Построение микросервиса в Python
Микросервисы в последние дни были самой горячей темой в технологии, а за микросервисной архитектурой следуют такие технологические гиганты, как Netflix, Twitter, Amazon, Walmart и т.д., а также несколько стартапов. Они идеально подходят для современного гибкого процесса разработки программного обеспечения, где происходят постоянные инновации, а продукты постоянно поставляются. Давайте разберем еще несколько деталей о микросервисах:
Основы микросервисов: что и почему?
По определению:
В микросервисных архитектурах приложения создаются и разворачиваются как простые, сильно разрозненные, сфокусированные сервисы. Они соединяются друг с другом с помощью облегченных механизмов связи, не зависящих от языка, которые часто означают простые API-интерфейсы HTTP и очереди сообщений и являются устойчивыми по своей природе.
Микросервисы могут содержать несколько независимых сервисов, которые создаются для обслуживания только одной конкретной бизнес-функции и обмена данными по упрощенному протоколу, например HTTP. Это несколько похоже на SOA (сервис-ориентированная архитектура), которая часто реализуется внутри монолитов развертывания, приводит к проблеме наличия монореполя. В монолитной архитектуре, которая является крупнейшим конкурентом архитектуры микросервисов, вся бизнес-логика присутствует в одном сервисе, который является чертовски беспорядочным, если речь идет о техническом обслуживании, тестируемости и развертывании.
Преимущества архитектуры:
- Непрерывная интеграция и развертывание (CI/CD). Микросервисы могут управляться группой небольших команд, поскольку они независимы и в значительной степени отделены друг от друга, что позволяет изменять, удалять или добавлять код, не затрагивая другие приложения.
- Независимость от языка программирования и структуры
- Контейнаризация
- Высокая масштабируемость, доступность и устойчивость
Теперь, когда мы собрали несколько базовых концепций микросервиса, давайте узнаем, как мы можем создать такую в python.
Использование Flask Framework - на уровне продакшена

Мы будем использовать Flask в качестве фреймворка вместе с его расширением Flask-Restplus, в котором добавлена поддержка быстрой сборки REST API, который в основном используется для документации Swagger. Простое веб-приложение может быть создано с использованием классов Api Flask и Flask Restplus с определенной конечной точкой, которая разрешается в ресурс маршрута и предоставляет REST API. Ниже приведен пример:
from flask import Flask
from flask_restplus import Resource, Api
app = Flask("app_name")
@app.route('/test')
@api.doc(params={})
class TestApp(Resource):
def get():
return 'Hello, World!'if __name__ == "__main__":
app.run(host=HOSTNAME, debug=True)
Здесь создается приложение, которое просто возвращает строку «Hello, World!» когда сделан запрос get с конечной точкой /test. Когда эта программа запущена, Flask использует встроенный веб-сервер, который будет работать и обслуживать любой запрос на хосте HOSTNAME. Но подождите, вы также увидите следующее сообщение:
WARNING: Do not use the development server in a production environment. Use a production WSGI server instead.
Это означает, что веб-сервер по умолчанию не сможет обрабатывать параллелизм, обслуживать статические файлы и т.п. очень эффективно. Чтобы решить эту проблему, нам нужен готовый к работе веб-сервер, такой как Nginx, и сервер приложений, основанный на протоколе WSGI, например, uWSGI. uWSGI вызывает вызываемый объект Flask, то есть `app` в вышеприведенном примере программы, и может обмениваться данными через HTTP, а также через TCP-соединение на основе Unix-сокета с веб-сервером Nginx. Nginx действует как обратный прокси, кеширует, обслуживает статический контент и т.д.
uwsgi --http :9090 --wsgi-file app.py --master --processes 4 --threads 2
Полезная документация по настройке Nginx с Flask: Официальный Flask и Как обслуживать приложения Flask с помощью uWSGI и Nginx в Ubuntu 18.04.
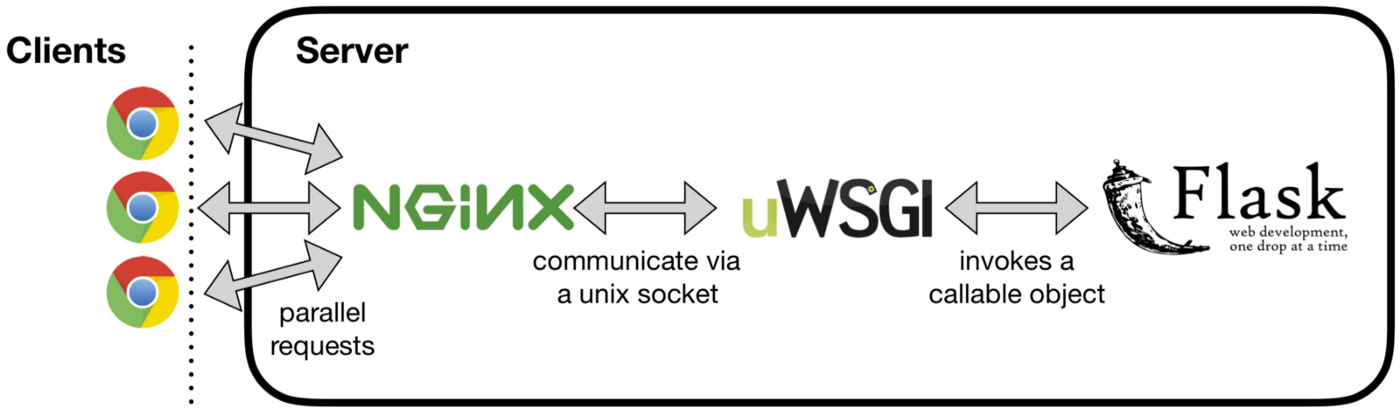
Поток HTTP-запроса от клиентского браузера
Библиотеки Python
Чтобы эффективно выполнять бизнес-логику в среде Flask, нужно лишь несколько библиотек:
1. REQUESTS:
Для того, чтобы прочитать некоторый контент из другого URI с помощью HTTP-запроса, Requests - это все, что нам нужно. Он может выполнять любые HTTP-запросы GET/POST/etc. с надлежащей обработкой таймаута, исключениями и авторизацией. Мы также можем напрямую проанализировать ответ в содержимом объекта JSON. Пример:
import requests
response = requests.get("https://abc.com/def/hello") #простой GET запрос
json_response = response.json() #ответ в формате JSON
2. MARSHMELLOW:
This is a library which helps when serialization/deserialization are needed. For example, in the above requests HTTP call, we want to load the JSON response in a python class. Then, we can load the JSON response directly into a schema which is having post_load decorator which maps the entities into a class. For serializing the class so as to send it over the network, the python can be dumped in a schema. If a particular field should not be displayed in the response on some condition, we have to write a BaseSchema which removes a particular key in response to some condition.
Это библиотека, которая помогает, когда нужны сериализация/десериализация. Например, в приведенном выше запросе HTTP-запроса мы хотим загрузить ответ JSON в классе Python. Затем мы можем загрузить ответ JSON непосредственно в схему с декоратором post_load, который отображает сущности в класс. Для сериализации класса с целью отправки его по сети питон может быть выгружен в схему. Если конкретное поле не должно отображаться в ответе на какое-либо условие, мы должны написать BaseSchema, которая удаляет определенный ключ в ответ на некоторое условие.
3. Кэширование
Кэширование в приложении может быть достигнуто тремя способами в зависимости от варианта использования:
1. Кэширование в памяти [cachetools]: элементы хранятся в динамической памяти приложения. cachetools предоставляет декоратор, поддерживающий алгоритмы кэширования на основе LRU и TTL. В LRU, если кэш заполнен, элемент, который используется совсем недавно, будет отброшен, а в алгоритмах TTL элемент отбрасывается, когда он превышает определенный промежуток времени. Пример:
from cachetools import cached, LRUCache, TTLCache
@cached(cache=LRUCache(maxsize=32)) #item discarded if size exceeds 32 keys
def get_sum(arr):
return sum(arr)@cached(cache=TTLCache(maxsize=1024, ttl=600))
def get_value(key):
return some_fun(key)
2. Кэширование на основе файлов: этот кеш хранит элементы на диске. Класс werkzeug.contrib.cache.FileSystemCache принимает путь к каталогу файлов, в котором элементы будут храниться в системе, порог и время ожидания. Пример:
from werkzeug.contrib.cache import FileSystemCache
fs_cache = FileSystemCache("/tmp", threshold=64, timeout=120)
fs_cache.set(key) # to set a key
3. Memcached Cache [pymemcache]: элементы хранятся в распределенных системах, где элементы могут храниться в большом количестве и иметь доступ с любого хоста. Класс werkzeug.contrib.cache.MemcachedCache принимает кортеж адресов сервера, время ожидания и ключ префикса, если таковые имеются. Pymemcache создан Pinterest, который реализует различные методы хеширования для хранения элементов на сервере.
4. Конкурентность и параллелизм
Конкурентность - это когда две или более задач могут запускаться, работать и завершаться в перекрывающиеся периоды времени, тогда как параллелизм - это когда задачи буквально выполняются одновременно, например, на многоядерном процессоре. Python имеет GIL (глобальную блокировку интерпретатора), которая позволяет только одному потоку контролировать интерпретатор Python. Если программа выполняется на одноядерном компьютере с одним потоком, то влияние не видно разработчикам, но когда она запускается на многоядерной системе, GIL становится узким местом, поскольку только один поток может работать на конкретном ядре, даже другие потоки могут быть запущены параллельно. Программа Python может быть двух типов: связанная с вводом/выводом и связанная с процессором. Связанные с CPU программы требуют значительных вычислений и требуют большей части времени CPU для выполнения инструкций. С другой стороны, процессы, связанные с вводом/выводом, в основном обмениваются данными с устройствами ввода/вывода, такими как диск, внешние накопители, сетевое соединение и т.д., т.е. CPU в течение этого периода не используется.
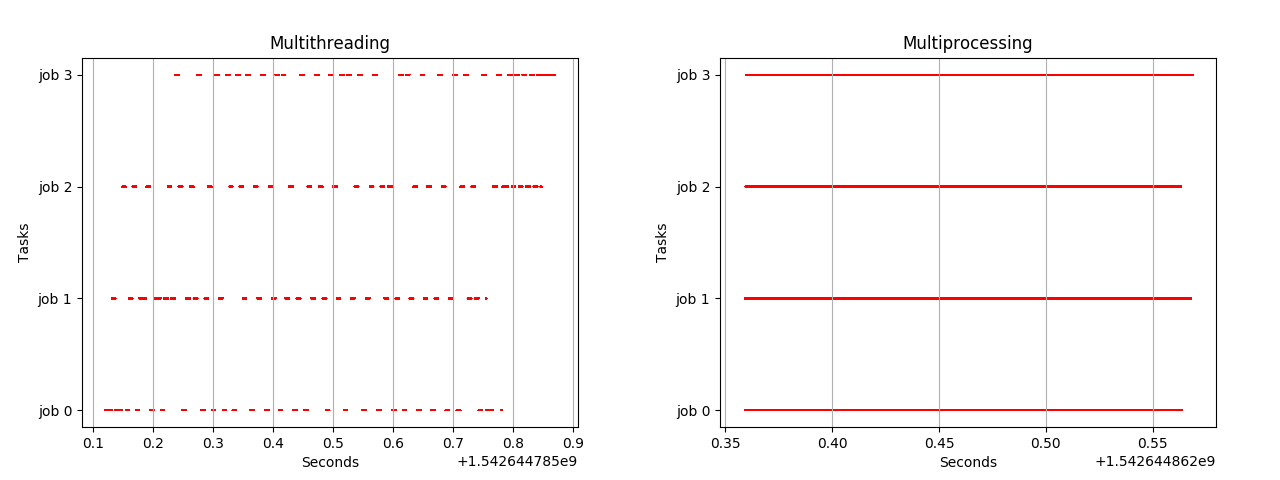 Многопоточность в Python против многопроцессорности
Многопоточность в Python против многопроцессорности
Из приведенного выше рисунка мы заключаем, что из-за GIL программа python запускается на одном ядре за раз, переключаясь с одного ядра на другое, сохраняя блокировку на остальных ядрах. Таким образом, даже имея несколько потоков, работающих на отдельном ядре, мы не можем достичь многопоточности. Итак, лучше выполнять многопоточность в случае процессов, связанных с вводом-выводом, и многопроцессорности для процессов, связанных с процессором. Python 3.7 предоставляет модуль concurrent.futures, который можно использовать для достижения многопроцессорности и многопоточности.
a) concurrent.futures.ThreadPoolExecutor: это следует использовать для программ, связанных с вводом / выводом, таких как сетевые вызовы. Он создает пул потоков, где определенное количество воркеров должно быть определено. Пример ниже взят из официальной документации для иллюстрации:
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
Здесь делается четыре HTTP-запроса, что, очевидно, является операцией ввода-вывода, поэтому лучше всего применять многопоточность. Создано пять воркеров, 4 запроса load_url будут отправлены одновременно. Процессор продолжает изменять контекст из одного потока в другой, позволяя буферизовать данные во время выполнения других потоков. Метод as_completed предоставляет будущий порядок, в котором обработка завершена. result() дает вывод метода. Это можно понять из другого примера:
b) concurrent.futures.ProcessPoolExecutor: это следует использовать для программ с привязкой к CPU, таких как выполнение достаточных вычислений CPU. Пример ниже взят из официальной документации для иллюстрации:
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
Здесь проверяется число, является ли оно простым или нет, что требует вычислений CPU. У нас есть список из 6 чисел, поэтому мы передаем все 6 чисел для обработки и проверяем, является ли оно простым через ProcessPoolExecutor. Поскольку все выполнение будет выполняться на отдельных ядрах, и каждое ядро получает различный интерпретатор, поэтому блокировка GIL здесь не повлияет, и все executor.map будут работать параллельно.
Достаточно кодирования, давайте попробуем! потому что "что-то, что не проверено, сломано"
Python has a few popular testing libraries like unittest, pytest, etc. Unittest is what I have used most. We just need to extend the class unittest.Testcase in the unit test class and self.assertEquals or self.assertTrue etc. to assert any values. Mocking can also be done by using unittest.mock and unittest.patch decorator. A Test Suite can also be created after creating the unit tests in a single file just by extending unittest.TestSuite class. Sample test example:
В Python есть несколько популярных библиотек для тестирования, таких как unittest, pytest и т.д. Unittest - это то, что я использовал больше всего. Нам просто нужно расширить класс unittest.Testcase в классе модульного тестирования и self.assertEquals или self.assertTrue и т.д., чтобы проверять любые значения. Тестирование также можно выполнить с помощью unittest.mock и unittest.patch decorator. Test Suite также можно создать после создания модульных тестов в одном файле, просто расширив класс unittest.TestSuite. Тестовый пример:
Покрытие кода coverage
Библиотеку Python coverage можно использовать для проверки количества строк, написанных в модульном тесте. Пример команды ниже:
pytest --cov=main test/ --cov-report term-missing
coverage run -m pytest
Для проверки качества кода и выявления ошибок можно использовать Sonar, который выполняет сканирование кода Python.
Измерение времени отклика
In order to measure the response time of each method at the granular level, we can use the below decorator \@timed above any method. It returns the time taken to process any method.
Чтобы измерить время отклика каждого метода на уровне детализации, мы можем использовать приведенный ниже декоратор \@timed над любым методом. Возвращает время, затраченное на обработку любого метода.
Файловая структура проекта
Может быть несколько файлов, в которых может быть организована собственная структура, как показано ниже:
main/ controller/
resources/
service/
util/test/ controller/ test_filename.py
resources/
service/
util/
requirements.txt
Dockerfile
docker-componse.yml
Развертывание с использованием контейнеров
Должен быть создан Docker-контейнер, в который должны быть включены/загружены все стеки, такие как nginx, uwsgi и т.д., и точка входа для запуска сервера WSGI может быть предоставлена в Dockerfile. Для удобства можно использовать alpine как базовый образ, который очень легкий. Контейнеризация также помогает в развертывании приложения в кластере Kubernetes.
Вернуться на верх