [wild, domestic, lion, tiger, jaguar]
# Get all the siblings of a node:
shorthair = session.query(Node).filter_by(name="shorthair").one()
siblings = session.query(Node).filter(
# We can use Python's slice notation on ltree paths:
Node.path.descendant_of(shorthair.path[:-1]),
func.nlevel(Node.path) == len(shorthair.path),
Node.id != shorthair.id,
).all()
print('Siblings of shorthair:', siblings)
# [persian, bengal]
# Using an LQuery to get immediate children of two parent nodes at different depths:
query = "*.%s|%s.*{1}" % (big.id, wild.id)
lquery = expression.cast(query, LQUERY)
immediate_children = session.query(Node).filter(Node.path.lquery(lquery)).all()
print('Immediate children of big and wild:', immediate_children)
# [lion, tiger, ocelot, jaguar, bobcat]
Вывод:
Whole subtree: [Node(domestic), Node(persian), Node(bengal), Node(shorthair)]
Third layer: [Node(wild), Node(domestic), Node(lion), Node(tiger), Node(jaguar)]
Siblings of shorthair: [Node(persian), Node(bengal)]
Immediate children of big and wild: [Node(lion), Node(tiger), Node(jaguar), Node(ocelot), Node(bobcat)]
Это лишь несколько примеров. Синтаксис LQuery достаточно гибок, чтобы позволить выполнять самые разнообразные запросы.
Заключение
Иногда нам нужна надежность и зрелость реляционной базы данных, такой как PostgreSQL, но бывает трудно понять, как наши данные отображаются в формат базы данных. Приведенные в этой статье приемы можно использовать для представления данных деревьев в PostgreSQL с помощью элегантного и зрелого типа данных Ltree, удобно представленного через SQLAlchemy ORM. Итак, не стесняйтесь получить некоторую практику, переработав приведенные выше примеры, а также просмотрев некоторые связанные ресурсы!
Вернуться на верх