Определение собственной функции Python
Оглавление
- Функции в Python
- Важность функций Python
- Вызовы и определение функций
- Передача аргументов
- Заявление о возврате
- Списки аргументов переменной длины
В предыдущих уроках этой серии вы видели множество примеров, демонстрирующих использование встроенных функций Python. В этом уроке вы узнаете, как определить свою собственную функцию Python. Вы узнаете, когда следует разделять свою программу на отдельные пользовательские функции и какие инструменты вам для этого понадобятся.
Вот что вы узнаете в этом уроке:
- Как функции работают в Python и почему они полезны
- Как определить и вызвать собственную функцию Python
- Механизмы передачи аргументов в вашу функцию
- Как возвращать данные из вашей функции обратно в вызывающую среду
Функции в Python
Вы, возможно, знакомы с математическим понятием функции. Функция - это связь или отображение между одним или несколькими входами и набором выходов. В математике функцию обычно представляют следующим образом:

Здесь f - это функция, которая работает со входами x и y. Выходом функции является z. Однако функции в программировании гораздо более обобщены и универсальны, чем это математическое определение. На самом деле, правильное определение и использование функций настолько важно для правильной разработки программного обеспечения, что практически все современные языки программирования поддерживают как встроенные, так и определяемые пользователем функции.
В программировании функция - это автономный блок кода, который инкапсулирует определенную задачу или связанную с ней группу задач. В предыдущих уроках этой серии вы познакомились с некоторыми встроенными функциями, предоставляемыми Python. id(), например, принимает один аргумент и возвращает уникальный целочисленный идентификатор этого объекта:
>>> s = 'foobar'
>>> id(s)
56313440
len() возвращает длину переданного ему аргумента:
>>> a = ['foo', 'bar', 'baz', 'qux']
>>> len(a)
4
any() принимает итерабель в качестве аргумента и возвращает True, если любой из элементов итерабеля является истинным и False в противном случае:
>>> any([False, False, False])
False
>>> any([False, True, False])
True
>>> any(['bar' == 'baz', len('foo') == 4, 'qux' in {'foo', 'bar', 'baz'}])
False
>>> any(['bar' == 'baz', len('foo') == 3, 'qux' in {'foo', 'bar', 'baz'}])
True
Каждая из этих встроенных функций выполняет определенную задачу. Код, который выполняет эту задачу, где-то определен, но вам не нужно знать, где или даже как этот код работает. Все, что вам нужно знать, это интерфейс функции:
- Какие аргументы (если таковые имеются) она принимает
- Какие значения (если таковые имеются) она возвращает
Затем вы вызываете функцию и передаете ей соответствующие аргументы. Программа отправляется в указанное тело кода и делает свое полезное дело. Когда функция завершает работу, выполнение возвращается к вашему коду, где оно остановилось. Функция может возвращать, а может и не возвращать данные для использования вашим кодом, как это сделано в приведенных выше примерах.
Когда вы определяете свою собственную функцию Python, она работает точно так же. Из какого-то места в коде вы вызовете свою функцию Python, и выполнение программы перейдет в тело кода, составляющее функцию.
Примечание: В этом случае вы будете знать, где находится код и как именно он работает, потому что вы его написали!
После завершения функции выполнение возвращается в то место, откуда была вызвана функция. В зависимости от того, как вы разработали интерфейс функции, данные могут передаваться при ее вызове, а возвращаемые значения - при завершении.
Важность функций Python
Практически все языки программирования, используемые сегодня, поддерживают ту или иную форму определяемых пользователем функций, хотя они не всегда называются функциями. В других языках они могут называться следующим образом:
- Подпрограммы
- Процедуры
- Методы
- Подпрограммы
Итак, зачем определять функции? Есть несколько очень веских причин. Давайте рассмотрим некоторые из них.
Абстракция и возможность повторного использования
Предположим, вы написали код, который делает что-то полезное. Продолжая разработку, вы обнаруживаете, что задача, выполняемая этим кодом, нужна вам часто и в разных местах вашего приложения. Что же делать? Ну, вы можете просто повторять код снова и снова, используя возможности копирования и вставки в вашем редакторе.
Позже вы, вероятно, решите, что данный код нуждается в модификации. Вы либо найдете в нем что-то неправильное, что нужно исправить, либо захотите как-то его улучшить. Если копии кода разбросаны по всему приложению, то вам придется вносить необходимые изменения в каждом месте.
Примечание: На первый взгляд, это может показаться разумным решением, но в долгосрочной перспективе это, скорее всего, станет кошмаром в обслуживании! Хотя ваш редактор кода может помочь, предоставив функцию поиска и замены, этот метод чреват ошибками, и вы легко можете внести в свой код ошибки, которые будет трудно найти.
Лучшее решение - определить функцию Python, выполняющую эту задачу. В любом месте вашего приложения, где вам нужно выполнить задачу, вы просто вызываете эту функцию. В дальнейшем, если вы решите изменить принцип работы, вам нужно будет изменить код только в одном месте - там, где определена функция. Изменения будут автоматически подхвачены в любом месте, где вызывается функция.
Абстрагирование функциональности в определении функции является примером принципа Don't Repeat Yourself (DRY) разработки программного обеспечения. Это, пожалуй, самая сильная мотивация для использования функций.
Модульность
Функции позволяют разбить сложные процессы на более мелкие шаги. Представьте, например, что у вас есть программа, которая считывает файл, обрабатывает его содержимое, а затем записывает выходной файл. Ваш код мог бы выглядеть так:
# Main program
# Code to read file in
<statement>
<statement>
<statement>
<statement>
# Code to process file
<statement>
<statement>
<statement>
<statement>
# Code to write file out
<statement>
<statement>
<statement>
<statement>
В этом примере основная программа представляет собой кучу кода, нанизанного на длинную последовательность, с пробелами и комментариями, помогающими организовать его. Однако если бы код стал намного длиннее и сложнее, то вам было бы все труднее разобраться в нем.
Альтернативно, вы можете структурировать код следующим образом:
def read_file():
# Code to read file in
<statement>
<statement>
<statement>
<statement>
def process_file():
# Code to process file
<statement>
<statement>
<statement>
<statement>
def write_file():
# Code to write file out
<statement>
<statement>
<statement>
<statement>
# Main program
read_file()
process_file()
write_file()
Этот пример модулирован. Вместо того чтобы объединять весь код, он разбит на отдельные функции, каждая из которых нацелена на выполнение определенной задачи. Этими задачами являются чтение, обработка и запись. Теперь основной программе нужно просто вызвать каждую из них по очереди.
Примечание: Ключевое слово def вводит новое определение функции Python. Вы узнаете об этом совсем скоро.
В жизни вы постоянно поступаете подобным образом, даже если не думаете об этом явно. Если вы хотите перенести несколько полок с вещами с одной стороны гаража на другую, то, надеюсь, вы не будете просто стоять и бесцельно думать: "О, черт. Мне нужно перенести все эти вещи туда! Как мне это сделать???" Вы разделите работу на простые шаги:
- Возьмите все вещи с полок.
- Разберите полки на части.
- Перенесите части полок через весь гараж на новое место.
- Повторная сборка полок.
- Перенесите вещи через гараж.
- Положите вещи обратно на полки.
Разбив большую задачу на более мелкие, кусочные подзадачи, вы облегчите обдумывание и управление большой задачей. По мере усложнения программ становится все более выгодным их модульное построение.
Разделение пространства имен
Пространство имен - это область программы, в которой идентификаторы имеют смысл. Как вы увидите ниже, при вызове функции Python для нее создается новое пространство имен, отличное от всех других пространств имен, которые уже существуют.
Практический результат этого заключается в том, что переменные можно определять и использовать внутри функции Python, даже если они имеют то же имя, что и переменные, определенные в других функциях или в основной программе. В этих случаях не возникнет путаницы или помех, поскольку они хранятся в отдельных пространствах имен.
Это означает, что при написании кода внутри функции вы можете использовать имена переменных и идентификаторы, не заботясь о том, используются ли они уже где-то за пределами функции. Это позволяет значительно сократить количество ошибок в коде.
Примечание: Вы узнаете гораздо больше о пространствах имен позже в этой серии.
Надеемся, вы достаточно убедились в достоинствах функций и хотите их создать! Давайте посмотрим, как это сделать.
Вызовы и определение функций
Обычный синтаксис для определения функции Python выглядит следующим образом:
def <function_name>([<parameters>]):
<statement(s)>
Компоненты определения приведены в таблице ниже:
| Component | Meaning |
|---|---|
def |
The keyword that informs Python that a function is being defined |
<function_name> |
A valid Python identifier that names the function |
<parameters> |
An optional, comma-separated list of parameters that may be passed to the function |
: |
Punctuation that denotes the end of the Python function header (the name and parameter list) |
<statement(s)> |
A block of valid Python statements |
Последний элемент, <statement(s)>, называется body функции. Тело - это блок операторов, которые будут выполняться при вызове функции. Тело функции Python определяется отступом в соответствии с правилом off-side. Это то же самое, что и блоки кода, связанные с управляющей структурой, такие как if или while оператор.
Синтаксис вызова функции Python выглядит следующим образом:
<function_name>([<arguments>])
<arguments> - это значения, передаваемые в функцию. Они соответствуют <parameters> в определении функции Python. Вы можете определить функцию, которая не принимает никаких аргументов, но круглые скобки все равно необходимы. И определение функции, и вызов функции всегда должны содержать круглые скобки, даже если они пустые.
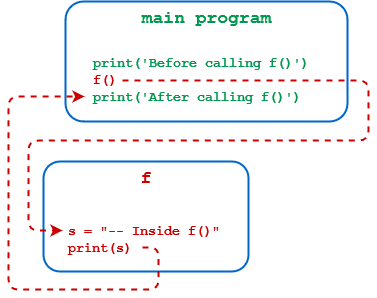
Как обычно, вы начнете с небольшого примера и будете усложнять его. Помня о проверенной временем математической традиции, вы назовете свою первую функцию Python f(). Вот файл сценария foo.py, который определяет и вызывает f():
1def f():
2 s = '-- Inside f()'
3 print(s)
4
5print('Before calling f()')
6f()
7print('After calling f()')
Вот как работает этот код:
-
В строке 1 используется ключевое слово
defдля указания на то, что определяется функция. Выполнение оператораdefпросто создает определениеf(). Все следующие строки с отступом (строки 2-3) становятся частью телаf()и сохраняются как его определение, но пока не выполняются. -
Строка 4 - это небольшой пробел между определением функции и первой строкой основной программы. Хотя синтаксически он не является необходимым, его приятно иметь. Чтобы узнать больше о пробельных символах вокруг определений функций Python верхнего уровня, прочитайте статью Writing Beautiful Pythonic Code With PEP 8.
-
Строка 5 - это первое утверждение, которое не имеет отступов, потому что оно не является частью определения
f(). Это начало основной программы. При выполнении основной программы это утверждение выполняется первым. -
Строка 6 является вызовом
f(). Обратите внимание, что пустые круглые скобки всегда требуются как в определении функции, так и в ее вызове, даже если нет параметров или аргументов. Выполнение переходит кf(), и операторы в телеf()выполняются. -
Строка 7 является следующей строкой, которая будет выполняться после завершения тела
f(). Выполнение возвращается к этомуprint()оператору .
Последовательность выполнения (или поток управления) для foo.py показана на следующей диаграмме:
Когда foo.py запускается из командной строки Windows, результат следующий:
Командная строка Windows
C:\Users\john\Documents\Python\doc>python foo.py
Before calling f()
-- Inside f()
After calling f()
Иногда вам может понадобиться определить пустую функцию, которая ничего не делает. Это называется stub, который обычно является временным держателем для функции Python, которая будет полностью реализована позже. Как блок в управляющей структуре не может быть пустым, так и тело функции не может быть пустым. Чтобы определить функцию-заглушку, используйте passstatement:
>>> def f():
... pass
...
>>> f()
Как вы можете видеть выше, вызов функции-заглушки синтаксически корректен, но ничего не делает.
Передача аргументов
До сих пор в этом учебнике функции, которые вы определяли, не принимали никаких аргументов. Иногда это может быть полезно, и вы будете время от времени писать такие функции. Однако чаще всего вы захотите передать данные в функцию, чтобы ее поведение менялось от одного вызова к другому. Давайте посмотрим, как это сделать.
Позиционные аргументы
Самым простым способом передачи аргументов в функцию Python являются позиционные аргументы (также называемые необходимыми аргументами). В определении функции вы указываете список параметров, разделенных запятыми, внутри круглых скобок:
>>> def f(qty, item, price):
... print(f'{qty} {item} cost ${price:.2f}')
...
При вызове функции вы указываете соответствующий список аргументов:
>>> f(6, 'bananas', 1.74)
6 bananas cost $1.74
Параметры (qty, item и price) ведут себя как переменные , которые определены локально для функции. Когда функция вызывается, передаваемые аргументы (6, 'bananas' и 1.74) привязываются к параметрам в порядке, как при присваивании переменных:
| Parameter | Argument | |
|---|---|---|
qty |
← | 6 |
item |
← | bananas |
price |
← | 1.74 |
В некоторых текстах по программированию параметры, заданные в определении функции, называются формальными параметрами, а аргументы в вызове функции - фактическими параметрами:
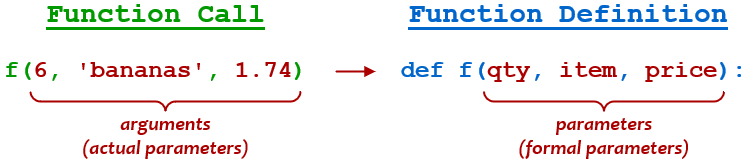
Хотя позиционные аргументы являются наиболее простым способом передачи данных в функцию, они также обеспечивают наименьшую гибкость. Для начала, порядок аргументов в вызове должен совпадать с порядком параметров в определении. Конечно, ничто не мешает вам указать позиционные аргументы не по порядку:
>>> f('bananas', 1.74, 6)
bananas 1.74 cost $6.00
Функция может даже выполниться, как это было в приведенном выше примере, но очень маловероятно, что она выдаст правильные результаты. Программист, определяющий функцию, обязан документировать, какими должны быть подходящие аргументы, а пользователь функции обязан знать эту информацию и следовать ей.
При позиционных аргументах аргументы в вызове и параметры в определении должны совпадать не только по порядку, но и по количеству. По этой причине позиционные аргументы также называют обязательными аргументами. Ни один из них нельзя опустить при вызове функции:
>>> # Too few arguments
>>> f(6, 'bananas')
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
f(6, 'bananas')
TypeError: f() missing 1 required positional argument: 'price'
Вы не можете указать дополнительные:
>>> # Too many arguments
>>> f(6, 'bananas', 1.74, 'kumquats')
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
f(6, 'bananas', 1.74, 'kumquats')
TypeError: f() takes 3 positional arguments but 4 were given
Позиционные аргументы концептуально просты в использовании, но они не очень просты. Вы должны указать столько же аргументов в вызове функции, сколько параметров в ее определении, и в точно таком же порядке. В последующих разделах вы познакомитесь с некоторыми приемами передачи аргументов, которые снимают эти ограничения.
Ключевые слова-аргументы
При вызове функции вы можете указать аргументы в форме <keyword>=<value>. В этом случае каждый <keyword> должен соответствовать параметру в определении функции Python. Например, ранее определенная функция f() может быть вызвана с аргументами в виде ключевых слов следующим образом:
>>> f(qty=6, item='bananas', price=1.74)
6 bananas cost $1.74
Ссылка на ключевое слово, которое не соответствует ни одному из объявленных параметров, вызывает исключение:
>>> f(qty=6, item='bananas', cost=1.74)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() got an unexpected keyword argument 'cost'
Использование аргументов с ключевыми словами снимает ограничение на порядок аргументов. Каждый аргумент с ключевым словом явно обозначает конкретный параметр по имени, поэтому вы можете указывать их в любом порядке, и Python все равно будет знать, какой аргумент к какому параметру относится:
>>> f(item='bananas', price=1.74, qty=6)
6 bananas cost $1.74
Однако, как и в случае с позиционными аргументами, количество аргументов и параметров все равно должно совпадать:
>>> # Still too few arguments
>>> f(qty=6, item='bananas')
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
f(qty=6, item='bananas')
TypeError: f() missing 1 required positional argument: 'price'
Таким образом, аргументы в виде ключевых слов позволяют гибко менять порядок указания аргументов функции, но количество аргументов остается жестким.
Вы можете вызывать функцию, используя как позиционные, так и ключевые аргументы:
>>> f(6, price=1.74, item='bananas')
6 bananas cost $1.74
>>> f(6, 'bananas', price=1.74)
6 bananas cost $1.74
Когда присутствуют и позиционные, и ключевые аргументы, все позиционные аргументы должны идти первыми:
>>> f(6, item='bananas', 1.74)
SyntaxError: positional argument follows keyword argument
Если вы указали аргумент в виде ключевого слова, то справа от него не может быть никаких позиционных аргументов.
Чтобы узнать больше о позиционных и ключевых параметрах, ознакомьтесь с курсом Real Python Exploring Special Function Parameters.
Параметры по умолчанию
Если параметр, указанный в определении функции Python, имеет вид <name>=<value>, то <value> становится значением по умолчанию для этого параметра. Параметры, определенные таким образом, называются параметрами по умолчанию или необязательными параметрами. Пример определения функции с параметрами по умолчанию показан ниже:
>>> def f(qty=6, item='bananas', price=1.74):
... print(f'{qty} {item} cost ${price:.2f}')
...
Когда вызывается эта версия f(), любой аргумент, оставленный без внимания, принимает значение по умолчанию:
>>> f(4, 'apples', 2.24)
4 apples cost $2.24
>>> f(4, 'apples')
4 apples cost $1.74
>>> f(4)
4 bananas cost $1.74
>>> f()
6 bananas cost $1.74
>>> f(item='kumquats', qty=9)
9 kumquats cost $1.74
>>> f(price=2.29)
6 bananas cost $2.29
В итоге:
- Позиционные аргументы должны совпадать по порядку и количеству с параметрами, объявленными в определении функции.
- Ключевые аргументы должны совпадать по количеству с объявленными параметрами, но могут быть указаны в произвольном порядке.
- Параметры по умолчанию позволяют опустить некоторые аргументы при вызове функции.
Неизменяемые значения параметров по умолчанию
Если указать значение параметра по умолчанию, которое является объектом mutable, все может пойти не так гладко. Рассмотрим это определение функции Python:
>>> def f(my_list=[]):
... my_list.append('###')
... return my_list
...
f() принимает один параметр списка, добавляет строку '###' в конец списка и возвращает результат:
>>> f(['foo', 'bar', 'baz'])
['foo', 'bar', 'baz', '###']
>>> f([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5, '###']
По умолчанию параметр my_list имеет значение пустого списка, поэтому если f() вызывается без аргументов, то возвращаемым значением будет список с единственным элементом '###':
>>> f()
['###']
Пока что все имеет смысл. Теперь, что произойдет, если f() вызвать без параметров во второй и третий раз? Давайте посмотрим:
>>> f()
['###', '###']
>>> f()
['###', '###', '###']
Упс! Можно было ожидать, что каждый последующий вызов также вернет список синглтонов ['###'], как и первый. Вместо этого возвращаемое значение продолжает расти. Что случилось?
В Python значения параметров по умолчанию определяются только один раз при определении функции (то есть при выполнении оператора def). Значение по умолчанию не переопределяется при каждом вызове функции. Таким образом, каждый раз, когда вы вызываете f() без параметра, вы выполняете .append() над одним и тем же списком.
Вы можете продемонстрировать это с помощью id():
>>> def f(my_list=[]):
... print(id(my_list))
... my_list.append('###')
... return my_list
...
>>> f()
140095566958408
['###']
>>> f()
140095566958408
['###', '###']
>>> f()
140095566958408
['###', '###', '###']
Отображаемый идентификатор объекта подтверждает, что, когда my_list разрешено использовать по умолчанию, при каждом вызове значением является один и тот же объект. Поскольку списки мутабельны, каждый последующий вызов .append() приводит к тому, что список становится длиннее. Это распространенный и довольно хорошо документированный подводный камень, когда вы используете мутабельный объект в качестве значения параметра по умолчанию. Потенциально это может привести к запутанному поведению кода, и, вероятно, этого лучше избегать.
В качестве обходного пути можно использовать значение аргумента по умолчанию, которое сигнализирует о том, что не указан аргумент. Подойдет практически любое значение, но часто используется None. Когда значение sentinel указывает на отсутствие аргумента, создайте новый пустой список внутри функции:
>>> def f(my_list=None):
... if my_list is None:
... my_list = []
... my_list.append('###')
... return my_list
...
>>> f()
['###']
>>> f()
['###']
>>> f()
['###']
>>> f(['foo', 'bar', 'baz'])
['foo', 'bar', 'baz', '###']
>>> f([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5, '###']
Обратите внимание на то, как это гарантирует, что my_list теперь действительно по умолчанию будет пустой список всякий раз, когда f() вызывается без аргумента.
Pass-By-Value vs Pass-By-Reference в Pascal
В языке программирования существует две распространенные парадигмы передачи аргумента в функцию:
- Pass-by-value: В функцию передается копия аргумента.
- Pass-by-reference: В функцию передается ссылка на аргумент.
Существуют и другие механизмы, но они, по сути, являются вариациями этих двух. В этом разделе вы ненадолго отвлечетесь от Python и кратко рассмотрите Pascal, язык программирования, который проводит особенно четкое различие между этими двумя.
Примечание: Не волнуйтесь, если вы не знакомы с Паскалем! Концепции схожи с концепциями Python, а приведенные примеры сопровождаются достаточно подробными объяснениями, чтобы вы получили общее представление. Как только вы увидите, как работает передача аргументов в Паскале, мы вернемся к Python, и вы увидите, как это сравнимо.
Вот что вам нужно знать о синтаксисе Паскаля:
- Процедуры: Процедура в Паскале похожа на функцию в Python.
- Двоеточие-равно: Этот оператор (
:=) используется для присваивания в Паскале. Он аналогичен знаку равенства (=) в Python. writeln(): Эта функция выводит данные на консоль, аналогично питоновскойprint().
После этой небольшой подготовки, вот первый пример на Паскале:
1 // Pascal Example #1
2
3 procedure f(fx : integer);
4 begin
5 writeln('Start f(): fx = ', fx);
6 fx := 10;
7 writeln('End f(): fx = ', fx);
8 end;
9
10 // Main program
11 var
12 x : integer;
13
14 begin
15 x := 5;
16 writeln('Before f(): x = ', x);
17 f(x);
18 writeln('After f(): x = ', x);
19 end.
Вот что происходит:
- Строка 12: В основной программе определена целочисленная переменная
x. - Строка 15: Она первоначально присваивает
xзначение5. - Строка 17: Затем она вызывает процедуру
f(), передаваяxв качестве аргумента. - Строка 5: Внутри
f()операторwriteln()показывает, что соответствующий параметрfxизначально является5, переданным значением. - Строка 6:
fxзатем присваивается значение10. - Строка 7: Это значение проверяется этим
writeln()оператором, выполняемым непосредственно передf()выходом. - Строка 18: Вернувшись в среду вызова основной программы, этот оператор
writeln()показывает, что после возвратаf(),xпо-прежнему5, как и до вызова процедуры.
Запуск этого кода приводит к следующим результатам:
Before f(): x = 5
Start f(): fx = 5
End f(): fx = 10
After f(): x = 5
В этом примере x передается значением, поэтому f() получает только копию. Когда соответствующий параметр fx изменяется, x не затрагивается.
Примечание: Если вы хотите увидеть это в действии, то можете выполнить код самостоятельно, используя онлайн-компилятор Паскаля.
Просто выполните следующие действия:
- Скопируйте код из окна с кодом выше.
- Посетите Онлайн-компилятор Паскаля.
- В окне кода слева замените все существующее содержимое кодом, который вы скопировали в шаге 1.
- Нажмите Execute.
Вы должны увидеть тот же результат, что и выше.
Теперь сравните это со следующим примером:
1 // Pascal Example #2
2
3 procedure f(var fx : integer);
4 begin
5 writeln('Start f(): fx = ', fx);
6 fx := 10;
7 writeln('End f(): fx = ', fx);
8 end;
9
10 // Main program
11 var
12 x : integer;
13
14 begin
15 x := 5;
16 writeln('Before f(): x = ', x);
17 f(x);
18 writeln('After f(): x = ', x);
19 end.
Этот код идентичен первому примеру, с одним изменением. Это наличие слова var перед fx в определении процедуры f() в строке 3. Это указывает на то, что аргумент в f() передается по ссылке . Изменения, внесенные в соответствующий параметр fx, также изменят аргумент в вызывающей среде.
Вывод этого кода такой же, как и предыдущего, за исключением последней строки:
Before f(): x = 5
Start f(): fx = 5
End f(): fx = 10
After f(): x = 10
Опять же, fx, как и раньше, присваивается значение 10 внутри f(). Но на этот раз, когда f() возвращается, x в основной программе также был изменен.
Во многих языках программирования это, по сути, различие между передачей по значению и передачей по ссылке:
- Если переменная передается по значению, то функция имеет копию для работы, но не может изменить исходное значение в вызывающей среде.
- Если переменная передается по ссылке, то любые изменения, которые функция вносит в соответствующий параметр, влияют на значение в вызывающей среде.
Причина этого кроется в том, что означает референция в этих языках. Значения переменных хранятся в памяти. В Паскале и подобных языках ссылка - это, по сути, адрес этого участка памяти, как показано ниже:
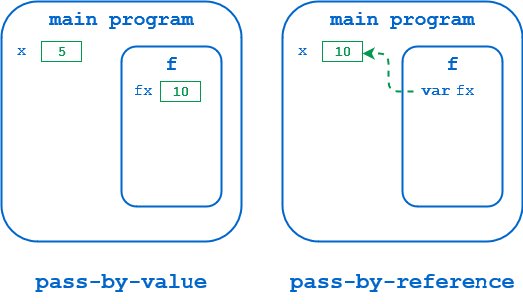
На диаграмме слева, x имеет память, выделенную в пространстве имен основной программы. Когда вызывается f(), x передается по значению , поэтому память для соответствующего параметра fx выделяется в пространстве имен f(), и значение x копируется туда. Когда f() изменяет fx, изменяется именно эта локальная копия. Значение x в вызывающей среде остается незатронутым.
На диаграмме справа x передается по ссылке . Соответствующий параметр fx указывает на фактический адрес в пространстве имен основной программы, где хранится значение x. Когда f() изменяет fx, он изменяет значение в этом месте, точно так же, как если бы основная программа изменяла x сама.
Pass-By-Value vs Pass-By-Reference в Python
Параметры в Python передаются по значению или по ссылке? Ответ: ни то, ни другое. Это потому, что ссылка в Python означает не совсем то же самое, что в Pascal.
Напомним, что в Python каждый фрагмент данных - это объект. Ссылка указывает на объект, а не на конкретную область памяти. Это означает, что присваивание в Python интерпретируется не так, как в Pascal. Рассмотрим следующую пару утверждений в Паскале:
Паскаль
x := 5
x := 10
Они интерпретируются следующим образом:
- Переменная
xссылается на определенную область памяти. - Первый оператор помещает значение
5в это место. - Следующий оператор перезаписывает
5и помещает10туда вместо него.
В отличие от этого, в Python аналогичные операторы присваивания выглядят следующим образом:
x = 5
x = 10
Эти операторы присваивания имеют следующий смысл:
- Первый оператор заставляет
xуказывать на объект, значение которого5. - <<<Следующий оператор
- переназначает
xкак новую ссылку на другой объект, значение которого10. Говоря иначе, второе присваивание перепривязываетxк другому объекту со значением10.
В Python, когда вы передаете аргумент в функцию, происходит аналогичная перепривязка. Рассмотрим этот пример:
1 >>> def f(fx):
2 ... fx = 10
3 ...
4 >>> x = 5
5 >>> f(x)
6 >>> x
75
В основной программе оператор x = 5 в строке 4 создает ссылку с именем x, связанную с объектом, значение которого 5. Затем в строке 5 вызывается оператор f(), аргументом которого является x. При первом запуске f() создается новая ссылка fx, которая первоначально указывает на тот же объект 5, что и x:
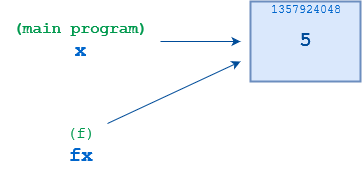
Однако, когда выполняется оператор fx = 10 в строке 2, f() перепривязывает fx к новому объекту, значением которого является 10. Эти две ссылки, x и fx, несвязаны друг с другом. Ничто другое, что делает f(), не повлияет на x, и когда f() завершится, x по-прежнему будет указывать на объект 5, как и до вызова функции:
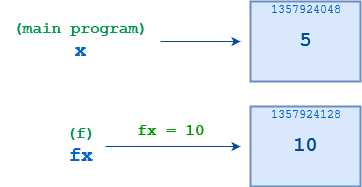
Вы можете подтвердить все это, используя id(). Вот немного дополненная версия приведенного выше примера, в которой отображаются числовые идентификаторы задействованных объектов:
1 >>> def f(fx):
2 ... print('fx =', fx, '/ id(fx) = ', id(fx))
3 ... fx = 10
4 ... print('fx =', fx, '/ id(fx) = ', id(fx))
5 ...
6
7 >>> x = 5
8 >>> print('x =', x, '/ id(x) = ', id(x))
9 x = 5 / id(x) = 1357924048
10
11 >>> f(x)
12 fx = 5 / id(fx) = 1357924048
13 fx = 10 / id(fx) = 1357924128
14
15 >>> print('x =', x, '/ id(x) = ', id(x))
16 x = 5 / id(x) = 1357924048
Когда впервые запускается f(), fx и x указывают на один и тот же объект, чьим id() является 1357924048. После того как f() выполнит оператор fx = 10 в строке 3, fx указывает на другой объект, чье id() равно 1357924128. Связь с исходным объектом в вызывающей среде теряется.
Передача аргументов в Python представляет собой некий гибрид между передачей по значению и передачей по ссылке. То, что передается в функцию, является ссылкой на объект, но ссылка передается по значению.
Примечание: Механизм передачи аргументов в Python называют pass-by-assignment. Это связано с тем, что в Python имена параметров привязываются к объектам при входе в функцию, а присваивание - это тоже процесс привязки имени к объекту. Вы также можете встретить термины pass-by-object, pass-by-object-reference или pass-by-sharing.
Ключевым моментом здесь является то, что функция Python не может изменить значение аргумента, переназначив соответствующий параметр на что-то другое. Следующий пример демонстрирует это:
>>> def f(x):
... x = 'foo'
...
>>> for i in (
... 40,
... dict(foo=1, bar=2),
... {1, 2, 3},
... 'bar',
... ['foo', 'bar', 'baz']):
... f(i)
... print(i)
...
40
{'foo': 1, 'bar': 2}
{1, 2, 3}
bar
['foo', 'bar', 'baz']
Здесь в качестве аргументов в f() передаются объекты типа int, dict, set, str и list. f() пытается присвоить каждый из них строковому объекту 'foo', но, как вы видите, после возвращения в вызывающую среду все они остаются неизменными. Как только f() выполняет присваивание x = 'foo', ссылка возвращается , и связь с исходным объектом теряется.
Значит ли это, что функция Python вообще не может изменять свои аргументы? На самом деле, нет, это не так! Посмотрите, что здесь происходит:
>>> def f(x):
... x[0] = '---'
...
>>> my_list = ['foo', 'bar', 'baz', 'qux']
>>> f(my_list)
>>> my_list
['---', 'bar', 'baz', 'qux']
В данном случае аргументом f() является список. При вызове f() передается ссылка на my_list. Вы уже видели, что f() не может переназначить my_list оптом. Если бы x был назначен чему-то другому, то он был бы привязан к другому объекту, и связь с my_list была бы потеряна.
Однако f() может использовать ссылку для внесения изменений внутри my_list. Здесь f() модифицировал первый элемент. Вы можете видеть, что после возврата функции my_list фактически был изменен в вызывающей среде. Та же концепция применима к словарю:
>>> def f(x):
... x['bar'] = 22
...
>>> my_dict = {'foo': 1, 'bar': 2, 'baz': 3}
>>> f(my_dict)
>>> my_dict
{'foo': 1, 'bar': 22, 'baz': 3}
Здесь f() использует x в качестве ссылки, чтобы внести изменения внутри my_dict. Это изменение отражается в вызывающей среде после возвращения f().
Краткий обзор передачи аргументов
Передача аргументов в Python может быть кратко описана следующим образом. Передача неизменяемого объекта, например int, str, tuple или frozenset, в функцию Python действует как передача по значению. Функция не может модифицировать объект в вызывающей среде.
Передача мутабельного объекта, такого как list, dict или set, действует в некоторой степени - но не совсем - как передача по ссылке. Функция не может переназначить объект оптом, но она может изменить элементы внутри объекта, и эти изменения будут отражены в вызывающей среде.
Побочные эффекты
Итак, в Python можно изменять аргумент внутри функции так, чтобы изменения отражались в вызывающей среде. Но стоит ли это делать? Это пример того, что на жаргоне программистов называется побочным эффектом.
В более общем случае считается, что функция Python вызывает побочный эффект, если она каким-либо образом изменяет окружение своего вызова. Изменение значения аргумента функции - лишь одна из возможностей.
Примечание: Вы, вероятно, знакомы с побочными эффектами из области здравоохранения, где этот термин обычно относится к нежелательным последствиям приема лекарств. Часто это нежелательное последствие, например, рвота или седативный эффект. С другой стороны, побочные эффекты могут быть использованы намеренно. Например, некоторые лекарства вызывают стимуляцию аппетита, что можно использовать в своих интересах, даже если это не является основной целью лекарства.
В программировании концепция аналогична. Если побочный эффект является хорошо документированной частью спецификации функции, и пользователь функции явно осведомлен о том, когда и как может быть изменено окружение вызова, то это может быть нормально. Но программист может не всегда правильно документировать побочные эффекты или даже не знать, что они возникают.
Когда они скрыты или неожиданны, побочные эффекты могут привести к программным ошибкам, которые очень трудно отследить. Как правило, их лучше избегать.
Заявление return
Что же тогда должна делать функция Python? Ведь во многих случаях, если функция не приводит к каким-то изменениям в вызывающем окружении, то нет особого смысла вызывать ее вообще. Как функция должна влиять на вызывающего ее пользователя?
Ну, одна из возможностей - использовать возвращаемые значения функций. Оператор return в функции Python служит двум целям:
- Она немедленно завершает функцию и передает управление выполнением обратно вызывающей стороне.
- Обеспечивает механизм, с помощью которого функция может передавать данные обратно вызывающей стороне.
Выход из функции
Внутри функции оператор return вызывает немедленный выход из функции Python и передачу выполнения обратно вызывающей стороне:
>>> def f():
... print('foo')
... print('bar')
... return
...
>>> f()
foo
bar
В этом примере утверждение return на самом деле лишнее. Функция возвращается к вызывающему ее пользователю, когда она заканчивается , то есть после выполнения последнего оператора тела функции. Таким образом, эта функция вела бы себя идентично и без оператора return.
Однако операторы return не обязательно должны находиться в конце функции. Они могут появляться в любом месте тела функции, и даже несколько раз. Рассмотрим этот пример:
1 >>> def f(x):
2 ... if x < 0:
3 ... return
4 ... if x > 100:
5 ... return
6 ... print(x)
7 ...
8
9 >>> f(-3)
10 >>> f(105)
11 >>> f(64)
1264
Первые два вызова f() не вызывают никакого вывода, потому что выполняется оператор return и функция выходит преждевременно, до того, как будет достигнут оператор print() в строке 6.
Подобная парадигма может быть полезна для проверки ошибок в функции. Вы можете проверить несколько условий ошибки в начале функции с помощью операторов return, которые отключаются в случае возникновения проблемы:
def f():
if error_cond1:
return
if error_cond2:
return
if error_cond3:
return
<normal processing>
Если ни одно из условий ошибки не встречается, то функция может продолжить свою обычную обработку.
Возврат данных вызывающему абоненту
Помимо выхода из функции, оператор return также используется для передачи данных обратно вызывающей стороне. Если за оператором return внутри функции Python следует выражение, то в вызывающей среде вызов функции оценивается как значение этого выражения:
1 >>> def f():
2 ... return 'foo'
3 ...
4
5 >>> s = f()
6 >>> s
7 'foo'
Здесь значение выражения f() в строке 5 равно 'foo', которое впоследствии присваивается переменной s.
Функция может возвращать любой тип объекта. В Python это означает практически все, что угодно. В вызывающей среде вызов функции может быть использован синтаксически любым способом, который имеет смысл для типа объекта, возвращаемого функцией.
Например, в этом коде f() возвращает словарь. Тогда в вызывающей среде выражение f() представляет словарь, а f()['baz'] является корректной ключевой ссылкой на этот словарь:
>>> def f():
... return dict(foo=1, bar=2, baz=3)
...
>>> f()
{'foo': 1, 'bar': 2, 'baz': 3}
>>> f()['baz']
3
В следующем примере f() возвращает строку, которую можно нарезать, как любую другую строку:
>>> def f():
... return 'foobar'
...
>>> f()[2:4]
'ob'
Здесь f() возвращает список, который может быть проиндексирован или нарезан:
>>> def f():
... return ['foo', 'bar', 'baz', 'qux']
...
>>> f()
['foo', 'bar', 'baz', 'qux']
>>> f()[2]
'baz'
>>> f()[::-1]
['qux', 'baz', 'bar', 'foo']
Если в операторе return указано несколько выражений, разделенных запятыми, то они упаковываются и возвращаются в виде кортежа:
>>> def f():
... return 'foo', 'bar', 'baz', 'qux'
...
>>> type(f())
<class 'tuple'>
>>> t = f()
>>> t
('foo', 'bar', 'baz', 'qux')
>>> a, b, c, d = f()
>>> print(f'a = {a}, b = {b}, c = {c}, d = {d}')
a = foo, b = bar, c = baz, d = qux
Когда возвратное значение не указано, функция Python возвращает специальное значение Python None:
>>> def f():
... return
...
>>> print(f())
None
То же самое происходит, если тело функции вообще не содержит оператора return и функция выпадает из конца:
>>> def g():
... pass
...
>>> print(g())
None
Напомните, что None является ошибочным, когда вычисляется в булевом контексте.
Поскольку функции, выходящие через голое утверждение return или отваливающиеся от конца, возвращают None, вызов такой функции можно использовать в булевом контексте:
>>> def f():
... return
...
>>> def g():
... pass
...
>>> if f() or g():
... print('yes')
... else:
... print('no')
...
no
Здесь вызовы f() и g() являются ложными, поэтому f() or g() также является ложным, и предложение else выполняется.
Пересмотр побочных эффектов
Предположим, вы хотите написать функцию, которая принимает целочисленный аргумент и удваивает его. То есть вы хотите передать в функцию целочисленную переменную, и когда функция вернется, значение переменной в вызывающей среде должно быть в два раза больше, чем было. В Паскале этого можно добиться, используя передачу по ссылке:
1 procedure double(var x : integer);
2 begin
3 x := x * 2;
4 end;
5
6 var
7 x : integer;
8
9 begin
10 x := 5;
11 writeln('Before procedure call: ', x);
12 double(x);
13 writeln('After procedure call: ', x);
14 end.
Выполнение этого кода дает следующий результат, который подтверждает, что double() действительно изменяет x в вызывающей среде:
Before procedure call: 5
After procedure call: 10
В Python это не сработает. Как вы уже знаете, целые числа в Python неизменяемы, поэтому функция Python не может изменить целочисленный аргумент с помощью побочного эффекта:
>>> def double(x):
... x *= 2
...
>>> x = 5
>>> double(x)
>>> x
5
Однако для достижения аналогичного эффекта можно использовать возвращаемое значение. Просто напишите double() так, чтобы она принимала целочисленный аргумент, удваивала его и возвращала удвоенное значение. Затем вызывающая сторона отвечает за присваивание, которое изменяет исходное значение:
>>> def double(x):
... return x * 2
...
>>> x = 5
>>> x = double(x)
>>> x
10
Это, пожалуй, предпочтительнее, чем модификация по побочному эффекту. Совершенно очевидно, что x модифицируется в вызывающем окружении, поскольку вызывающая сторона делает это сама. В любом случае, это единственный вариант, потому что модификация по побочному эффекту в данном случае не работает.
Тем не менее, даже в тех случаях, когда есть возможность изменить аргумент с помощью побочного эффекта, использование возвращаемого значения может быть более понятным. Предположим, вы хотите удвоить каждый элемент в списке. Поскольку списки являются изменяемыми, вы можете определить функцию Python, которая модифицирует список на месте:
>>> def double_list(x):
... i = 0
... while i < len(x):
... x[i] *= 2
... i += 1
...
>>> a = [1, 2, 3, 4, 5]
>>> double_list(a)
>>> a
[2, 4, 6, 8, 10]
В отличие от double() в предыдущем примере, double_list() действительно работает так, как задумано. Если в документации к функции четко указано, что изменяется содержимое аргумента list, то это может быть разумной реализацией.
Однако вы также можете написать double_list(), чтобы передать нужный список обратно в виде возвращаемого значения и позволить вызывающей стороне выполнить присваивание, подобно тому, как double() был переписан в предыдущем примере:
>>> def double_list(x):
... r = []
... for i in x:
... r.append(i * 2)
... return r
...
>>> a = [1, 2, 3, 4, 5]
>>> a = double_list(a)
>>> a
[2, 4, 6, 8, 10]
Любой из этих подходов работает одинаково хорошо. Как это часто бывает, это вопрос стиля, и личные предпочтения могут быть разными. Побочные эффекты не обязательно являются абсолютным злом, и у них есть свое место, но поскольку из функции можно вернуть практически все, что угодно, то и с помощью возвращаемых значений обычно можно добиться того же самого.
Списки аргументов переменной длины
В некоторых случаях, когда вы определяете функцию, вы можете заранее не знать, сколько аргументов она должна принимать. Предположим, например, что вы хотите написать функцию Python, которая вычисляет среднее значение нескольких величин. Вы можете начать с чего-то вроде этого:
>>> def avg(a, b, c):
... return (a + b + c) / 3
...
Все хорошо, если вы хотите усреднить три значения:
>>> avg(1, 2, 3)
2.0
Однако, как вы уже видели, когда используются позиционные аргументы, количество передаваемых аргументов должно соответствовать количеству объявленных параметров. Очевидно, что с этой реализацией avg() для любого количества значений, отличного от трех, не все в порядке:
>>> avg(1, 2, 3, 4)
Traceback (most recent call last):
File "<pyshell#34>", line 1, in <module>
avg(1, 2, 3, 4)
TypeError: avg() takes 3 positional arguments but 4 were given
Вы можете попробовать определить avg() с необязательными параметрами:
>>> def avg(a, b=0, c=0, d=0, e=0):
... .
... .
... .
...
Это позволяет указывать переменное количество аргументов. Следующие вызовы, по крайней мере, синтаксически корректны:
avg(1)
avg(1, 2)
avg(1, 2, 3)
avg(1, 2, 3, 4)
avg(1, 2, 3, 4, 5)
Но этот подход все равно страдает от нескольких проблем. Для начала, он по-прежнему допускает только пять аргументов, а не произвольное число. Хуже того, нет способа отличить аргументы, которые были указаны, от тех, которые были разрешены по умолчанию. У функции нет способа узнать, сколько аргументов было передано на самом деле, поэтому она не знает, на что делить:
>>> def avg(a, b=0, c=0, d=0, e=0):
... return (a + b + c + d + e) / # Divided by what???
...
Очевидно, что это тоже не поможет.
Вы можете написать avg(), чтобы принимать один аргумент в виде списка:
>>> def avg(a):
... total = 0
... for v in a:
... total += v
... return total / len(a)
...
>>> avg([1, 2, 3])
2.0
>>> avg([1, 2, 3, 4, 5])
3.0
По крайней мере, это работает. Он допускает произвольное количество значений и выдает корректный результат. В качестве дополнительного бонуса, он работает, когда аргумент является кортежем, а также:
>>> t = (1, 2, 3, 4, 5)
>>> avg(t)
3.0
Недостатком является то, что дополнительный шаг, связанный с необходимостью группировать значения в список или кортеж, вероятно, не является тем, чего ожидает пользователь функции, и это не очень элегантно. Всякий раз, когда вы находите код на Python, который выглядит элегантно, вероятно, есть лучший вариант.
В этом случае, действительно, есть! Python предоставляет возможность передавать функции переменное количество аргументов с упаковкой и распаковкой кортежей аргументов с помощью оператора звездочки (*).
Упаковка кортежей аргументов
Когда перед именем параметра в определении функции Python ставится звездочка (*), это указывает на упаковку кортежа аргументов. Все соответствующие аргументы в вызове функции упаковываются в кортеж, на который функция может ссылаться по заданному имени параметра. Вот пример:
>>> def f(*args):
... print(args)
... print(type(args), len(args))
... for x in args:
... print(x)
...
>>> f(1, 2, 3)
(1, 2, 3)
<class 'tuple'> 3
1
2
3
>>> f('foo', 'bar', 'baz', 'qux', 'quux')
('foo', 'bar', 'baz', 'qux', 'quux')
<class 'tuple'> 5
foo
bar
baz
qux
quux
В определении f() спецификация параметра *args указывает на упаковку кортежей. При каждом вызове f() аргументы упаковываются в кортеж, на который функция может ссылаться по имени args. Можно использовать любое имя, но args настолько часто выбирается, что это практически стандарт.
Используя упаковку кортежей, вы можете очистить avg() следующим образом:
>>> def avg(*args):
... total = 0
... for i in args:
... total += i
... return total / len(args)
...
>>> avg(1, 2, 3)
2.0
>>> avg(1, 2, 3, 4, 5)
3.0
Еще лучше, если вы еще больше усовершенствуете его, заменив цикл for встроенной функцией Python sum(), которая суммирует числовые значения в любой итерируемой таблице:
>>> def avg(*args):
... return sum(args) / len(args)
...
>>> avg(1, 2, 3)
2.0
>>> avg(1, 2, 3, 4, 5)
3.0
Теперь, avg() написан лаконично и работает как надо.
Тем не менее, в зависимости от того, как будет использоваться этот код, возможно, еще есть над чем поработать. Как написано, avg() будет выдавать исключение TypeError, если какие-либо аргументы не являются числовыми:
>>> avg(1, 'foo', 3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in avg
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Для обеспечения максимальной надежности следует добавить код для проверки того, что аргументы имеют правильный тип. Позже в этой серии уроков вы узнаете, как отлавливать исключения типа TypeError и обрабатывать их соответствующим образом. Вы также можете ознакомиться с Python Exceptions: Введение.
Распаковка кортежа аргументов
Аналогичная операция доступна с другой стороны уравнения в вызове функции Python. Если перед аргументом в вызове функции стоит звездочка (*), это означает, что аргумент представляет собой кортеж, который следует распаковать и передать в функцию в виде отдельных значений:
>>> def f(x, y, z):
... print(f'x = {x}')
... print(f'y = {y}')
... print(f'z = {z}')
...
>>> f(1, 2, 3)
x = 1
y = 2
z = 3
>>> t = ('foo', 'bar', 'baz')
>>> f(*t)
x = foo
y = bar
z = baz
В этом примере *t в вызове функции указывает, что t - это кортеж, который необходимо распаковать. Распакованные значения 'foo', 'bar' и 'baz' присваиваются параметрам x, y и z соответственно.
Хотя этот тип распаковки называется кортеж распаковкой, он работает не только с кортежами. Оператор звездочка (*) может быть применен к любой итерируемой переменной в вызове функции Python. Например, список list или набор set также можно распаковать:
>>> a = ['foo', 'bar', 'baz']
>>> type(a)
<class 'list'>
>>> f(*a)
x = foo
y = bar
z = baz
>>> s = {1, 2, 3}
>>> type(s)
<class 'set'>
>>> f(*s)
x = 1
y = 2
z = 3
Вы даже можете использовать упаковку и распаковку кортежей одновременно:
>>> def f(*args):
... print(type(args), args)
...
>>> a = ['foo', 'bar', 'baz', 'qux']
>>> f(*a)
<class 'tuple'> ('foo', 'bar', 'baz', 'qux')
Здесь f(*a) указывает, что список a должен быть распакован, а элементы переданы в f() как отдельные значения. Спецификация параметра *args заставляет упаковать значения обратно в кортеж args.
Упаковка словаря аргументов
В Python есть похожий оператор, двойная звездочка (**), который можно использовать с параметрами и аргументами функций Python, чтобы указать упаковку и распаковку словаря. Предшествование параметру в определении функции Python двойной звездочки (**) указывает, что соответствующие аргументы, которые, как ожидается, являются парами key=value, должны быть упакованы в словарь:
>>> def f(**kwargs):
... print(kwargs)
... print(type(kwargs))
... for key, val in kwargs.items():
... print(key, '->', val)
...
>>> f(foo=1, bar=2, baz=3)
{'foo': 1, 'bar': 2, 'baz': 3}
<class 'dict'>
foo -> 1
bar -> 2
baz -> 3
В этом случае аргументы foo=1, bar=2 и baz=3 упаковываются в словарь, на который функция может ссылаться по имени kwargs. Опять же, можно использовать любое имя, но своеобразное kwargs (которое является сокращением от keyword args) является почти стандартным. Вы не обязаны придерживаться его, но если вы его придерживаетесь, то любой человек, знакомый с соглашениями кодирования Python, сразу поймет, что вы имеете в виду.
Распаковка словаря аргументов
Распаковка словаря аргументов аналогична распаковке кортежа аргументов. Когда двойная звездочка (**) предшествует аргументу в вызове функции Python, это означает, что аргумент является словарем, который должен быть распакован, а полученные элементы переданы в функцию как аргументы ключевого слова:
>>> def f(a, b, c):
... print(F'a = {a}')
... print(F'b = {b}')
... print(F'c = {c}')
...
>>> d = {'a': 'foo', 'b': 25, 'c': 'qux'}
>>> f(**d)
a = foo
b = 25
c = qux
Элементы словаря d распаковываются и передаются в f() в качестве аргументов ключевых слов. Так, f(**d) эквивалентен f(a='foo', b=25, c='qux'):
>>> f(a='foo', b=25, c='qux')
a = foo
b = 25
c = qux
На самом деле, посмотрите на это:
>>> f(**dict(a='foo', b=25, c='qux'))
a = foo
b = 25
c = qux
Здесь dict(a='foo', b=25, c='qux') создает словарь из указанных пар ключ/значение. Затем оператор двойной звездочки (**) распаковывает его и передает ключевые слова в f().
Собираем все вместе
Рассматривайте *args как список позиционных аргументов переменной длины, а **kwargs как список аргументов ключевых слов переменной длины.
Примечание: Для более подробного ознакомления с *args и **kwargs смотрите Python args and kwargs: Demystified.
Все три стандартных позиционных параметра, *args и **kwargs, могут быть использованы в одном определении функции Python. Если это так, то их следует указывать в таком порядке:
>>> def f(a, b, *args, **kwargs):
... print(F'a = {a}')
... print(F'b = {b}')
... print(F'args = {args}')
... print(F'kwargs = {kwargs}')
...
>>> f(1, 2, 'foo', 'bar', 'baz', 'qux', x=100, y=200, z=300)
a = 1
b = 2
args = ('foo', 'bar', 'baz', 'qux')
kwargs = {'x': 100, 'y': 200, 'z': 300}
Это обеспечивает такую гибкость, какая только может понадобиться в интерфейсе функции!
Многочисленные распаковки при вызове функции Python
В версии 3.5 Python появилась поддержка дополнительных обобщений распаковки, как описано в PEP 448. Одно из этих усовершенствований позволяет выполнять несколько распаковок за один вызов функции Python:
>>> def f(*args):
... for i in args:
... print(i)
...
>>> a = [1, 2, 3]
>>> t = (4, 5, 6)
>>> s = {7, 8, 9}
>>> f(*a, *t, *s)
1
2
3
4
5
6
8
9
7
Вы можете указать несколько распаковок словарей в вызове функции Python, а также:
>>> def f(**kwargs):
... for k, v in kwargs.items():
... print(k, '->', v)
...
>>> d1 = {'a': 1, 'b': 2}
>>> d2 = {'x': 3, 'y': 4}
>>> f(**d1, **d2)
a -> 1
b -> 2
x -> 3
y -> 4
Примечание: Это улучшение доступно только в Python версии 3.5 или более поздней. Если вы попробуете сделать это в более ранней версии, то получите SyntaxError исключение.
Кстати, операторы распаковки * и ** применяются не только к переменным, как в примерах выше. Вы также можете использовать их с литералами, которые являются итерируемыми:
>>> def f(*args):
... for i in args:
... print(i)
...
>>> f(*[1, 2, 3], *[4, 5, 6])
1
2
3
4
5
6
>>> def f(**kwargs):
... for k, v in kwargs.items():
... print(k, '->', v)
...
>>> f(**{'a': 1, 'b': 2}, **{'x': 3, 'y': 4})
a -> 1
b -> 2
x -> 3
y -> 4
Здесь литеральные списки [1, 2, 3] и [4, 5, 6] указаны для распаковки кортежей, а литеральные словари {'a': 1, 'b': 2} и {'x': 3, 'y': 4} - для распаковки словарей.
Аргументы только для ключевых слов
Функция Python версии 3.x может быть определена таким образом, что она принимает аргументы только для ключевых слов. Это аргументы функции, которые должны быть указаны ключевым словом. Давайте рассмотрим ситуацию, в которой это может быть полезно.
Предположим, вы хотите написать функцию Python, которая принимает переменное количество строковых аргументов, конкатенирует их вместе, разделяя точкой ("."), и печатает их на консоли. Для начала подойдет что-то вроде этого:
>>> def concat(*args):
... print(f'-> {".".join(args)}')
...
>>> concat('a', 'b', 'c')
-> a.b.c
>>> concat('foo', 'bar', 'baz', 'qux')
-> foo.bar.baz.qux
В существующем виде префикс вывода жестко закодирован в строку '-> '. Что если вы хотите модифицировать функцию, чтобы она принимала и этот аргумент, и пользователь мог указать что-то другое? Вот одна из возможностей:
>>> def concat(prefix, *args):
... print(f'{prefix}{".".join(args)}')
...
>>> concat('//', 'a', 'b', 'c')
//a.b.c
>>> concat('... ', 'foo', 'bar', 'baz', 'qux')
... foo.bar.baz.qux
Это работает, как заявлено в рекламе, но есть несколько нежелательных моментов в этом решении:
-
Строка
prefixобъединяется со строками, подлежащими конкатенации. Из вызова функции не ясно, что первый аргумент обрабатывается иначе, чем остальные. Чтобы узнать это, нужно вернуться и посмотреть на определение функции. -
prefixне является необязательным. Она всегда должна быть включена, и нет никакого способа принять значение по умолчанию.
Вы можете подумать, что вторую проблему можно решить, указав параметр со значением по умолчанию, например, так:
>>> def concat(prefix='-> ', *args):
... print(f'{prefix}{".".join(args)}')
...
К сожалению, это работает не совсем правильно. prefix - это позиционный параметр, поэтому интерпретатор предполагает, что первый аргумент, указанный в вызове функции, является предполагаемым выходным префиксом. Это означает, что нет никакого способа опустить его и получить значение по умолчанию:
>>> concat('a', 'b', 'c')
ab.c
Что делать, если вы пытаетесь указать prefix в качестве аргумента ключевого слова? Ну, вы не можете указать его первым:
>>> concat(prefix='//', 'a', 'b', 'c')
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument
Как вы видели ранее, когда задаются оба типа аргументов, все позиционные аргументы должны идти перед любыми аргументами ключевых слов.
Однако, вы также не можете указать его последним:
>>> concat('a', 'b', 'c', prefix='... ')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: concat() got multiple values for argument 'prefix'
Опять же, prefix - это позиционный параметр, поэтому ему присваивается первый аргумент, указанный в вызове (в данном случае это 'a'). Затем, когда он снова указывается в качестве аргумента ключевого слова в конце, Python думает, что он был присвоен дважды.
Параметры только для ключей помогают решить эту дилемму. В определении функции укажите *args, чтобы обозначить переменное число позиционных аргументов, а затем укажите prefix после этого:
>>> def concat(*args, prefix='-> '):
... print(f'{prefix}{".".join(args)}')
...
В этом случае prefix становится параметром только для ключевого слова. Его значение никогда не будет заполнено позиционным аргументом. Его можно задать только именованным аргументом ключевого слова:
>>> concat('a', 'b', 'c', prefix='... ')
... a.b.c
Обратите внимание, что это возможно только в Python 3. В версиях Python 2.x указание дополнительных параметров после параметра *args переменных аргументов приводит к ошибке.
Аргументы только для ключевых слов позволяют функции Python принимать переменное количество аргументов, за которыми следует один или несколько дополнительных опций в качестве аргументов для ключевых слов. Если вы хотите модифицировать concat() таким образом, чтобы символ разделителя также можно было указывать по желанию, то вы можете добавить дополнительный аргумент только для ключевого слова:
>>> def concat(*args, prefix='-> ', sep='.'):
... print(f'{prefix}{sep.join(args)}')
...
>>> concat('a', 'b', 'c')
-> a.b.c
>>> concat('a', 'b', 'c', prefix='//')
//a.b.c
>>> concat('a', 'b', 'c', prefix='//', sep='-')
//a-b-c
Если в определении функции параметр с ключевым словом имеет значение по умолчанию (как в приведенном выше примере), а при вызове функции ключевое слово опущено, то передается значение по умолчанию:
>>> concat('a', 'b', 'c')
-> a.b.c
Если же параметр не имеет значения по умолчанию, то он становится обязательным, и его неуказание приводит к ошибке:
>>> def concat(*args, prefix):
... print(f'{prefix}{".".join(args)}')
...
>>> concat('a', 'b', 'c', prefix='... ')
... a.b.c
>>> concat('a', 'b', 'c')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: concat() missing 1 required keyword-only argument: 'prefix'
Что делать, если вы хотите определить функцию Python, которая принимает аргумент, состоящий только из ключевых слов, но не принимает переменное количество позиционных аргументов? Например, следующая функция выполняет указанную операцию над двумя числовыми аргументами:
>>> def oper(x, y, op='+'):
... if op == '+':
... return x + y
... elif op == '-':
... return x - y
... elif op == '/':
... return x / y
... else:
... return None
...
>>> oper(3, 4)
7
>>> oper(3, 4, '+')
7
>>> oper(3, 4, '/')
0.75
Если бы вы хотели сделать op параметром только для ключевого слова, то вы могли бы добавить посторонний фиктивный параметр переменного аргумента и просто игнорировать его:
>>> def oper(x, y, *ignore, op='+'):
... if op == '+':
... return x + y
... elif op == '-':
... return x - y
... elif op == '/':
... return x / y
... else:
... return None
...
>>> oper(3, 4, op='+')
7
>>> oper(3, 4, op='/')
0.75
Проблема с этим решением заключается в том, что *ignore поглощает любые посторонние позиционные аргументы, которые могут быть включены:
>>> oper(3, 4, "I don't belong here")
7
>>> oper(3, 4, "I don't belong here", op='/')
0.75
В данном примере лишний аргумент не должен присутствовать (о чем сообщает сам аргумент). Вместо того чтобы спокойно преуспеть, он действительно должен привести к ошибке. То, что этого не происходит, в лучшем случае нечистоплотно. В худшем случае это может привести к результату, который покажется вводящим в заблуждение:
>>> oper(3, 4, '/')
7
Чтобы исправить это, в версии 3 параметр переменного аргумента в определении функции Python может быть просто голой звездочкой (*), а имя опущено:
>>> def oper(x, y, *, op='+'):
... if op == '+':
... return x + y
... elif op == '-':
... return x - y
... elif op == '/':
... return x / y
... else:
... return None
...
>>> oper(3, 4, op='+')
7
>>> oper(3, 4, op='/')
0.75
>>> oper(3, 4, "I don't belong here")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: oper() takes 2 positional arguments but 3 were given
>>> oper(3, 4, '+')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: oper() takes 2 positional arguments but 3 were given
Параметр пустого переменного аргумента * указывает на то, что больше нет никаких позиционных параметров. Такое поведение генерирует соответствующие сообщения об ошибках, если указаны дополнительные параметры. Это позволяет использовать параметры только для ключевых слов.
Только позиционные аргументы
Начиная с Python 3.8, параметры функции также могут быть объявлены только позиционно, что означает, что соответствующие аргументы должны быть предоставлены позиционно и не могут быть указаны ключевым словом.
Чтобы обозначить некоторые параметры только как позиционные, в списке параметров определения функции указывается голая косая черта (/). Любые параметры слева от косой черты (/) должны быть указаны позиционно. Например, в следующем определении функции параметры x и y являются позиционными, но z может быть указан ключевым словом:
>>> # This is Python 3.8
>>> def f(x, y, /, z):
... print(f'x: {x}')
... print(f'y: {y}')
... print(f'z: {z}')
...
Это означает, что следующие вызовы действительны:
>>> f(1, 2, 3)
x: 1
y: 2
z: 3
>>> f(1, 2, z=3)
x: 1
y: 2
z: 3
Однако следующий вызов f() не является корректным:
>>> f(x=1, y=2, z=3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() got some positional-only arguments passed as keyword arguments:
'x, y'
Обозначения "только позиция" и "только ключевое слово" могут использоваться в одном и том же определении функции:
>>> # This is Python 3.8
>>> def f(x, y, /, z, w, *, a, b):
... print(x, y, z, w, a, b)
...
>>> f(1, 2, z=3, w=4, a=5, b=6)
1 2 3 4 5 6
>>> f(1, 2, 3, w=4, a=5, b=6)
1 2 3 4 5 6
В этом примере:
xиy- только позиционные.aиbтолько для ключевых слов.zиwмогут быть указаны позиционно или по ключевому слову.
Для получения дополнительной информации о позиционных параметрах смотрите Python 3.8 release highlights и What Are Python Asterisk and Slash Special Parameters For? tutorial.
Docstrings
Когда первый оператор в теле функции Python представляет собой строковый литерал, он называется docstring функции. Док-строка используется для предоставления документации к функции. Она может содержать назначение функции, аргументы, которые она принимает, информацию о возвращаемых значениях или любую другую информацию, которую вы считаете полезной.
Ниже приведен пример определения функции с docstring:
>>> def avg(*args):
... """Returns the average of a list of numeric values."""
... return sum(args) / len(args)
...
Технически в строках документов можно использовать любой из механизмов кавычек Python, но рекомендуется использовать тройные кавычки, используя символы двойных кавычек ("""), как показано выше. Если строка документа умещается в одной строке, то закрывающие кавычки должны находиться на той же строке, что и открывающие кавычки.
Для более длинной документации используются многострочные документообороты. Многострочная документальная строка должна состоять из итоговой строки, за которой следует пустая строка, а затем более подробное описание. Закрывающие кавычки должны располагаться в отдельной строке:
>>> def foo(bar=0, baz=1):
... """Perform a foo transformation.
...
... Keyword arguments:
... bar -- magnitude along the bar axis (default=0)
... baz -- magnitude along the baz axis (default=1)
... """
... <function_body>
...
Форматирование строк и семантические соглашения подробно описаны в PEP 257.
Когда docstring определена, интерпретатор Python присваивает ее специальному атрибуту функции, называемому __doc__. Этот атрибут является одним из множества специализированных идентификаторов в Python, которые иногда называют магическими атрибутами или магическими методами, поскольку они обеспечивают особую функциональность языка.
Примечание: Эти атрибуты также называют красочными прозвищами dunder attributes и dunder methods. Слово dunder сочетает в себе d от double и under от underscore (_). В последующих уроках этой серии вы встретите еще много атрибутов и методов dunder.
Вы можете получить доступ к docstring функции с помощью выражения <function_name>.__doc__. Док-строки для приведенных выше примеров можно отобразить следующим образом:
>>> print(avg.__doc__)
Returns the average of a list of numeric values.
>>> print(foo.__doc__)
Perform a foo transformation.
Keyword arguments:
bar -- magnitude along the bar axis (default=0)
baz -- magnitude along the baz axis (default=1)
В интерактивном интерпретаторе Python вы можете набрать help(<function_name>), чтобы отобразить строку документации для <function_name>:
>>> help(avg)
Help on function avg in module __main__:
avg(*args)
Returns the average of a list of numeric values.
>>> help(foo)
Help on function foo in module __main__:
foo(bar=0, baz=1)
Perform a foo transformation.
Keyword arguments:
bar -- magnitude along the bar axis (default=0)
baz -- magnitude along the baz axis (default=1)
Считается хорошей практикой кодирования указывать docstring для каждой функции Python, которую вы определяете. Подробнее о doc-строках читайте в Documenting Python Code: Полное руководство.
Аннотации функций Python
Начиная с версии 3.0, Python предоставляет дополнительную возможность документирования функции, называемую аннотацией функции. Аннотации позволяют прикреплять метаданные к параметрам и возвращаемому значению функции.
Чтобы добавить аннотацию к параметру функции Python, вставьте двоеточие (:), за которым следует любое выражение после имени параметра в определении функции. Чтобы добавить аннотацию к возвращаемому значению, добавьте символы -> и любое выражение между закрывающей скобкой списка параметров и двоеточием, завершающим заголовок функции. Вот пример:
>>> def f(a: '<a>', b: '<b>') -> '<ret_value>':
... pass
...
Аннотация для параметра a - строка '<a>', для b - строка '<b>', а для возвращаемого значения функции - строка '<ret_value>'.
Интерпретатор Python создает словарь из аннотаций и присваивает их другому специальному атрибуту dunder функции под названием __annotations__. Аннотации для функции Python f(), показанной выше, могут быть представлены следующим образом:
>>> f.__annotations__
{'a': '<a>', 'b': '<b>', 'return': '<ret_value>'}
Ключами для параметров являются имена параметров. Ключом для возвращаемого значения является строка 'return':
>>> f.__annotations__['a']
'<a>'
>>> f.__annotations__['b']
'<b>'
>>> f.__annotations__['return']
'<ret_value>'
Обратите внимание, что аннотации не ограничиваются строковыми значениями. Это может быть любое выражение или объект. Например, вы можете аннотировать объекты типа:
>>> def f(a: int, b: str) -> float:
... print(a, b)
... return(3.5)
...
>>> f(1, 'foo')
1 foo
3.5
>>> f.__annotations__
{'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
Аннотация может быть даже составным объектом, например списком или словарем, поэтому можно прикрепить несколько элементов метаданных к параметрам и возвращаемому значению:
>>> def area(
... r: {
... 'desc': 'radius of circle',
... 'type': float
... }) -> \
... {
... 'desc': 'area of circle',
... 'type': float
... }:
... return 3.14159 * (r ** 2)
...
>>> area(2.5)
19.6349375
>>> area.__annotations__
{'r': {'desc': 'radius of circle', 'type': <class 'float'>},
'return': {'desc': 'area of circle', 'type': <class 'float'>}}
>>> area.__annotations__['r']['desc']
'radius of circle'
>>> area.__annotations__['return']['type']
<class 'float'>
В приведенном выше примере аннотация прикреплена к параметру r и возвращаемому значению. Каждая аннотация представляет собой словарь, содержащий строковое описание и объект типа.
Если вы хотите присвоить значение по умолчанию параметру, который имеет аннотацию, то значение по умолчанию идет после аннотации:
>>> def f(a: int = 12, b: str = 'baz') -> float:
... print(a, b)
... return(3.5)
...
>>> f.__annotations__
{'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
>>> f()
12 baz
3.5
Что делают аннотации? Честно говоря, они почти ничего не делают. Они просто как бы присутствуют. Давайте снова рассмотрим один из примеров, приведенных выше, но с небольшими изменениями:
>>> def f(a: int, b: str) -> float:
... print(a, b)
... return 1, 2, 3
...
>>> f('foo', 2.5)
foo 2.5
(1, 2, 3)
Что здесь происходит? В аннотации к f() указано, что первым аргументом является int, вторым аргументом str, а возвращаемым значением float. Но последующий вызов f() нарушает все правила! Аргументами являются str и float соответственно, а возвращаемое значение - кортеж. Тем не менее интерпретатор пропускает все это без каких-либо претензий.
Аннотации не накладывают на код никаких семантических ограничений. Это просто кусочки метаданных, прикрепленные к параметрам и возвращаемому значению функции Python. Python послушно складывает их в словарь, присваивает словарь атрибуту __annotations__ dunder функции, и все. Аннотации совершенно необязательны и не оказывают никакого влияния на выполнение функции Python.
Цитируя Амаля из "Амаль и ночные гости", "Что толку тогда иметь его?"
Для начала, аннотации делают хорошую документацию. Конечно, вы можете указать ту же информацию в строке документации, но размещение ее непосредственно в определении функции добавляет ясности. Типы аргументов и возвращаемого значения очевидны с первого взгляда для такого заголовка функции:
def f(a: int, b: str) -> float:
Согласен, интерпретатор не следит за соблюдением указанных типов, но, по крайней мере, они понятны тому, кто читает определение функции.
Глубокое погружение: Принудительная проверка типов
При желании можно добавить код для принудительной проверки типов, указанных в аннотациях к функциям. Вот функция, которая сверяет фактический тип каждого аргумента с тем, что указан в аннотации для соответствующего параметра. Она выводит
True, если они совпадают, иFalse, если не совпадают:>>> def f(a: int, b: str, c: float): ... import inspect ... args = inspect.getfullargspec(f).args ... annotations = inspect.getfullargspec(f).annotations ... for x in args: ... print(x, '->', ... 'arg is', type(locals()[x]), ',', ... 'annotation is', annotations[x], ... '/', (type(locals()[x])) is annotations[x]) ... >>> f(1, 'foo', 3.3) a -> arg is <class 'int'> , annotation is <class 'int'> / True b -> arg is <class 'str'> , annotation is <class 'str'> / True c -> arg is <class 'float'> , annotation is <class 'float'> / True >>> f('foo', 4.3, 9) a -> arg is <class 'str'> , annotation is <class 'int'> / False b -> arg is <class 'float'> , annotation is <class 'str'> / False c -> arg is <class 'int'> , annotation is <class 'float'> / False >>> f(1, 'foo', 'bar') a -> arg is <class 'int'> , annotation is <class 'int'> / True b -> arg is <class 'str'> , annotation is <class 'str'> / True c -> arg is <class 'str'> , annotation is <class 'float'> / False(Модуль
inspectсодержит функции, которые получают полезную информацию о живых объектах, в данном случае функциюf().)Функция, определенная подобно приведенной выше, при желании может предпринять какие-то корректирующие действия, когда обнаружит, что переданные аргументы не соответствуют типам, указанным в аннотациях.
Фактически, схема использования аннотаций для выполнения статической проверки типов в Python описана в PEP 484. Существует бесплатная статическая программа проверки типов для Python под названием mypy, которая построена на основе спецификации PEP 484.
Есть и еще одно преимущество использования аннотаций. Стандартизированный формат, в котором аннотационная информация хранится в атрибуте __annotations__, позволяет автоматическим инструментам разбирать сигнатуры функций.
Когда дело доходит до дела, аннотации не представляют собой ничего особенно волшебного. Вы даже можете определить свои собственные без специального синтаксиса, который предоставляет Python. Вот определение функции Python с аннотациями типа object, прикрепленными к параметрам и возвращаемому значению:
>>> def f(a: int, b: str) -> float:
... return
...
>>> f.__annotations__
{'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
Ниже приведена по сути та же самая функция, причем словарь __annotations__ построен вручную:
>>> def f(a, b):
... return
...
>>> f.__annotations__ = {'a': int, 'b': str, 'return': float}
>>> f.__annotations__
{'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
Эффект в обоих случаях одинаков, но первый вариант более привлекателен и читабелен на первый взгляд.
На самом деле, атрибут __annotations__ не сильно отличается от большинства других атрибутов функции. Например, он может быть изменен динамически. Вы можете использовать атрибут возвращаемого значения для подсчета того, сколько раз выполняется функция:
>>> def f() -> 0:
... f.__annotations__['return'] += 1
... print(f"f() has been executed {f.__annotations__['return']} time(s)")
...
>>> f()
f() has been executed 1 time(s)
>>> f()
f() has been executed 2 time(s)
>>> f()
f() has been executed 3 time(s)
Аннотации функций Python - это не что иное, как словари метаданных. Просто так получилось, что вы можете создавать их с удобным синтаксисом, который поддерживается интерпретатором. Они представляют собой все, что вы решите из них сделать.
Заключение
По мере роста приложений становится все более важным модулировать код, разбивая его на более мелкие функции управляемого размера. Надеюсь, теперь у вас есть все необходимые для этого инструменты.
Вы узнали:
- Как создать определенную пользователем функцию в Python
- Существует несколько различных способов передачи аргументов в функцию
- Как можно возвращатьданные из функции вызывающему ее пользователю
- Как добавить документацию к функциям с помощью docstrings и annotations
Следующими в этой серии будут два урока, посвященные поиску и сопоставлению шаблонов. Вы подробно рассмотрите модуль Python под названием re, который содержит функциональность для поиска и сопоставления с использованием универсального синтаксиса шаблонов, называемого регулярным выражением.
Вернуться на верх