Классы данных в Python
Оглавление
- Альтернативы классам данных
- Базовые классы данных
- Более гибкие классы данных
- Взаимозаменяемые классы данных
- Наследование
- Оптимизация классов данных
- Заключение и дальнейшее чтение
Одной из новых и интересных возможностей, появившихся в Python 3.7, является класс данных. Класс данных - это класс, обычно содержащий в основном данные, хотя на самом деле нет никаких ограничений. Он создается с помощью нового декоратора @dataclass следующим образом:
from dataclasses import dataclass
@dataclass
class DataClassCard:
rank: str
suit: str
Примечание: Этот код, как и все остальные примеры в этом руководстве, будет работать только в Python 3.7 и выше.
Класс данных поставляется с уже реализованной базовой функциональностью. Например, вы можете инстанцировать, печатать и сравнивать экземпляры класса данных прямо из коробки:
>>> queen_of_hearts = DataClassCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
DataClassCard(rank='Q', suit='Hearts')
>>> queen_of_hearts == DataClassCard('Q', 'Hearts')
True
Сравните это с обычным классом. Минимальный обычный класс будет выглядеть примерно так:
class RegularCard:
def __init__(self, rank, suit):
self.rank = rank
self.suit = suit
Хотя это не намного больше кода, который нужно написать, вы уже можете увидеть признаки боли от шаблонов: rank и suit повторяются три раза, просто чтобы инициализировать объект. Кроме того, если вы попробуете использовать этот простой класс, то заметите, что представление объектов не очень наглядно, и по какой-то причине червонная королева - это не то же самое, что королева червей:
>>> queen_of_hearts = RegularCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
<__main__.RegularCard object at 0x7fb6eee35d30>
>>> queen_of_hearts == RegularCard('Q', 'Hearts')
False
Похоже, что классы данных помогают нам за кулисами. По умолчанию классы данных реализуют метод .__repr__() для обеспечения красивого представления строк и метод .__eq__(), который может выполнять базовые сравнения объектов. Чтобы класс RegularCard имитировал вышеупомянутый класс данных, необходимо добавить следующие методы:
class RegularCard
def __init__(self, rank, suit):
self.rank = rank
self.suit = suit
def __repr__(self):
return (f'{self.__class__.__name__}'
f'(rank={self.rank!r}, suit={self.suit!r})')
def __eq__(self, other):
if other.__class__ is not self.__class__:
return NotImplemented
return (self.rank, self.suit) == (other.rank, other.suit)
В этом уроке вы узнаете, какие именно удобства предоставляют классы данных. Помимо красивых представлений и сравнений, вы увидите:
- Как добавить значения по умолчанию в поля класса данных
- Как классы данных позволяют упорядочивать объекты
- Как представлять неизменяемые данные
- Как классы данных работают с наследованием
Вскоре мы более подробно рассмотрим эти особенности классов данных. Однако вам может показаться, что вы уже видели нечто подобное раньше.
Альтернативы классам данных
Для простых структур данных вы, вероятно, уже использовали a tuple или dict. Карту "Королева червей" можно представить одним из следующих способов:
>>> queen_of_hearts_tuple = ('Q', 'Hearts')
>>> queen_of_hearts_dict = {'rank': 'Q', 'suit': 'Hearts'}
Это работает. Однако это накладывает большую ответственность на вас как на программиста:
- Вам нужно запомнить, что
queen_of_hearts_...переменная представляет собой карту. - Для версии
tupleнеобходимо запомнить порядок атрибутов. Написание('Spades', 'A')приведет к сбоям в вашей программе, но, вероятно, не даст вам легко понятного сообщения об ошибке. - Если вы используете версию
dict, вы должны убедиться, что имена атрибутов совпадают. Например,{'value': 'A', 'suit': 'Spades'}будет работать не так, как ожидалось.
Кроме того, использование этих структур не является идеальным:
>>> queen_of_hearts_tuple[0] # No named access
'Q'
>>> queen_of_hearts_dict['suit'] # Would be nicer with .suit
'Hearts'
Лучшей альтернативой является namedtuple. Он уже давно используется для создания читаемых небольших структур данных. Мы можем воссоздать пример класса данных, приведенный выше, используя namedtuple следующим образом:
from collections import namedtuple
NamedTupleCard = namedtuple('NamedTupleCard', ['rank', 'suit'])
Это определение NamedTupleCard даст точно такой же результат, как и наш пример DataClassCard:
>>> queen_of_hearts = NamedTupleCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
NamedTupleCard(rank='Q', suit='Hearts')
>>> queen_of_hearts == NamedTupleCard('Q', 'Hearts')
True
Так зачем вообще беспокоиться о классах данных? Прежде всего, классы данных имеют гораздо больше возможностей, чем вы видели до сих пор. В то же время у namedtuple есть и другие особенности, которые не всегда желательны. По своей конструкции namedtuple представляет собой обычный кортеж. Это можно увидеть в сравнениях, например:
>>> queen_of_hearts == ('Q', 'Hearts')
True
Хотя это может показаться хорошей вещью, такое незнание своего собственного типа может привести к тонким и труднонаходимым ошибкам, тем более что он также с удовольствием сравнит два разных namedtuple класса:
>>> Person = namedtuple('Person', ['first_initial', 'last_name']
>>> ace_of_spades = NamedTupleCard('A', 'Spades')
>>> ace_of_spades == Person('A', 'Spades')
True
На namedtuple также накладываются некоторые ограничения. Например, в namedtuple трудно добавить значения по умолчанию к некоторым полям. По своей природе namedtuple также является неизменяемым. То есть значение namedtuple никогда не может измениться. В некоторых приложениях это замечательная возможность, но в других ситуациях было бы неплохо иметь больше гибкости:
>>> card = NamedTupleCard('7', 'Diamonds')
>>> card.rank = '9'
AttributeError: can't set attribute
Классы данных не заменят все случаи использования namedtuple. Например, если вам нужно, чтобы структура данных вела себя как кортеж, то именованный кортеж - отличная альтернатива!
Другой альтернативой и одним из вдохновителей создания классов данных является проект attrs. Установив attrs (pip install attrs), вы можете написать класс карты следующим образом:
import attr
@attr.s
class AttrsCard:
rank = attr.ib()
suit = attr.ib()
Это можно использовать точно так же, как и приведенные ранее примеры DataClassCard и NamedTupleCard. Проект attrs замечательный и поддерживает некоторые возможности, которых нет у классов данных, включая конвертеры и валидаторы. Кроме того, attrs существует уже давно и поддерживается в Python 2.7, а также в Python 3.4 и выше. Однако, поскольку attrs не является частью стандартной библиотеки, он добавляет в ваши проекты внешнюю зависимость. С помощью классов данных подобная функциональность будет доступна повсеместно.
Помимо tuple, dict, namedtuple и attrs, существует множество других подобных проектов, включая typing.NamedTuple, namedlist, attrdict, plumber, и fields. Хотя классы данных - это отличная новая альтернатива, все же есть случаи, когда один из старых вариантов подходит лучше. Например, если вам нужна совместимость с конкретным API, ожидающим кортежи, или нужна функциональность, не поддерживаемая в классах данных.
Базовые классы данных
Давайте вернемся к классам данных. В качестве примера мы создадим класс Position, который будет представлять географические позиции с именем, а также широтой и долготой:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float
lat: float
Что делает его классом данных, так это декоратор @dataclass, расположенный прямо над определением класса. Под строкой class Position: вы просто перечисляете поля, которые вы хотите видеть в своем классе данных. Нотация :, используемая для полей, использует новую возможность в Python 3.6, называемую аннотациями переменных. Мы позже поговорим подробнее об этой нотации и о том, почему мы указываем такие типы данных, как str и float.
Эти несколько строк кода - все, что вам нужно. Новый класс готов к использованию:
>>> pos = Position('Oslo', 10.8, 59.9)
>>> print(pos)
Position(name='Oslo', lon=10.8, lat=59.9)
>>> pos.lat
59.9
>>> print(f'{pos.name} is at {pos.lat}°N, {pos.lon}°E')
Oslo is at 59.9°N, 10.8°E
Вы также можете создавать классы данных аналогично тому, как создаются именованные кортежи. Следующее определение (почти) эквивалентно определению Position, приведенному выше:
from dataclasses import make_dataclass
Position = make_dataclass('Position', ['name', 'lat', 'lon'])
Класс данных - это обычный Python-класс. Единственное, что отличает его от других, это то, что в нем реализованы основные методы модели данных, такие как .__init__(), .__repr__() и .__eq__().
Значения по умолчанию
Легко добавить значения по умолчанию в поля вашего класса данных:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
Это работает точно так же, как если бы вы указали значения по умолчанию в определении метода .__init__() обычного класса:
>>> Position('Null Island')
Position(name='Null Island', lon=0.0, lat=0.0)
>>> Position('Greenwich', lat=51.8)
Position(name='Greenwich', lon=0.0, lat=51.8)
>>> Position('Vancouver', -123.1, 49.3)
Position(name='Vancouver', lon=-123.1, lat=49.3)
Позже вы узнаете о default_factory, который дает возможность предоставлять более сложные значения по умолчанию.
Тип подсказки
До сих пор мы не придавали большого значения тому факту, что классы данных поддерживают типизацию из коробки. Вы, вероятно, заметили, что мы определили поля с подсказкой типа: name: str говорит, что name должно быть текстовой строкой (str тип).
Фактически, добавление какой-либо подсказки типа является обязательным при определении полей в классе данных. Без подсказки типа поле не будет частью класса данных. Однако если вы не хотите добавлять явные типы в класс данных, используйте typing.Any:
from dataclasses import dataclass
from typing import Any
@dataclass
class WithoutExplicitTypes:
name: Any
value: Any = 42
Хотя при использовании классов данных необходимо добавлять подсказки типов в той или иной форме, эти типы не навязываются во время выполнения. Следующий код выполняется без проблем:
>>> Position(3.14, 'pi day', 2018)
Position(name=3.14, lon='pi day', lat=2018)
Вот как обычно работает типизация в Python: Python есть и всегда будет динамически типизированным языком. Чтобы действительно отлавливать ошибки типов, в исходном коде можно использовать программы проверки типов, такие как Mypy.
Добавление методов
Вы уже знаете, что класс данных - это обычный класс. Это означает, что вы можете свободно добавлять в класс данных свои собственные методы. Например, давайте вычислим расстояние от одной позиции до другой вдоль поверхности Земли. Один из способов сделать это - использовать формулу Гаверсина:
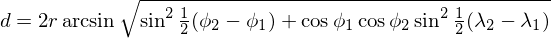
Вы можете добавить метод .distance_to() в свой класс данных, как и в обычные классы:
from dataclasses import dataclass
from math import asin, cos, radians, sin, sqrt
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
def distance_to(self, other):
r = 6371 # Earth radius in kilometers
lam_1, lam_2 = radians(self.lon), radians(other.lon)
phi_1, phi_2 = radians(self.lat), radians(other.lat)
h = (sin((phi_2 - phi_1) / 2)**2
+ cos(phi_1) * cos(phi_2) * sin((lam_2 - lam_1) / 2)**2)
return 2 * r * asin(sqrt(h))
Работает, как и следовало ожидать:
>>> oslo = Position('Oslo', 10.8, 59.9)
>>> vancouver = Position('Vancouver', -123.1, 49.3)
>>> oslo.distance_to(vancouver)
7181.7841229421165
Более гибкие классы данных
До сих пор вы видели некоторые из основных возможностей класса data: он предоставляет вам некоторые удобные методы, и вы можете добавить значения по умолчанию и другие методы. Теперь вы узнаете о некоторых более продвинутых возможностях, таких как параметры декоратора @dataclass и функции field(). Вместе они дают вам больше контроля при создании класса данных.
Вернемся к примеру с игральными картами, который вы видели в начале учебника, и добавим класс, содержащий колоду карт:
from dataclasses import dataclass
from typing import List
@dataclass
class PlayingCard:
rank: str
suit: str
@dataclass
class Deck:
cards: List[PlayingCard]
Простая колода, содержащая всего две карты, может быть создана следующим образом:
>>> queen_of_hearts = PlayingCard('Q', 'Hearts')
>>> ace_of_spades = PlayingCard('A', 'Spades')
>>> two_cards = Deck([queen_of_hearts, ace_of_spades])
Deck(cards=[PlayingCard(rank='Q', suit='Hearts'),
PlayingCard(rank='A', suit='Spades')])
Дополнительные значения по умолчанию
Скажем, вы хотите задать значение по умолчанию для Deck. Например, было бы удобно, если бы Deck() создал регулярную (французскую) колоду из 52 игральных карт. Сначала укажите различные ранги и масти. Затем добавьте функцию make_french_deck(), которая создает список экземпляров PlayingCard:
RANKS = '2 3 4 5 6 7 8 9 10 J Q K A'.split()
SUITS = '♣ ♢ ♡ ♠'.split()
def make_french_deck():
return [PlayingCard(r, s) for s in SUITS for r in RANKS]
Для развлечения четыре различные масти указываются с помощью их символов Unicode.
Примечание: Выше мы использовали глифы Юникода, такие как
♠, непосредственно в исходном коде. Мы могли сделать это, потому что Python поддерживает запись исходного кода в UTF-8 по умолчанию. Обратитесь к этой странице о вводе Юникода, чтобы узнать, как вводить их в вашей системе. Вы также можете ввести символы Юникода для костюмов, используя\Nименованные символьные эскейпы (например,\N{BLACK SPADE SUIT}) или\uэскейпы Юникода (например,\u2660).
Чтобы упростить сравнение карт в дальнейшем, ранги и масти также перечислены в их обычном порядке.
>>> make_french_deck()
[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ...
PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')]
Теоретически, теперь вы можете использовать эту функцию для задания значения по умолчанию для Deck.cards:
from dataclasses import dataclass
from typing import List
@dataclass
class Deck: # Will NOT work
cards: List[PlayingCard] = make_french_deck()
Не делайте этого! Это вводит один из самых распространенных антипаттернов в Python: использование мутабельных аргументов по умолчанию. Проблема заключается в том, что все экземпляры Deck будут использовать один и тот же объект-список в качестве значения по умолчанию свойства .cards. Это означает, что если, скажем, одна карта удаляется из одного Deck, то она исчезает и из всех остальных экземпляров Deck. На самом деле классы данных стараются не дать вам сделать это , и приведенный выше код вызовет ошибку ValueError.
Вместо этого классы данных используют нечто, называемое default_factory, для работы с изменяемыми значениями по умолчанию. Чтобы использовать default_factory (и многие другие возможности классов данных), вам нужно использовать спецификатор field():
from dataclasses import dataclass, field
from typing import List
@dataclass
class Deck:
cards: List[PlayingCard] = field(default_factory=make_french_deck)
Аргументом к default_factory может быть любой вызываемый с нулевым параметром. Теперь легко создать полную колоду игральных карт:
>>> Deck()
Deck(cards=[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ...
PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')])
Спецификатор field() используется для индивидуальной настройки каждого поля класса данных. Другие примеры вы увидите позже. Для справки, вот какие параметры поддерживает field():
default: Значение поля по умолчаниюdefault_factory: Функция, возвращающая начальное значение поляinit: Использовать поле в методе.__init__()? (По умолчаниюTrue.)repr: Использовать поле вreprобъекта? (По умолчаниюTrue.)compare: Включать поле в сравнения? (По умолчаниюTrue.)hash: Включать поле при вычисленииhash()? (По умолчанию используется то же, что и дляcompare.)metadata: Отображение с информацией о поле
В примере Position вы увидели, как добавить простые значения по умолчанию, написав lat: float = 0.0. Однако если вы хотите также настроить поле, например, скрыть его в repr, вам нужно использовать параметр default: lat: float = field(default=0.0, repr=False). Вы не можете указать одновременно default и default_factory.
Параметр
metadata не используется самими классами данных, но может быть использован вами (или сторонними пакетами) для добавления информации к полям. В примере Position можно, например, указать, что широта и долгота должны быть указаны в градусах:
from dataclasses import dataclass, field
@dataclass
class Position:
name: str
lon: float = field(default=0.0, metadata={'unit': 'degrees'})
lat: float = field(default=0.0, metadata={'unit': 'degrees'})
Метаданные (и другую информацию о поле) можно получить с помощью функции fields() (обратите внимание на множественное число s):
>>> from dataclasses import fields
>>> fields(Position)
(Field(name='name',type=<class 'str'>,...,metadata={}),
Field(name='lon',type=<class 'float'>,...,metadata={'unit': 'degrees'}),
Field(name='lat',type=<class 'float'>,...,metadata={'unit': 'degrees'}))
>>> lat_unit = fields(Position)[2].metadata['unit']
>>> lat_unit
'degrees'
Вам нужен представитель?
Вспомните, что мы можем создавать колоды карт из воздуха:
>>> Deck()
Deck(cards=[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ...
PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')])
Хотя такое представление Deck является явным и удобным для чтения, оно также очень многословное. В приведенном выше выводе я удалил 48 из 52 карт в колоде. На 80-колоночном дисплее простая печать полного Deck занимает 22 строки! Давайте добавим более краткое представление. В общем случае объект Python имеет два различных строковых представления:
-
repr(obj)определяетсяobj.__repr__()и должен возвращать удобное для разработчика представлениеobj. Если возможно, это должен быть код, который может воссоздатьobj. Классы данных делают это. -
str(obj)определяетсяobj.__str__()и должен возвращать удобное для пользователя представлениеobj. Классы данных не реализуют метод.__str__(), поэтому Python обратится к методу.__repr__().
Давайте реализуем удобное представление PlayingCard:
from dataclasses import dataclass
@dataclass
class PlayingCard:
rank: str
suit: str
def __str__(self):
return f'{self.suit}{self.rank}'
Теперь карты выглядят гораздо красивее, но колода все так же многословна, как и раньше:
>>> ace_of_spades = PlayingCard('A', '♠')
>>> ace_of_spades
PlayingCard(rank='A', suit='♠')
>>> print(ace_of_spades)
♠A
>>> print(Deck())
Deck(cards=[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ...
PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')])
Чтобы показать, что можно добавить и свой собственный метод .__repr__(), мы нарушим принцип, что он должен возвращать код, который может воссоздать объект. В конце концов, практичность побеждает чистоту. Следующий код добавляет более лаконичное представление метода Deck:
from dataclasses import dataclass, field
from typing import List
@dataclass
class Deck:
cards: List[PlayingCard] = field(default_factory=make_french_deck)
def __repr__(self):
cards = ', '.join(f'{c!s}' for c in self.cards)
return f'{self.__class__.__name__}({cards})'
Обратите внимание на спецификатор !s в строке формата {c!s}. Он означает, что мы явно хотим использовать представление str() для каждого PlayingCard. С новым .__repr__() представление Deck стало проще для глаз:
>>> Deck()
Deck(♣2, ♣3, ♣4, ♣5, ♣6, ♣7, ♣8, ♣9, ♣10, ♣J, ♣Q, ♣K, ♣A,
♢2, ♢3, ♢4, ♢5, ♢6, ♢7, ♢8, ♢9, ♢10, ♢J, ♢Q, ♢K, ♢A,
♡2, ♡3, ♡4, ♡5, ♡6, ♡7, ♡8, ♡9, ♡10, ♡J, ♡Q, ♡K, ♡A,
♠2, ♠3, ♠4, ♠5, ♠6, ♠7, ♠8, ♠9, ♠10, ♠J, ♠Q, ♠K, ♠A)
Это более красивое представление колоды. Однако за это приходится платить. Вы больше не сможете воссоздать колоду, выполнив ее представление. Часто вместо этого лучше реализовать то же представление с помощью .__str__().
Сравнение карт
Во многих карточных играх карты сравниваются друг с другом. Например, в типичной игре на выбивание фокусов самая старшая карта забирает фокус. В текущей реализации класс PlayingCard не поддерживает этот вид сравнения:
>>> queen_of_hearts = PlayingCard('Q', '♡')
>>> ace_of_spades = PlayingCard('A', '♠')
>>> ace_of_spades > queen_of_hearts
TypeError: '>' not supported between instances of 'Card' and 'Card'
Однако это (как кажется) легко исправить:
from dataclasses import dataclass
@dataclass(order=True)
class PlayingCard:
rank: str
suit: str
def __str__(self):
return f'{self.suit}{self.rank}'
Декоратор @dataclass имеет две формы. До сих пор вы видели простую форму, в которой @dataclass задается без скобок и параметров. Однако декоратору @dataclass() можно задать параметры в круглых скобках. Поддерживаются следующие параметры:
init: Добавить метод.__init__()? (По умолчаниюTrue.)repr: Добавить метод.__repr__()? (По умолчаниюTrue.)eq: Добавить метод.__eq__()? (По умолчаниюTrue.)order: Добавить методы упорядочивания? (По умолчаниюFalse.)unsafe_hash: Принудительно добавлять метод.__hash__()? (По умолчаниюFalse.)frozen: ЕслиTrue, присваивание полям вызывает исключение. (По умолчаниюFalse.)
Для получения дополнительной информации о каждом параметре смотрите оригинальный PEP. После установки order=True можно сравнивать экземпляры PlayingCard:
>>> queen_of_hearts = PlayingCard('Q', '♡')
>>> ace_of_spades = PlayingCard('A', '♠')
>>> ace_of_spades > queen_of_hearts
False
Как сравниваются эти две карты? Вы не указали, как следует упорядочивать карты, а Python почему-то считает, что королева выше туза...
Оказывается, классы данных сравнивают объекты так, как если бы они были кортежами своих полей. Другими словами, королева выше туза, потому что 'Q' идет после 'A' в алфавите:
>>> ('A', '♠') > ('Q', '♡')
False
Это не совсем подходит для нас. Вместо этого нам нужно определить некий индекс сортировки, который использует порядок RANKS и SUITS. Что-то вроде этого:
>>> RANKS = '2 3 4 5 6 7 8 9 10 J Q K A'.split()
>>> SUITS = '♣ ♢ ♡ ♠'.split()
>>> card = PlayingCard('Q', '♡')
>>> RANKS.index(card.rank) * len(SUITS) + SUITS.index(card.suit)
42
Для того чтобы PlayingCard использовать этот индекс сортировки для сравнений, нам нужно добавить поле .sort_index в класс. Однако это поле должно вычисляться из других полей .rank и .suit автоматически. Именно для этого и предназначен метод special .__post_init__(). Он позволяет выполнять специальную обработку после вызова обычного метода .__init__():
from dataclasses import dataclass, field
RANKS = '2 3 4 5 6 7 8 9 10 J Q K A'.split()
SUITS = '♣ ♢ ♡ ♠'.split()
@dataclass(order=True)
class PlayingCard:
sort_index: int = field(init=False, repr=False)
rank: str
suit: str
def __post_init__(self):
self.sort_index = (RANKS.index(self.rank) * len(SUITS)
+ SUITS.index(self.suit))
def __str__(self):
return f'{self.suit}{self.rank}'
Обратите внимание, что .sort_index добавляется в качестве первого поля класса. Таким образом, сравнение сначала выполняется с помощью .sort_index и только при наличии связей используются другие поля. Используя field(), вы также должны указать, что .sort_index не должен быть включен в качестве параметра в метод .__init__() (поскольку он вычисляется из полей .rank и .suit). Чтобы не вводить пользователя в заблуждение относительно этой детали реализации, вероятно, также стоит удалить .sort_index из repr класса.
Наконец, тузы высоки:
>>> queen_of_hearts = PlayingCard('Q', '♡')
>>> ace_of_spades = PlayingCard('A', '♠')
>>> ace_of_spades > queen_of_hearts
True
Теперь вы можете легко создавать отсортированные колоды:
>>> Deck(sorted(make_french_deck()))
Deck(♣2, ♢2, ♡2, ♠2, ♣3, ♢3, ♡3, ♠3, ♣4, ♢4, ♡4, ♠4, ♣5,
♢5, ♡5, ♠5, ♣6, ♢6, ♡6, ♠6, ♣7, ♢7, ♡7, ♠7, ♣8, ♢8,
♡8, ♠8, ♣9, ♢9, ♡9, ♠9, ♣10, ♢10, ♡10, ♠10, ♣J, ♢J, ♡J,
♠J, ♣Q, ♢Q, ♡Q, ♠Q, ♣K, ♢K, ♡K, ♠K, ♣A, ♢A, ♡A, ♠A)
Или, если вас не волнует сортировка, вот как вы набираете случайную руку из 10 карт:
>>> from random import sample
>>> Deck(sample(make_french_deck(), k=10))
Deck(♢2, ♡A, ♢10, ♣2, ♢3, ♠3, ♢A, ♠8, ♠9, ♠2)
Конечно, для этого не нужно order=True...
Взаимозаменяемые классы данных
Одной из определяющих особенностей namedtuple, которую вы видели ранее, является то, что она неизменяема. То есть значение его полей никогда не может измениться. Для многих типов классов данных это отличная идея! Чтобы сделать класс данных неизменяемым, установите frozen=True при его создании. Например, ниже представлена неизменяемая версия класса Position , который вы видели ранее:
from dataclasses import dataclass
@dataclass(frozen=True)
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
В замороженном классе данных нельзя присваивать значения полям после создания:
>>> pos = Position('Oslo', 10.8, 59.9)
>>> pos.name
'Oslo'
>>> pos.name = 'Stockholm'
dataclasses.FrozenInstanceError: cannot assign to field 'name'
Однако имейте в виду, что если ваш класс данных содержит изменяемые поля, они все равно могут измениться. Это справедливо для всех вложенных структур данных в Python (см. это видео для получения дополнительной информации):
from dataclasses import dataclass
from typing import List
@dataclass(frozen=True)
class ImmutableCard:
rank: str
suit: str
@dataclass(frozen=True)
class ImmutableDeck:
cards: List[ImmutableCard]
Несмотря на то, что и ImmutableCard, и ImmutableDeck неизменяемы, список, содержащий cards, таковым не является. Поэтому вы все еще можете менять карты в колоде:
>>> queen_of_hearts = ImmutableCard('Q', '♡')
>>> ace_of_spades = ImmutableCard('A', '♠')
>>> deck = ImmutableDeck([queen_of_hearts, ace_of_spades])
>>> deck
ImmutableDeck(cards=[ImmutableCard(rank='Q', suit='♡'), ImmutableCard(rank='A', suit='♠')])
>>> deck.cards[0] = ImmutableCard('7', '♢')
>>> deck
ImmutableDeck(cards=[ImmutableCard(rank='7', suit='♢'), ImmutableCard(rank='A', suit='♠')])
Чтобы избежать этого, убедитесь, что все поля класса неизменяемых данных используют неизменяемые типы (но помните, что типы не принуждаются во время выполнения). ImmutableDeck должен быть реализован с использованием кортежа, а не списка.
Наследство
Вы можете подклассифицировать классы данных совершенно свободно. В качестве примера мы расширим наш пример Position полем country и используем его для записи заглавных букв:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float
lat: float
@dataclass
class Capital(Position):
country: str
В этом простом примере все работает без проблем:
>>> Capital('Oslo', 10.8, 59.9, 'Norway')
Capital(name='Oslo', lon=10.8, lat=59.9, country='Norway')
Поле country из Capital добавляется после трех исходных полей в Position. Все становится немного сложнее, если какие-либо поля базового класса имеют значения по умолчанию:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
@dataclass
class Capital(Position):
country: str # Does NOT work
Этот код немедленно завершится аварийным сообщением TypeError с жалобой на то, что "аргумент 'страна', не являющийся аргументом по умолчанию, следует за аргументом по умолчанию". Проблема в том, что наше новое поле country не имеет значения по умолчанию, в то время как поля lon и lat имеют значения по умолчанию. Класс данных попытается написать метод .__init__() со следующей сигнатурой:
def __init__(name: str, lon: float = 0.0, lat: float = 0.0, country: str):
...
Однако это не правильный Python. Если параметр имеет значение по умолчанию, то все следующие параметры также должны иметь значение по умолчанию. Другими словами, если поле в базовом классе имеет значение по умолчанию, то все новые поля, добавляемые в подкласс, также должны иметь значения по умолчанию
Еще один момент, на который следует обратить внимание, - это порядок расположения полей в подклассе. Начиная с базового класса, поля упорядочиваются в том порядке, в котором они были определены впервые. Если поле переопределяется в подклассе, его порядок не меняется. Например, если вы определите Position и Capital следующим образом:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
@dataclass
class Capital(Position):
country: str = 'Unknown'
lat: float = 40.0
Тогда порядок полей в Capital по-прежнему будет name, lon, lat, country. Однако значение по умолчанию для lat будет 40.0.
>>> Capital('Madrid', country='Spain')
Capital(name='Madrid', lon=0.0, lat=40.0, country='Spain')
Оптимизация классов данных
В конце этого урока я хочу сказать несколько слов о слотах. Слоты можно использовать для того, чтобы классы работали быстрее и использовали меньше памяти. Классы данных не имеют явного синтаксиса для работы со слотами, но обычный способ создания слотов работает и для классов данных. (На самом деле это обычные классы!)
from dataclasses import dataclass
@dataclass
class SimplePosition:
name: str
lon: float
lat: float
@dataclass
class SlotPosition:
__slots__ = ['name', 'lon', 'lat']
name: str
lon: float
lat: float
По сути, слоты определяются с помощью .__slots__ для перечисления переменных класса. Переменные или атрибуты, не присутствующие в .__slots__, не могут быть определены. Кроме того, класс слотов не может иметь значений по умолчанию.
Выгода от добавления таких ограничений заключается в том, что можно провести определенную оптимизацию. Например, классы-слоты занимают меньше памяти, что можно оценить с помощью Pympler:
>>> from pympler import asizeof
>>> simple = SimplePosition('London', -0.1, 51.5)
>>> slot = SlotPosition('Madrid', -3.7, 40.4)
>>> asizeof.asizesof(simple, slot)
(440, 248)
Аналогично, классы слотов обычно быстрее в работе. В следующем примере измеряется скорость доступа к атрибутам для класса данных slots и обычного класса данных с помощью timeit из стандартной библиотеки.
>>> from timeit import timeit
>>> timeit('slot.name', setup="slot=SlotPosition('Oslo', 10.8, 59.9)", globals=globals())
0.05882283499886398
>>> timeit('simple.name', setup="simple=SimplePosition('Oslo', 10.8, 59.9)", globals=globals())
0.09207444800267695
В данном конкретном примере класс слотов работает примерно на 35 % быстрее.
Заключение и дальнейшее чтение
Классы данных - одна из новых возможностей Python 3.7. С помощью классов данных вам не придется писать шаблонный код, чтобы получить правильную инициализацию, представление и сравнения для ваших объектов.
Вы увидели, как определять собственные классы данных, а также:
- Как добавить значения по умолчанию в поля класса данных
- Как настроить упорядочивание объектов класса данных
- Как работать с неизменяемыми классами данных
- Как работает наследование для классов данных
Если вы хотите погрузиться во все детали классов данных, посмотрите PEP 557, а также обсуждения в оригинальном GitHub repo.
Кроме того, на PyCon 2018 Раймонд Хеттингер выступил с докладом Dataclasses: The code generator to end all code generators стоит посмотреть.
Вернуться на верх