Строки и символьные данные в Python
Оглавление
В уроке Базовые типы данных в Python вы узнали, как определять строки: объекты, содержащие последовательности символьных данных. Обработка символьных данных является неотъемлемой частью программирования. Редкое приложение обходится без манипуляций со строками, хотя бы в некоторой степени.
Вот что вы узнаете в этом уроке: Python предоставляет богатый набор операторов, функций и методов для работы со строками. По завершении этого урока вы будете знать, как получать доступ к строкам и извлекать из них фрагменты, а также будете знакомы с методами, позволяющими манипулировать строковыми данными и изменять их.
Вы также познакомитесь с двумя другими объектами Python, используемыми для представления необработанных байтовых данных, - типами bytes и bytearray.
Манипулирование строками
В следующих разделах выделены операторы, методы и функции, которые доступны для работы со строками.
Строковые операторы
Вы уже видели, как операторы + и * применяются к числовым операндам в уроке "Операторы и выражения в Python". Эти два оператора можно применить и к строкам.
Оператор +
Оператор + конкатенирует строки. Он возвращает строку, состоящую из операндов, соединенных вместе, как показано здесь:
>>> s = 'foo'
>>> t = 'bar'
>>> u = 'baz'
>>> s + t
'foobar'
>>> s + t + u
'foobarbaz'
>>> print('Go team' + '!!!')
Go team!!!
Оператор *
Оператор * создает несколько копий строки. Если s - строка, а n - целое число, то любое из следующих выражений возвращает строку, состоящую из n конкатенированных копий s:
s * n
n * s
Вот примеры обеих форм:
>>> s = 'foo.'
>>> s * 4
'foo.foo.foo.foo.'
>>> 4 * s
'foo.foo.foo.foo.'
Операнд множителя n должен быть целым числом. Можно подумать, что он должен быть положительным целым числом, но, как ни странно, он может быть нулевым или отрицательным, и в этом случае результатом будет пустая строка:
>>> 'foo' * -8
''
Если бы вы создали строковую переменную и инициализировали ее пустой строкой, присвоив ей значение 'foo' * -8, любой бы справедливо решил, что вы немного глупы. Но это будет работать.
Оператор in
Python также предоставляет оператор членства, который можно использовать со строками. Оператор in возвращает True, если первый операнд содержится во втором, и False в противном случае:
>>> s = 'foo'
>>> s in 'That\'s food for thought.'
True
>>> s in 'That\'s good for now.'
False
Существует также оператор not in, который делает обратное:
>>> 'z' not in 'abc'
True
>>> 'z' not in 'xyz'
False
Встроенные строковые функции
Как вы видели в уроке Основные типы данных в Python, Python предоставляет множество функций, которые встроены в интерпретатор и всегда доступны. Вот несколько из них, которые работают со строками:
| Function | Description |
|---|---|
chr() |
Converts an integer to a character |
ord() |
Converts a character to an integer |
len() |
Returns the length of a string |
str() |
Returns a string representation of an object |
Более подробно они рассмотрены ниже.
ord(c)
Возвращает целое значение для заданного символа.
На самом базовом уровне компьютеры хранят всю информацию в виде чисел. Для представления символьных данных используется схема трансляции, которая сопоставляет каждый символ с представляющим его числом.
Самая простая схема, используемая повсеместно, называется ASCII. Она охватывает распространенные латинские символы, с которыми вам, вероятно, привычнее всего работать. Для этих символов ord(c) возвращает значение ASCII для символа c:
>>> ord('a')
97
>>> ord('#')
35
ASCII - это нормально, насколько это возможно. Но в мире существует множество различных языков и бесчисленное количество символов и глифов, которые появляются в цифровых носителях. Полный набор символов, которые потенциально могут потребоваться для представления в компьютерном коде, намного превосходит обычные латинские буквы, цифры и символы, которые вы обычно видите.
Unicode - это амбициозный стандарт, который пытается предоставить цифровой код для каждого возможного символа, на каждом возможном языке, на каждой возможной платформе. Python 3 широко поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Дополнительная информация: Смотрите Unicode & Character Encodings in Python: A Painless Guide и Python's Unicode Support в документации по Python.
Пока вы остаетесь в области общепринятых символов, практическая разница между ASCII и Unicode невелика. Но функция ord() будет возвращать числовые значения и для символов Unicode:
>>> ord('€')
8364
>>> ord('∑')
8721
chr(n)
Возвращает символьное значение для заданного целого числа.
chr() выполняет обратное действие по отношению к ord(). Если задано числовое значение n, chr(n) возвращает строку, представляющую символ, который соответствует n:
>>> chr(97)
'a'
>>> chr(35)
'#'
chr() также обрабатывает символы Юникода:
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
len(s)
Возвращает длину строки.
С помощью len() можно проверить длину строки Python. len(s) возвращает количество символов в s:
>>> s = 'I am a string.'
>>> len(s)
14
str(obj)
Возвращает строковое представление объекта.
Практически любой объект в Python может быть преобразован в строку. str(obj) возвращает строковое представление объекта obj:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('foo')
'foo'
Индексирование строк
Часто в языках программирования к отдельным элементам упорядоченного набора данных можно получить прямой доступ с помощью числового индекса или значения ключа. Этот процесс называется индексированием.
В Python строки - это упорядоченные последовательности символьных данных, и поэтому их можно индексировать подобным образом. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках ([]).
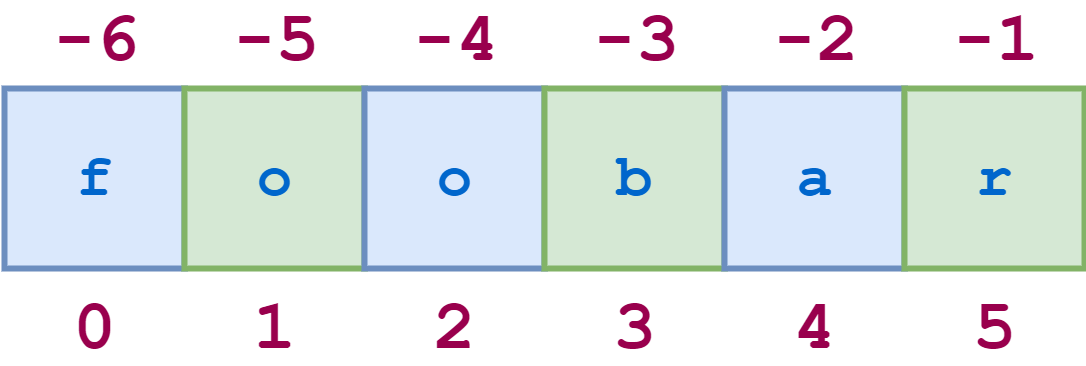
Индексация строк в Python основана на нулях: первый символ в строке имеет индекс 0, следующий - 1 и так далее. Индекс последнего символа будет равен длине строки минус один.
Например, схема индексов строки 'foobar' будет выглядеть так:
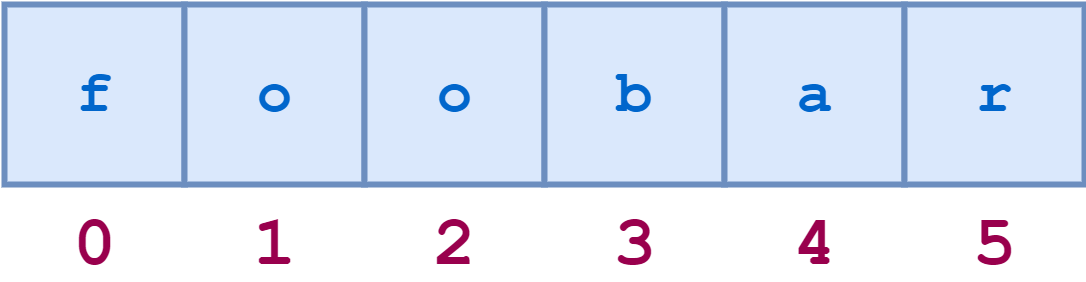
Доступ к отдельным символам по индексу можно получить следующим образом:
>>> s = 'foobar'
>>> s[0]
'f'
>>> s[1]
'o'
>>> s[3]
'b'
>>> len(s)
6
>>> s[len(s)-1]
'r'
Попытка индексировать дальше конца строки приводит к ошибке:
>>> s[6]
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
s[6]
IndexError: string index out of range
Индексы строк также могут быть заданы отрицательными числами, в этом случае индексация происходит от конца строки назад: -1 относится к последнему символу, -2 - к предпоследнему, и так далее. Вот та же диаграмма, показывающая как положительные, так и отрицательные индексы в строке 'foobar':
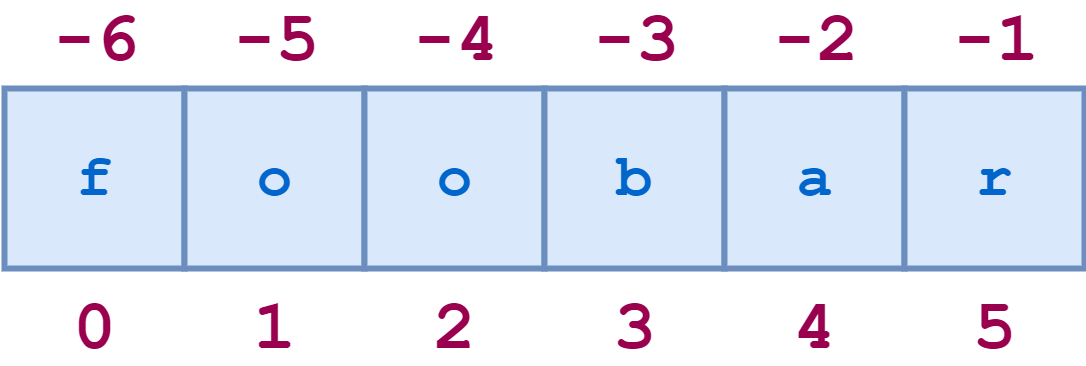
Вот несколько примеров негативного индексирования:
>>> s = 'foobar'
>>> s[-1]
'r'
>>> s[-2]
'a'
>>> len(s)
6
>>> s[-len(s)]
'f'
Попытка индексирования отрицательными числами за пределами начала строки приводит к ошибке:
>>> s[-7]
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
s[-7]
IndexError: string index out of range
Для любой непустой строки s, s[len(s)-1] и s[-1] оба возвращают последний символ. Для пустой строки нет никакого индекса, который имел бы смысл.
Нарезка строк
Python также позволяет использовать синтаксис индексирования, который извлекает подстроки из строки, известный как нарезка строк. Если s - строка, то выражение вида s[m:n] возвращает часть s, начиная с позиции m и до позиции n, но не включая ее:
>>> s = 'foobar'
>>> s[2:5]
'oba'
Помните: Индексы строк основаны на нулях. Первый символ в строке имеет индекс 0. Это относится как к стандартной индексации, так и к нарезке.
Опять же, второй индекс указывает на первый символ, который не включается в результат - символ 'r' (s[5]) в приведенном выше примере. Это может показаться немного неинтуитивным, но в результате получается результат, который имеет смысл: выражение s[m:n] вернет подстроку длиной n - m символов, в данном случае 5 - 2 = 3.
Если опустить первый индекс, то фрагмент начинается с начала строки. Таким образом, s[:m] и s[0:m] эквивалентны:
>>> s = 'foobar'
>>> s[:4]
'foob'
>>> s[0:4]
'foob'
Аналогично, если опустить второй индекс, как в s[n:], то срез простирается от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздким s[n:len(s)]:
>>> s = 'foobar'
>>> s[2:]
'obar'
>>> s[2:len(s)]
'obar'
Для любой строки s и любого целого числа n (0 ≤ n ≤ len(s)), s[:n] + s[n:] будет равно s:
>>> s = 'foobar'
>>> s[:4] + s[4:]
'foobar'
>>> s[:4] + s[4:] == s
True
При передаче обоих индексов возвращается исходная строка целиком. Буквально. Это не копия, а ссылка на исходную строку:
>>> s = 'foobar'
>>> t = s[:]
>>> id(s)
59598496
>>> id(t)
59598496
>>> s is t
True
Если первый индекс в фрагменте больше или равен второму индексу, Python возвращает пустую строку. Это еще один обфусцированный способ генерации пустой строки, если вы его искали:
>>> s[2:2]
''
>>> s[4:2]
''
Отрицательные индексы также можно использовать при нарезке. -1 относится к последнему символу, -2 - к предпоследнему и так далее, как и при простом индексировании. На рисунке ниже показано, как вырезать подстроку 'oob' из строки 'foobar', используя как положительные, так и отрицательные индексы:
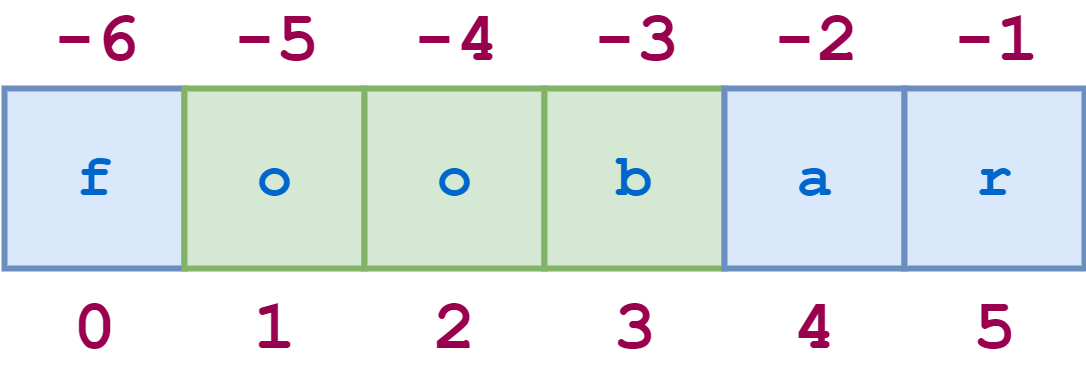
Вот соответствующий код на языке Python:
>>> s = 'foobar'
>>> s[-5:-2]
'oob'
>>> s[1:4]
'oob'
>>> s[-5:-2] == s[1:4]
True
Определение строки в строковом фрагменте
Осталось обсудить еще один вариант синтаксиса нарезки. Добавление дополнительного индекса : и третьего индекса обозначает stride (также называемый шагом), который указывает, на сколько символов нужно перейти после извлечения каждого символа в срезе.
Например, для строки 'foobar' фрагмент 0:6:2 начинается с первого символа и заканчивается последним символом (вся строка), а каждый второй символ пропускается. Это показано на следующей диаграмме: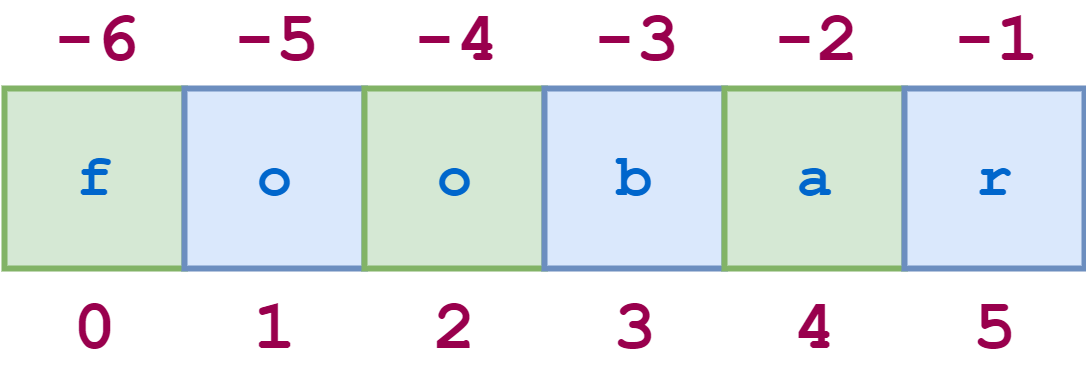
Аналогично, 1:6:2 задает фрагмент, начинающийся со второго символа (индекс 1) и заканчивающийся последним символом, и снова значение stride 2 заставляет пропускать каждый второй символ:
Иллюстративный код REPL показан здесь:
>>> s = 'foobar'
>>> s[0:6:2]
'foa'
>>> s[1:6:2]
'obr'
Как и при любой нарезке, первый и второй индексы могут быть опущены, и по умолчанию используются первый и последний символы соответственно:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::5]
'11111'
>>> s[4::5]
'55555'
Можно указать и отрицательное значение stride, в этом случае Python будет двигаться по строке в обратном направлении. В этом случае начальный/первый индекс должен быть больше конечного/второго индекса:
>>> s = 'foobar'
>>> s[5:0:-2]
'rbo'
В приведенном выше примере 5:0:-2 означает "начать с последнего символа и сделать шаг назад на 2, вплоть
до первого символа, но не включая его".
При шаге назад, если первый и второй индексы опущены, значения по умолчанию меняются на интуитивно понятные: первый индекс по умолчанию соответствует концу строки, а второй - началу. Вот пример:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::-5]
'55555'
Это обычная парадигма для реверсирования строки:
>>> s = 'If Comrade Napoleon says it, it must be right.'
>>> s[::-1]
'.thgir eb tsum ti ,ti syas noelopaN edarmoC fI'
Интерполирование переменных в строку
В версии Python 3.6 был представлен новый механизм форматирования строк. Эта возможность формально называется Литерал форматированной строки, но чаще всего ее называют f-string.
Возможности форматирования, предоставляемые f-строками, весьма обширны, и здесь мы не будем рассматривать их во всех подробностях. Если вы хотите узнать больше, вы можете ознакомиться со статьей Python's F-String for String Interpolation and Formatting. Кроме того, позже в этой серии выйдет учебное пособие по форматированному выводу, в котором мы более подробно рассмотрим f-строки.
Одной из простых возможностей f-строк, которую вы можете начать использовать прямо сейчас, является переменная интерполяция. Вы можете указать имя переменной непосредственно в литерале f-строки, и Python заменит это имя соответствующим значением.
Например, предположим, вы хотите вывести на экран результат арифметического вычисления. Это можно сделать с помощью простого оператора print(), разделяя числовые значения и строковые литералы запятыми:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('The product of', n, 'and', m, 'is', prod)
The product of 20 and 25 is 500
Но это громоздко. То же самое можно сделать с помощью f-строки:
- Укажите строчную
fили прописнуюFнепосредственно перед открывающей кавычкой строкового литерала. Это сообщает Python, что это f-строка, а не обычная строка. - Укажите все переменные, которые будут интерполированы, в фигурных скобках (
{}).
Переделанный с помощью f-строки, приведенный выше пример выглядит гораздо чище:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'The product of {n} and {m} is {prod}')
The product of 20 and 25 is 500
Для определения f-строки можно использовать любой из трех механизмов цитирования Python:
>>> var = 'Bark'
>>> print(f'A dog says {var}!')
A dog says Bark!
>>> print(f"A dog says {var}!")
A dog says Bark!
>>> print(f'''A dog says {var}!''')
A dog says Bark!
Модификация строк
В двух словах: нельзя. Строки - один из типов данных, которые Python считает неизменяемыми, то есть не подлежащими изменению. На самом деле, все типы данных, которые вы видели до сих пор, являются неизменяемыми. (Python предоставляет типы данных, которые являются изменяемыми, как вы скоро увидите.)
Подобное утверждение приведет к ошибке:
>>> s = 'foobar'
>>> s[3] = 'x'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[3] = 'x'
TypeError: 'str' object does not support item assignment
По правде говоря, в модификации строк нет особой необходимости. Обычно вы можете легко добиться желаемого, сгенерировав копию исходной строки с нужными изменениями. В Python существует очень много способов сделать это. Вот один из них:
>>> s = s[:3] + 'x' + s[4:]
>>> s
'fooxar'
Для этого также существует встроенный строковый метод:
>>> s = 'foobar'
>>> s = s.replace('b', 'x')
>>> s
'fooxar'
Читайте далее, чтобы узнать больше о встроенных строковых методах!
Встроенные строковые методы
Вы узнали из урока Переменные в Python, что Python - это в высшей степени объектно-ориентированный язык. Каждый элемент данных в программе на Python является объектом.
Вы также знакомы с функциями: вызываемыми процедурами, которые можно вызывать для выполнения определенных задач.
Методы похожи на функции. Метод - это специализированный тип вызываемой процедуры, тесно связанной с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается на конкретном объекте и имеет сведения о целевом объекте во время выполнения.
Синтаксис для вызова метода на объекте следующий:
obj.foo(<args>)
Это вызывает метод .foo() на объекте obj. <args> задает аргументы, передаваемые методу (если таковые имеются).
Вы узнаете гораздо больше об определении и вызове методов позже, при обсуждении объектно-ориентированного программирования. Пока же мы хотим представить некоторые из наиболее часто используемых встроенных методов, которые Python поддерживает для работы со строковыми объектами.
В следующих определениях методов аргументы, указанные в квадратных скобках ([]), являются необязательными.
Преобразование регистра
Методы этой группы выполняют преобразование регистра в целевой строке.
s.capitalize()
Заглавная буква в целевой строке.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и всеми остальными символами, преобразованными в нижний регистр:
>>> s = 'foO BaR BAZ quX'
>>> s.capitalize()
'Foo bar baz qux'
Неалфавитные символы остаются неизменными:
>>> s = 'foo123#BAR#.'
>>> s.capitalize()
'Foo123#bar#.'
s.lower()
Преобразует алфавитные символы в строчные.
s.lower() возвращает копию s со всеми алфавитными символами, преобразованными в строчные:
>>> 'FOO Bar 123 baz qUX'.lower()
'foo bar 123 baz qux'
s.swapcase()
Меняет регистр буквенных символов.
s.swapcase() возвращает копию s, в которой заглавные символы алфавита преобразованы в строчные и наоборот:
>>> 'FOO Bar 123 baz qUX'.swapcase()
'foo bAR 123 BAZ Qux'
s.title()
Преобразует целевую строку в "регистр заголовка".
s.title() возвращает копию s, в которой первая буква каждого слова переведена в верхний регистр, а остальные буквы - в нижний:
>>> 'the sun also rises'.title()
'The Sun Also Rises'
В этом методе используется довольно простой алгоритм. Он не пытается отличить важные слова от неважных, а также не обрабатывает апострофы, посессивы или акронимы:
>>> "what's happened to ted's IBM stock?".title()
"What'S Happened To Ted'S Ibm Stock?"
s.upper()
Преобразует алфавитные символы в заглавные.
s.upper() возвращает копию s со всеми алфавитными символами, преобразованными в верхний регистр:
>>> 'FOO Bar 123 baz qUX'.upper()
'FOO BAR 123 BAZ QUX'
Поиск и замена
Эти методы предоставляют различные средства для поиска заданной подстроки в целевой строке.
Каждый метод в этой группе поддерживает необязательные аргументы <start> и <end>. Они интерпретируются как для нарезки строк: действие метода ограничивается частью целевой строки, начинающейся с позиции символов <start> и продолжающейся до позиции символов <end>, но не включая ее. Если указано <start>, но не указано <end>, то метод применяется к части целевой строки от <start> до конца строки.
s.count(<sub>[, <start>[, <end>]])
Подсчитывает вхождения подстроки в целевую строку.
s.count(<sub>) возвращает количество непересекающихся вхождений подстроки <sub> в s:
>>> 'foo goo moo'.count('oo')
3
Подсчет ограничивается количеством вхождений в подстроку, указанную <start> и <end>, если они указаны:
>>> 'foo goo moo'.count('oo', 0, 8)
2
s.endswith(<suffix>[, <start>[, <end>]])
Определяет, заканчивается ли целевая строка заданной подстрокой.
s.endswith(<suffix>) возвращает True, если s заканчивается указанным <suffix>, и False в противном случае:
>>> 'foobar'.endswith('bar')
True
>>> 'foobar'.endswith('baz')
False
Сравнение ограничивается подстрокой, обозначенной <start> и <end>, если они указаны:
>>> 'foobar'.endswith('oob', 0, 4)
True
>>> 'foobar'.endswith('oob', 2, 4)
False
s.find(<sub>[, <start>[, <end>]])
Ищет целевую строку для заданной подстроки.
Вы можете использовать .find(), чтобы проверить, содержит ли строка Python определенную подстроку. s.find(<sub>) возвращает наименьший индекс в s, в котором найдена подстрока <sub>:
>>> 'foo bar foo baz foo qux'.find('foo')
0
Этот метод возвращает -1, если указанная подстрока не найдена:
>>> 'foo bar foo baz foo qux'.find('grault')
-1
Поиск ограничивается подстрокой, указанной <start> и <end>, если они указаны:
>>> 'foo bar foo baz foo qux'.find('foo', 4)
8
>>> 'foo bar foo baz foo qux'.find('foo', 4, 7)
-1
s.index(<sub>[, <start>[, <end>]])
Ищет целевую строку для заданной подстроки.
Этот метод идентичен .find(), за исключением того, что он вызывает исключение, если <sub> не найден, а не возвращает -1:
>>> 'foo bar foo baz foo qux'.index('grault')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'foo bar foo baz foo qux'.index('grault')
ValueError: substring not found
s.rfind(<sub>[, <start>[, <end>]])
Ищет целевую строку для заданной подстроки, начиная с конца.
s.rfind(<sub>) возвращает наибольший индекс в s, в котором найдена подстрока <sub>:
>>> 'foo bar foo baz foo qux'.rfind('foo')
16
Как и в случае с .find(), если подстрока не найдена, возвращается -1:
>>> 'foo bar foo baz foo qux'.rfind('grault')
-1
Поиск ограничивается подстрокой, указанной <start> и <end>, если они указаны:
>>> 'foo bar foo baz foo qux'.rfind('foo', 0, 14)
8
>>> 'foo bar foo baz foo qux'.rfind('foo', 10, 14)
-1
s.rindex(<sub>[, <start>[, <end>]])
Ищет целевую строку для заданной подстроки, начиная с конца.
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение, если <sub> не найден, а не возвращает -1:
>>> 'foo bar foo baz foo qux'.rindex('grault')
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
'foo bar foo baz foo qux'.rindex('grault')
ValueError: substring not found
s.startswith(<prefix>[, <start>[, <end>]])
Определяет, начинается ли целевая строка с заданной подстроки.
При использовании метода Python .startswith(), s.startswith(<suffix>) возвращает True, если s начинается с указанного <suffix> и False в противном случае:
>>> 'foobar'.startswith('foo')
True
>>> 'foobar'.startswith('bar')
False
Сравнение ограничивается подстрокой, обозначенной <start> и <end>, если они указаны:
>>> 'foobar'.startswith('bar', 3)
True
>>> 'foobar'.startswith('bar', 3, 2)
False
Классификация персонажей
Методы этой группы классифицируют строку на основе содержащихся в ней символов.
s.isalnum()
Определяет, состоит ли целевая строка из алфавитно-цифровых символов.
s.isalnum() возвращает True, если s непуст и все его символы являются алфавитно-цифровыми (либо буква, либо цифра), и False в противном случае:
>>> 'abc123'.isalnum()
True
>>> 'abc$123'.isalnum()
False
>>> ''.isalnum()
False
s.isalpha()
Определяет, состоит ли целевая строка из алфавитных символов.
s.isalpha() возвращает True, если s непуст и все его символы алфавитные, и False в противном случае:
>>> 'ABCabc'.isalpha()
True
>>> 'abc123'.isalpha()
False
s.isdigit()
Определяет, состоит ли целевая строка из цифровых символов.
Вы можете использовать метод .isdigit() Python, чтобы проверить, состоит ли ваша строка только из цифр. s.isdigit() возвращает True, если s непуста и все ее символы являются числовыми цифрами, и False в противном случае:
>>> '123'.isdigit()
True
>>> '123abc'.isdigit()
False
s.isidentifier()
Определяет, является ли целевая строка действительным идентификатором Python.
s.isidentifier() возвращает True, если s является допустимым идентификатором Python в соответствии с определением языка, и False в противном случае:
>>> 'foo32'.isidentifier()
True
>>> '32foo'.isidentifier()
False
>>> 'foo$32'.isidentifier()
False
Примечание: .isidentifier() вернет True для строки, которая соответствует ключевому слову на языке Python, даже если на самом деле это не будет действительным идентификатором:
>>> 'and'.isidentifier()
True
Проверить, соответствует ли строка ключевому слову Python, можно с помощью функции iskeyword(), которая содержится в модуле keyword. Один из возможных способов сделать это показан ниже:
>>> from keyword import iskeyword
>>> iskeyword('and')
True
Если вы действительно хотите убедиться, что строка будет служить допустимым идентификатором Python, вам следует проверить, что .isidentifier() является True и что iskeyword() является False.
См. Python Modules and Packages-An Introduction, чтобы узнать больше о модулях Python.
s.islower()
Определяет, являются ли алфавитные символы целевой строки строчными.
s.islower() возвращает True, если s непуст и все содержащиеся в нем алфавитные символы являются строчными, и False в противном случае. Неалфавитные символы игнорируются:
>>> 'abc'.islower()
True
>>> 'abc1$d'.islower()
True
>>> 'Abc1$D'.islower()
False
s.isprintable()
Определяет, состоит ли целевая строка полностью из печатаемых символов.
s.isprintable() возвращает True, если s пуст или все содержащиеся в нем алфавитные символы являются печатными. Возвращается False, если s содержит хотя бы один непечатаемый символ. Неалфавитные символы игнорируются:
>>> 'a\tb'.isprintable()
False
>>> 'a b'.isprintable()
True
>>> ''.isprintable()
True
>>> 'a\nb'.isprintable()
False
Примечание: Это один из двух .isxxxx() методов, который возвращает True, если s - пустая строка. Второй такой метод - .isascii().
s.isspace()
Определяет, состоит ли целевая строка из пробельных символов.
s.isspace() возвращает True, если s непуст и все символы являются пробельными, и False в противном случае.
Наиболее часто встречающимися пробельными символами являются пробел ' ', табуляция '\t' и новая строка '\n':
>>> ' \t \n '.isspace()
True
>>> ' a '.isspace()
False
Однако есть еще несколько ASCII-символов, которые считаются пробелами, а если учесть символы Юникода, то и больше:
>>> '\f\u2005\r'.isspace()
True
('\f' и '\r' - управляющие последовательности для символов ASCII Form Feed и Carriage Return; '\u2005' - управляющая последовательность для Unicode Four-Per-Em Space.)
s.istitle()
Определяет, является ли целевая строка заглавной.
s.istitle() возвращает True, если s непустое, первый алфавитный символ каждого слова - прописной, а все остальные алфавитные символы в каждом слове - строчные. В противном случае возвращается False:
>>> 'This Is A Title'.istitle()
True
>>> 'This is a title'.istitle()
False
>>> 'Give Me The #$#@ Ball!'.istitle()
True
Примечание: Вот как описывается .istitle() в документации Python, на случай, если вам это покажется более интуитивным: "Прописные символы могут следовать только за символами без кавычек, а строчные - только за кавычками."
s.isupper()
Определяет, являются ли алфавитные символы целевой строки прописными.
s.isupper() возвращает True, если s непуст и все содержащиеся в нем алфавитные символы прописные, и False в противном случае. Неалфавитные символы игнорируются:
>>> 'ABC'.isupper()
True
>>> 'ABC1$D'.isupper()
True
>>> 'Abc1$D'.isupper()
False
Форматирование строк
Методы этой группы изменяют или улучшают формат строки.
s.center(<width>[, <fill>])
Центрирует строку в поле.
s.center(<width>) возвращает строку, состоящую из s, расположенных по центру в поле шириной <width>. По умолчанию подложка состоит из ASCII-символа пробела:
>>> 'foo'.center(10)
' foo '
Если указан необязательный аргумент <fill>, то он используется в качестве символа подстановки:
>>> 'bar'.center(10, '-')
'---bar----'
Если s уже имеет длину не меньше <width>, он возвращается без изменений:
>>> 'foo'.center(2)
'foo'
s.expandtabs(tabsize=8)
Расширяет табуляции в строке.
s.expandtabs() заменяет каждый символ табуляции ('\t') пробелами. По умолчанию пробелы заполняются, предполагая остановку табуляции в каждом восьмом столбце:
>>> 'a\tb\tc'.expandtabs()
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs()
'aaa bbb c'
tabsize - необязательный ключевой параметр, задающий альтернативные столбцы табуляции:
>>> 'a\tb\tc'.expandtabs(4)
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs(tabsize=4)
'aaa bbb c'
s.ljust(<width>[, <fill>])
Левое выравнивание строки в поле.
s.ljust(<width>) возвращает строку, состоящую из s, выровненных по левому краю в поле шириной <width>. По умолчанию подшивка состоит из ASCII-символа пробела:
>>> 'foo'.ljust(10)
'foo '
Если указан необязательный аргумент <fill>, то он используется в качестве символа подстановки:
>>> 'foo'.ljust(10, '-')
'foo-------'
Если s уже имеет длину не меньше <width>, он возвращается без изменений:
>>> 'foo'.ljust(2)
'foo'
s.lstrip([<chars>])
Обрезает ведущие символы из строки.
s.lstrip() возвращает копию s с удаленными из левого конца символами пробелов:
>>> ' foo bar baz '.lstrip()
'foo bar baz '
>>> '\t\nfoo\t\nbar\t\nbaz'.lstrip()
'foo\t\nbar\t\nbaz'
Если указан необязательный аргумент <chars>, то он представляет собой строку, задающую набор символов, которые необходимо удалить:
>>> 'http://www.realpython.com'.lstrip('/:pth')
'www.realpython.com'
s.replace(<old>, <new>[, <count>])
Заменяет вхождения подстроки в строке.
В Python для удаления символа из строки можно использовать метод Python string .replace(). s.replace(<old>, <new>) возвращает копию s со всеми вхождениями подстроки <old>, замененной на <new>:
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault')
'grault bar grault baz grault qux'
Если указан необязательный аргумент <count>, выполняется максимум <count> замен, начиная с левого конца s:
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault', 2)
'grault bar grault baz foo qux'
s.rjust(<width>[, <fill>])
Правый - выравнивает строку в поле.
s.rjust(<width>) возвращает строку, состоящую из s, выровненных по правому краю в поле шириной <width>. По умолчанию подшивка состоит из ASCII-символа пробела:
>>> 'foo'.rjust(10)
' foo'
Если указан необязательный аргумент <fill>, то он используется в качестве символа подстановки:
>>> 'foo'.rjust(10, '-')
'-------foo'
Если s уже имеет длину не меньше <width>, он возвращается без изменений:
>>> 'foo'.rjust(2)
'foo'
s.rstrip([<chars>])
Обрезает лишние символы в строке.
s.rstrip() возвращает копию s с удаленными с правого конца пробельными символами:
>>> ' foo bar baz '.rstrip()
' foo bar baz'
>>> 'foo\t\nbar\t\nbaz\t\n'.rstrip()
'foo\t\nbar\t\nbaz'
Если указан необязательный аргумент <chars>, то он представляет собой строку, задающую набор символов, которые необходимо удалить:
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
s.strip([<chars>])
Удаляет символы с левого и правого концов строки.
s.strip() по сути эквивалентно последовательному вызову s.lstrip() и s.rstrip(). Без аргумента <chars> она удаляет ведущие и завершающие пробельные символы:
>>> s = ' foo bar baz\t\t\t'
>>> s = s.lstrip()
>>> s = s.rstrip()
>>> s
'foo bar baz'
Как и в случае с .lstrip() и .rstrip(), дополнительный аргумент <chars> задает набор символов, которые будут удалены:
>>> 'www.realpython.com'.strip('w.moc')
'realpython'
Примечание: Когда возвращаемым значением строкового метода является другая строка, как это часто бывает, методы можно вызывать последовательно, выстраивая цепочки вызовов:
>>> ' foo bar baz\t\t\t'.lstrip().rstrip()
'foo bar baz'
>>> ' foo bar baz\t\t\t'.strip()
'foo bar baz'
>>> 'www.realpython.com'.lstrip('w.moc').rstrip('w.moc')
'realpython'
>>> 'www.realpython.com'.strip('w.moc')
'realpython'
s.zfill(<width>)
Заполняет строку слева нулями.
s.zfill(<width>) возвращает копию s, дополненную слева символами '0' до указанных <width>:
>>> '42'.zfill(5)
'00042'
Если s содержит ведущий знак, он остается на левом краю строки результата после вставки нулей:
>>> '+42'.zfill(8)
'+0000042'
>>> '-42'.zfill(8)
'-0000042'
Если s уже имеет длину не меньше <width>, он возвращается без изменений:
>>> '-42'.zfill(3)
'-42'
.zfill() наиболее полезен для строковых представлений чисел, но Python все равно с удовольствием обнулит строку, которая не является:
>>> 'foo'.zfill(6)
'000foo'
Преобразование между строками и списками
Методы этой группы преобразуют строку в некоторый составной тип данных, либо склеивая объекты вместе, чтобы получить строку, либо разбивая строку на части.
Эти методы оперируют или возвращают iterables, общий термин языка Python для последовательной коллекции объектов. Более подробно вы изучите внутреннюю работу итераций в предстоящем уроке по определенной итерации.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих составных типа данных, которые являются прототипическими примерами итераций в Python. Они рассматриваются в следующем уроке, так что вы скоро узнаете о них! А пока просто думайте о них как о последовательностях значений. Список заключен в квадратные скобки ([]), а кортеж - в круглые скобки (()).
После такого вступления давайте рассмотрим последнюю группу строковых методов.
s.join(<iterable>)
Конкатенация строк из итерируемого файла.
s.join(<iterable>) возвращает строку, полученную в результате конкатенации объектов в <iterable>, разделенных s.
Обратите внимание, что .join() вызывается на s, строку-разделитель. <iterable> также должен быть последовательностью строковых объектов.
Некоторые примеры кода должны помочь прояснить ситуацию. В следующем примере разделителем s является строка ', ', а <iterable> - список строковых значений:
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
Результатом является одна строка, состоящая из объектов списка, разделенных запятыми.
В следующем примере <iterable> задается как единственное строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
Таким образом, результатом ':'.join('corge') является строка, состоящая из каждого символа в 'corge', разделенных ':'.
Этот пример не работает, потому что один из объектов в <iterable> не является строкой:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
Однако это можно исправить:
>>> '---'.join(['foo', str(23), 'bar'])
'foo---23---bar'
Как вы скоро увидите, многие составные объекты в Python можно рассматривать как итерабельные, и .join() особенно полезен для создания из них строк.
s.partition(<sep>)
Делит строку на основе разделителя.
s.partition(<sep>) разделяет s на первое вхождение строки <sep>. Возвращаемое значение - кортеж из трех частей, состоящий из:
- Часть
s, предшествующая<sep> <sep>сама- Часть
s, следующая за<sep>
Вот несколько примеров .partition() в действии:
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
Если
Если <sep> не найден в s, возвращаемый кортеж содержит s, за которым следуют две пустые строки:
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
Помните: Списки и кортежи будут рассмотрены в следующем уроке.
s.rpartition(<sep>)
Делит строку на основе разделителя.
s.rpartition(<sep>) функционирует точно так же, как s.partition(<sep>), за исключением того, что s разбивается на последнее вхождение <sep>, а не на первое:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
s.rsplit(sep=None, maxsplit=-1)
Разбивает строку на список подстрок.
Без аргументов s.rsplit() разбивает s на подстроки, разделенные любой последовательностью пробельных символов, и возвращает подстроки в виде списка:
>>> 'foo bar baz qux'.rsplit()
['foo', 'bar', 'baz', 'qux']
>>> 'foo\n\tbar baz\r\fqux'.rsplit()
['foo', 'bar', 'baz', 'qux']
Если указано <sep>, то оно используется в качестве разделителя для разделения:
>>> 'foo.bar.baz.qux'.rsplit(sep='.')
['foo', 'bar', 'baz', 'qux']
(Если <sep> указан со значением None, строка разделяется пробелами, как если бы <sep> вообще не был указан.)
Если в качестве разделителя явно указан <sep>, то последовательные разделители в s считаются разделителями пустых строк, которые будут возвращены:
>>> 'foo...bar'.rsplit(sep='.')
['foo', '', '', 'bar']
Однако это не так, если <sep> опущен. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
>>> 'foo\t\t\tbar'.rsplit()
['foo', 'bar']
Если указан необязательный ключевой параметр <maxsplit>, выполняется максимум столько разбиений, начиная с правого конца s:
>>> 'www.realpython.com'.rsplit(sep='.', maxsplit=1)
['www.realpython', 'com']
По умолчанию для <maxsplit> установлено значение -1, что означает, что должны быть выполнены все возможные разбиения - так же, как если <maxsplit> полностью опущено:
>>> 'www.realpython.com'.rsplit(sep='.', maxsplit=-1)
['www', 'realpython', 'com']
>>> 'www.realpython.com'.rsplit(sep='.')
['www', 'realpython', 'com']
s.split(sep=None, maxsplit=-1)
Разбивает строку на список подстрок.
s.split() ведет себя точно так же, как s.rsplit(), за исключением того, что если указано <maxsplit>, сплиты отсчитываются от левого конца s, а не от правого:
>>> 'www.realpython.com'.split('.', maxsplit=1)
['www', 'realpython.com']
>>> 'www.realpython.com'.rsplit('.', maxsplit=1)
['www.realpython', 'com']
Если <maxsplit> не указан, .split() и .rsplit() неразличимы.
s.splitlines([<keepends>])
Разрывает строку по границам строк.
s.splitlines() разбивает s на строки и возвращает их в виде списка. Любой из следующих символов или последовательностей символов считается границей строки:
| Escape Sequence | Character |
|---|---|
\n |
Новая строка |
\r |
Возврат каретки |
\r\n |
Возврат каретки + перевод строки |
\v or \x0b |
Табуляция строк |
\f or \x0c |
Подача формы |
\x1c |
Разделитель файлов |
\x1d |
Разделитель групп |
\x1e |
Разделитель записей |
\x85 |
Следующая строка (код управления C1) |
\u2028 |
Разделитель строк Unicode |
\u2029 |
Разделитель абзацев Unicode |
Вот пример использования нескольких различных разделителей строк:
>>> 'foo\nbar\r\nbaz\fqux\u2028quux'.splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
Если в строке присутствуют последовательные символы границы строки, предполагается, что они отделяют пустые строки, которые появятся в списке результатов:
>>> 'foo\f\f\fbar'.splitlines()
['foo', '', '', 'bar']
Если указан необязательный аргумент <keepends> и он является истинным, то границы строк сохраняются в результирующих строках:
>>> 'foo\nbar\nbaz\nqux'.splitlines(True)
['foo\n', 'bar\n', 'baz\n', 'qux']
>>> 'foo\nbar\nbaz\nqux'.splitlines(1)
['foo\n', 'bar\n', 'baz\n', 'qux']
bytes Объекты
Объект bytes является одним из основных встроенных типов для манипулирования двоичными данными. Объект bytes представляет собой неизменяемую последовательность одиночных значений байт. Каждый элемент объекта bytes представляет собой небольшое целое число в диапазоне от 0 до 255.
Определение буквального bytes объекта
Литерал bytes определяется так же, как и строковый литерал, с добавлением префикса 'b':
>>> b = b'foo bar baz'
>>> b
b'foo bar baz'
>>> type(b)
<class 'bytes'>
Как и в случае со строками, вы можете использовать любой из механизмов одинарного, двойного или тройного кавычек:
>>> b'Contains embedded "double" quotes'
b'Contains embedded "double" quotes'
>>> b"Contains embedded 'single' quotes"
b"Contains embedded 'single' quotes"
>>> b'''Contains embedded "double" and 'single' quotes'''
b'Contains embedded "double" and \'single\' quotes'
>>> b"""Contains embedded "double" and 'single' quotes"""
b'Contains embedded "double" and \'single\' quotes'
В литерале bytes допускаются только символы ASCII. Любое значение символа, превышающее 127, должно быть указано с помощью соответствующей управляющей последовательности:
>>> b = b'foo\xddbar'
>>> b
b'foo\xddbar'
>>> b[3]
221
>>> int(0xdd)
221
Префикс 'r' может использоваться в литерале bytes для отключения обработки управляющих последовательностей, как в случае со строками:
>>> b = rb'foo\xddbar'
>>> b
b'foo\\xddbar'
>>> b[3]
92
>>> chr(92)
'\\'
Определение bytes объекта с помощью встроенной bytes() функции
Функция bytes() также создает объект bytes. Какой именно объект bytes будет возвращен, зависит от аргумента(ов), переданного(ых) функции. Возможные формы показаны ниже.
bytes(<s>, <encoding>)
Создает объект
bytesиз строки.
bytes(<s>, <encoding>) преобразует строку <s> в объект bytes, используя str.encode() в соответствии с указанными <encoding>:
>>> b = bytes('foo.bar', 'utf8')
>>> b
b'foo.bar'
>>> type(b)
<class 'bytes'>
Техническое примечание: В этой форме функции bytes() требуется аргумент <encoding>. Под "кодировкой" понимается способ перевода символов в целочисленные значения. Значение "utf8" указывает на формат преобразования Юникода UTF-8, который представляет собой кодировку, способную обрабатывать все возможные символы Юникода. UTF-8 также можно указать, указав "UTF8", "utf-8" или "UTF-8" для <encoding>.
Для получения дополнительной информации см. документацию Unicode. Если вы имеете дело с обычными символами на основе латиницы, UTF-8 будет служить вам долго.
bytes(<size>)
Создает объект
bytes, состоящий из нулевых (0x00) байтов.
bytes(<size>) определяет объект bytes заданного <size>, который должен быть положительным целым числом. Результирующий объект bytes инициализируется нулевым (0x00) байтом:
>>> b = bytes(8)
>>> b
b'\x00\x00\x00\x00\x00\x00\x00\x00'
>>> type(b)
<class 'bytes'>
bytes(<iterable>)
Создает объект
bytesиз итерабельного файла.
bytes(<iterable>) определяет объект bytes из последовательности целых чисел, порожденных <iterable>. <iterable> должен быть итерируемым, генерирующим последовательность целых чисел n в диапазоне 0 ≤ n ≤ 255:
>>> b = bytes([100, 102, 104, 106, 108])
>>> b
b'dfhjl'
>>> type(b)
<class 'bytes'>
>>> b[2]
104
Операции над bytes объектами
Как и строки, объекты bytes поддерживают общие операции с последовательностью:
-
Операторы
inиnot in:>>> b = b'abcde' >>> b'cd' in b True >>> b'foo' not in b True -
Операторы конкатенации (
+) и репликации (*):>>> b = b'abcde' >>> b + b'fghi' b'abcdefghi' >>> b * 3 b'abcdeabcdeabcde' -
Индексирование и нарезка:
>>> b = b'abcde' >>> b[2] 99 >>> b[1:3] b'bc' -
Встроенные функции:
>>> len(b) 5 >>> min(b) 97 >>> max(b) 101
Многие методы, определенные для строковых объектов, применимы и для объектов bytes:
>>> b = b'foo,bar,foo,baz,foo,qux'
>>> b.count(b'foo')
3
>>> b.endswith(b'qux')
True
>>> b.find(b'baz')
12
>>> b.split(sep=b',')
[b'foo', b'bar', b'foo', b'baz', b'foo', b'qux']
>>> b.center(30, b'-')
b'---foo,bar,foo,baz,foo,qux----'
Заметьте, однако, что когда эти операторы и методы вызываются на bytes объекте, операнд и аргументы также должны быть bytes объектами:
>>> b = b'foo.bar'
>>> b + '.baz'
Traceback (most recent call last):
File "<pyshell#72>", line 1, in <module>
b + '.baz'
TypeError: can't concat bytes to str
>>> b + b'.baz'
b'foo.bar.baz'
>>> b.split(sep='.')
Traceback (most recent call last):
File "<pyshell#74>", line 1, in <module>
b.split(sep='.')
TypeError: a bytes-like object is required, not 'str'
>>> b.split(sep=b'.')
[b'foo', b'bar']
Хотя определение и представление объекта bytes основано на ASCII-тексте, на самом деле он ведет себя как неизменяемая последовательность небольших целых чисел в диапазоне от 0 до 255 включительно. Вот почему один элемент объекта bytes отображается как целое число:
>>> b = b'foo\xddbar'
>>> b[3]
221
>>> hex(b[3])
'0xdd'
>>> min(b)
97
>>> max(b)
221
Ломтик отображается как объект bytes, даже если его длина составляет всего один байт:
>>> b[2:3]
b'c'
Вы можете преобразовать объект bytes в список целых чисел с помощью встроенной функции list():
>>> list(b)
[97, 98, 99, 100, 101]
Шестнадцатеричные числа часто используются для указания двоичных данных, поскольку две шестнадцатеричные цифры напрямую соответствуют одному байту. Класс bytes поддерживает два дополнительных метода, которые облегчают преобразование в строку шестнадцатеричных цифр и обратно.
bytes.fromhex(<s>)
Возвращает объект
bytes, построенный из строки шестнадцатеричных значений.
bytes.fromhex(<s>) возвращает объект bytes, полученный в результате преобразования каждой пары шестнадцатеричных цифр в <s> в соответствующее значение байта. Пары шестнадцатеричных цифр в <s> по желанию могут быть разделены пробелами, которые игнорируются:
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'\xaahF\x82\xcc'
>>> list(b)
[170, 104, 70, 130, 204]
Примечание: Этот метод является методом класса, а не методом объекта. Он привязан к классу bytes, а не к объекту bytes. Более подробно о различиях между классами, объектами и соответствующими им методами вы узнаете из следующих уроков по объектно-ориентированному программированию. Пока же просто обратите внимание на то, что этот метод вызывается на классе bytes, а не на объекте b.
b.hex()
Возвращает строку шестнадцатеричного значения из объекта
bytes.
b.hex() возвращает результат преобразования bytes объекта b в строку шестнадцатеричных пар цифр. То есть выполняется обратная операция .fromhex():
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'\xaahF\x82\xcc'
>>> b.hex()
'aa684682cc'
>>> type(b.hex())
<class 'str'>
Примечание: В отличие от .fromhex(), .hex() является объектным методом, а не методом класса. Таким образом, он вызывается на объекте класса bytes, а не на самом классе.
bytearray Объекты
Python поддерживает другой тип двоичной последовательности, называемый bytearray. Объекты bytearray очень похожи на объекты bytes, несмотря на некоторые различия:
-
В Python нет специального синтаксиса для определения литерала
bytearray, как и префикса'b', который можно использовать для определения объектаbytes. Объектbytearrayвсегда создается с помощью встроенной функцииbytearray():>>> ba = bytearray('foo.bar.baz', 'UTF-8') >>> ba bytearray(b'foo.bar.baz') >>> bytearray(6) bytearray(b'\x00\x00\x00\x00\x00\x00') >>> bytearray([100, 102, 104, 106, 108]) bytearray(b'dfhjl') - Объекты
bytearrayявляются мутабельными. Вы можете изменять содержимое объектаbytearrayс помощью индексации и нарезки:>>> ba = bytearray('foo.bar.baz', 'UTF-8') >>> ba bytearray(b'foo.bar.baz') >>> ba[5] = 0xee >>> ba bytearray(b'foo.b\xeer.baz') >>> ba[8:11] = b'qux' >>> ba bytearray(b'foo.b\xeer.qux')
Объект bytearray может быть построен непосредственно из объекта bytes, а также:
>>> ba = bytearray(b'foo')
>>> ba
bytearray(b'foo')
Заключение
В этом уроке вы подробно рассмотрели множество различных механизмов, которые предоставляет Python для работы со строками , включая строковые операторы, встроенные функции, индексацию, нарезку и встроенные методы. Вы также познакомились с типами bytes и bytearray.
Эти типы - первые из рассмотренных вами типов, которые собираются из набора более мелких частей. Python предоставляет несколько составных встроенных типов. В следующем уроке вы изучите два наиболее часто используемых: списки и кортежи.
Вернуться на верх