Python + Memcached: Эффективное кэширование в распределенных приложениях
Оглавление
- Установка memcached
- Хранение и извлечение кэшированных значений с помощью Python
- Автоматическое удаление кэшированных данных
- Разогрев холодного кэша
- Проверить и установить
- За пределами кэширования
При написании приложений на Python кэширование играет важную роль. Использование кэша, чтобы избежать повторного вычисления данных или обращения к медленной базе данных, может значительно повысить производительность.
Python предлагает встроенные возможности для кэширования, от простого словаря до более полной структуры данных, такой как functools.lru_cache. Последняя может кэшировать любой элемент, используя алгоритм Least-Recently Used для ограничения размера кэша.
Однако эти структуры данных, по определению, локальны для вашего процесса Python. Когда несколько копий вашего приложения работают на большой платформе, использование структуры данных in-memory не позволяет совместно использовать кэшированное содержимое. Это может быть проблемой для крупномасштабных и распределенных приложений.
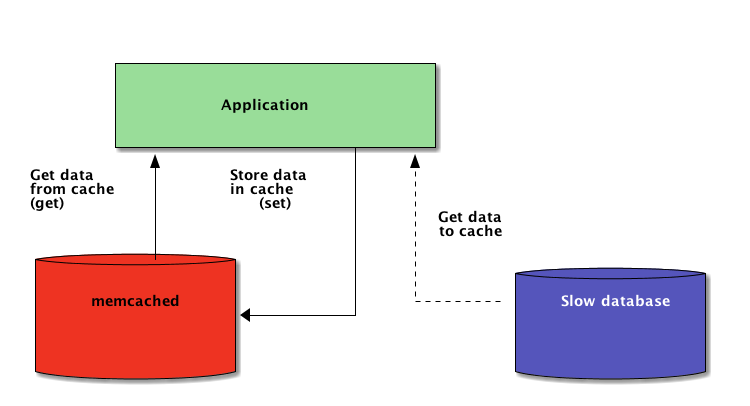
Поэтому, когда система распределена по сети, ей также необходим кэш, распределенный по сети. В настоящее время существует множество сетевых серверов, которые предлагают возможность кэширования - мы уже рассказывали о том, как использовать Redis для кэширования в Django.
Как вы увидите в этом руководстве, memcached - еще один отличный вариант распределенного кэширования. После краткого введения в основы использования memcached вы узнаете о таких продвинутых паттернах, как "cache and set" и использование резервных кэшей для предотвращения проблем с производительностью холодного кэша.
Установка memcached
Memcached доступен для многих платформ:
- Если вы работаете под управлением Linux, вы можете установить его с помощью
apt-get install memcachedилиyum install memcached. В этом случае memcached будет установлен из предварительно собранного пакета, но вы также можете собрать memcached из исходников, как описано здесь. - Для macOS использование Homebrew является самым простым вариантом. Просто запустите
brew install memcachedпосле установки менеджера пакетов Homebrew. - На Windows вам придется компилировать memcached самостоятельно или найти предварительно скомпилированные двоичные файлы.
После установки memcached можно просто запустить, вызвав команду memcached:
$ memcached
Прежде чем вы сможете взаимодействовать с memcached из страны Python, вам нужно будет установить библиотеку memcached client. Как это сделать, вы увидите в следующем разделе, а также некоторые базовые операции доступа к кэшу.
Хранение и получение кэшированных значений с помощью Python
Если вы никогда не использовали memcached, то понять это довольно просто. По сути, он предоставляет гигантский словарь, доступный по сети. У этого словаря есть несколько свойств, которые отличаются от классического словаря Python, в основном:
- Ключи и значения должны быть байтами
- Ключи и значения автоматически удаляются по истечении времени действия
Таким образом, двумя основными операциями взаимодействия с memcached являются set и get. Как вы уже догадались, они используются для присвоения значения ключу или получения значения из ключа, соответственно.
Моей предпочтительной библиотекой Python для взаимодействия с memcached является pymemcache - рекомендую использовать именно ее. Вы можете просто установить ее с помощью pip:
$ pip install pymemcache
Следующий код показывает, как вы можете подключиться к memcached и использовать его в качестве сетевого распределенного кэша в ваших Python-приложениях:
>>> from pymemcache.client import base
# Don't forget to run `memcached' before running this next line:
>>> client = base.Client(('localhost', 11211))
# Once the client is instantiated, you can access the cache:
>>> client.set('some_key', 'some value')
# Retrieve previously set data again:
>>> client.get('some_key')
'some value'
memcached сетевой протокол действительно прост, а его реализация чрезвычайно быстра, что делает его полезным для хранения данных, которые иначе было бы медленно получить из канонического источника данных или вычислить заново:
Хотя этот пример достаточно прост, он позволяет хранить кортежи ключ/значение в сети и получать к ним доступ через несколько распределенных, работающих копий вашего приложения. Это просто, но в то же время мощно. И это отличный первый шаг к оптимизации вашего приложения.
Автоматическое удаление кэшированных данных
При хранении данных в memcached можно установить время истечения срока действия - максимальное количество секунд, в течение которого memcached будет хранить ключ и значение. По истечении этого срока memcached автоматически удаляет ключ из своего кэша.
На какое значение следует установить время кэширования? Не существует магического числа для этой задержки, и оно полностью зависит от типа данных и приложения, с которым вы работаете. Это может быть несколько секунд, а может быть несколько часов.
Анулирование кэша, определяющее, когда следует удалить кэш, поскольку он не синхронизируется с текущими данными, также является тем, с чем придется работать вашему приложению. Особенно если необходимо избежать представления слишком старых данных или старых.
Здесь опять же нет волшебного рецепта; все зависит от типа приложения, которое вы создаете. Тем не менее, есть несколько частных случаев, которые должны быть обработаны, и которые мы еще не рассмотрели в приведенном выше примере.
Кэширующий сервер не может расти бесконечно - память является ограниченным ресурсом. Поэтому ключи будут удаляться кэширующим сервером, как только ему понадобится больше места для хранения других вещей.
Некоторые ключи также могут быть просрочены из-за истечения срока их действия (также иногда называемого "временем жизни" или TTL). В таких случаях данные теряются, и канонический источник данных должен быть запрошен снова.
Это звучит сложнее, чем есть на самом деле. Обычно при работе с memcached в Python можно придерживаться следующей схемы:
from pymemcache.client import base
def do_some_query():
# Replace with actual querying code to a database,
# a remote REST API, etc.
return 42
# Don't forget to run `memcached' before running this code
client = base.Client(('localhost', 11211))
result = client.get('some_key')
if result is None:
# The cache is empty, need to get the value
# from the canonical source:
result = do_some_query()
# Cache the result for next time:
client.set('some_key', result)
# Whether we needed to update the cache or not,
# at this point you can work with the data
# stored in the `result` variable:
print(result)
Примечание: Обработка отсутствующих ключей обязательна из-за нормальных операций смывания. Она также обязательна для обработки сценария холодного кэша, т.е. когда memcached только что запущен только что был запущен. В этом случае кэш будет полностью пуст, и его необходимо полностью заполнить, по одному запросу за раз.
Это означает, что любые кэшированные данные следует рассматривать как эфемерные. И вы никогда не должны ожидать, что кэш будет содержать значение, которое вы ранее записали в него.
Разогрев холодного кэша
Некоторые сценарии холодного кэша невозможно предотвратить, например, сбой memcached. Но некоторые можно, например миграция на новый memcached сервер.
Когда можно предсказать, что произойдет сценарий холодного кэша, лучше его избежать. Кэш, который необходимо пополнять, означает, что внезапно каноническое хранилище кэшированных данных будет массово посещено всеми пользователями кэша, которым не хватает данных кэша (также известная как проблема "громящего стада" )
pymemcache предоставляет класс FallbackClient, который помогает реализовать этот сценарий, как показано здесь:
from pymemcache.client import base
from pymemcache import fallback
def do_some_query():
# Replace with actual querying code to a database,
# a remote REST API, etc.
return 42
# Set `ignore_exc=True` so it is possible to shut down
# the old cache before removing its usage from
# the program, if ever necessary.
old_cache = base.Client(('localhost', 11211), ignore_exc=True)
new_cache = base.Client(('localhost', 11212))
client = fallback.FallbackClient((new_cache, old_cache))
result = client.get('some_key')
if result is None:
# The cache is empty, need to get the value
# from the canonical source:
result = do_some_query()
# Cache the result for next time:
client.set('some_key', result)
print(result)
Команда FallbackClient запрашивает старый кэш, переданный в ее конструктор, соблюдая порядок. В этом случае новый кэш-сервер всегда будет запрашиваться первым, а в случае промаха кэша будет запрашиваться старый, что позволит избежать возможного возврата к первичному источнику данных.
Если установлен какой-либо ключ, то он будет установлен только для нового кэша. Через некоторое время старый кэш может быть выведен из эксплуатации и FallbackClient может быть заменен направленным клиентом new_cache.
Проверить и установить
При взаимодействии с удаленным кэшем возвращается обычная проблема конкурентности: несколько клиентов могут пытаться получить доступ к одному и тому же ключу одновременно. memcached предоставляет операцию check and set, сокращенно CAS, которая помогает решить эту проблему.
Простейший пример - приложение, которое хочет подсчитать количество пользователей. Каждый раз, когда посетитель подключается, счетчик увеличивается на 1. Используя memcached, простая реализация будет выглядеть так:
def on_visit(client):
result = client.get('visitors')
if result is None:
result = 1
else:
result += 1
client.set('visitors', result)
Однако что произойдет, если два экземпляра приложения попытаются обновить этот счетчик в одно и то же время?
Первый вызов client.get('visitors') вернет одинаковое количество посетителей для обоих, допустим, 42. Затем оба прибавят 1, вычислят 43 и установят число посетителей равным 43. Это число неверно, и результат должен быть 44, то есть 42 + 1 + 1.
Для решения проблемы параллелизма удобно использовать операцию CAS из memcached. Следующий фрагмент реализует правильное решение:
def on_visit(client):
while True:
result, cas = client.gets('visitors')
if result is None:
result = 1
else:
result += 1
if client.cas('visitors', result, cas):
break
Метод gets возвращает значение, как и метод get, но он также возвращает значение CAS.
То, что находится в этом значении, не имеет значения, но оно используется при следующем вызове метода cas. Этот метод эквивалентен операции set, за исключением того, что он завершается неудачей, если значение изменилось после операции gets. В случае успеха цикл прерывается. В противном случае операция перезапускается с самого начала.
В сценарии, когда два экземпляра приложения пытаются обновить счетчик в одно и то же время, только одному удается переместить счетчик с 42 на 43. Второй экземпляр получает значение False, возвращенное вызовом client.cas, и вынужден повторить цикл. На этот раз он получит в качестве значения 43, увеличит его до 44, и вызов cas завершится успешно, что решит нашу проблему.
Инкрементирование счетчика интересно в качестве примера для объяснения работы CAS, потому что это упрощение. Однако memcached также предоставляет методы incr и decr для увеличения или уменьшения целого числа за один запрос, а не за несколько вызовов gets/cas. В реальных приложениях gets и cas используются для более сложных типов данных или операций
Большинство серверов удаленного кэширования и хранилищ данных предоставляют такой механизм для предотвращения проблем с параллелизмом. Очень важно знать об этих случаях, чтобы правильно использовать их возможности.
За пределами кэширования
Простые приемы, проиллюстрированные в этой статье, показали вам, как легко можно использовать memcached для ускорения работы вашего Python-приложения.
Просто используя две базовые операции "set" и "get", вы часто можете ускорить поиск данных или избежать повторного вычисления результатов снова и снова. С помощью memcached вы можете разделить кэш на большое количество распределенных узлов.
Другие, более сложные паттерны, которые вы видели в этом уроке, например операция Check And Set (CAS), позволяют обновлять данные, хранящиеся в кэше, одновременно в нескольких потоках или процессах Python, избегая при этом повреждения данных.
Если вам интересно узнать больше о продвинутых методах написания более быстрых и масштабируемых приложений на Python, ознакомьтесь с Scaling Python. В ней рассматривается множество продвинутых тем, таких как распределение сети, системы очередей, распределенное хеширование и профилирование кода.
Вернуться на верх